Web scraping has become a vital tool across industries, powering competitive analysis, market research, price tracking, and more. But as scraping becomes more widespread, so too have the countermeasures designed to block it. Websites are increasingly equipped with anti-bot systems that monitor incoming traffic and filter out anything that looks automated or suspicious.
This creates a growing challenge for data professionals: how do you reliably extract information without being detected or blocked? In this article, we’ll explore how anti-detect browsers like DICloak play a key role in this strategy, how they integrate with proxy solutions like those offered by Infatica, and what best practices help keep your operations compliant and effective.
Anti-Bot Defenses Are Evolving
Web scraping has become a critical part of digital operations – from price aggregation to market intelligence – but as scraping techniques improve, so do the defenses designed to stop them. Modern websites deploy a growing arsenal of anti-bot mechanisms that can easily detect and block traditional scraping tools.
These defenses go far beyond basic IP rate limiting. Sophisticated systems analyze browser fingerprints, monitor mouse movement patterns, and track resource loading behaviors to identify automated activity. Headless browsers, even those based on real user engines like Chromium or Firefox, often carry tell-tale signs of automation – such as missing plugins, unusual window sizes, or predictable user-agent strings.

Fingerprinting plays a particularly crucial role: websites can collect dozens of data points (e.g., canvas rendering, WebGL, timezone, language, OS details) to build a unique browser signature. When that signature repeats across multiple requests, it raises suspicion – and usually results in a block.
In this environment, traditional scraping tools fall short. Avoiding detection requires not just rotating IP addresses, but also rotating identities – down to the level of hardware and software characteristics. It's no longer enough to just send HTTP requests or use a headless browser; successful scraping requires a full-stack strategy that reduces your visibility as a bot.
The Role of Anti-Detect Browsers in Web Scraping
That’s where anti-detect browsers like DICloak enter the picture: They’re able to mimic genuine users across all layers of interaction. That includes using clean, rotating IP addresses, realistic browser fingerprints, and human-like behavior patterns.
Anti-detect browsers are purpose-built tools that help users appear as genuine, unique visitors when accessing websites. For web scraping professionals, they serve as a powerful alternative to traditional automation tools by offering granular control over browser fingerprints, network parameters, and behavioral signals.
Unlike standard headless browsers, which often use default or blank configurations, anti-detect browsers allow users to manipulate and randomize a wide range of attributes. These include the user-agent string, screen resolution, system fonts, time zone, CPU and GPU details, and even WebGL or canvas fingerprinting data. By doing so, they create convincing, non-repeating browser profiles that mirror real users with high fidelity.
Many anti-detect browsers also support persistent profiles and session storage, making them ideal for scraping tasks that require login credentials, cookie management, or multi-step navigation. Combined with automation tools like Puppeteer or Selenium (via plugins or APIs), anti-detect browsers enable scalable, stealthy scraping at both small and enterprise levels.
Combining Anti-Detect Browsers with Proxies
Even the most sophisticated browser fingerprint can’t bypass anti-bot systems alone – without the right network infrastructure, scraping attempts will still raise red flags. That’s why pairing like DICloak with high-quality proxies is essential for any serious web scraping operation. But what are proxies?
Proxies serve as the first line of defense by routing traffic through alternate IP addresses, helping to avoid rate limits and IP bans. However, not all proxies are created equal: websites can often detect and block low-quality or poorly configured proxies, especially those with suspicious patterns or shared IP reputations.
When used together, proxies and anti-detect browsers form a stealthy, adaptive duo. While the anti-detect browser handles the browser-side fingerprint – simulating real user behavior – the proxy handles the network-side identity, allowing users to appear as if they're connecting from different countries, regions, or even mobile networks.
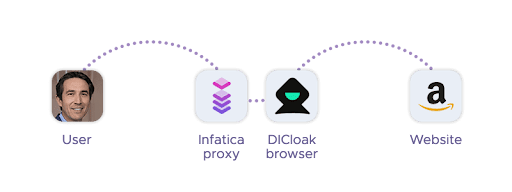
This combination is particularly powerful for use cases like localized scraping, account creation, or accessing geo-restricted content. For example, rotating residential proxies can be matched with unique browser profiles to simulate thousands of genuine users from different households.
At Infatica, we offer a full suite of proxy solutions – including residential, datacenter, and mobile proxies – that integrate seamlessly with anti-detect browsers. Designed for performance and stability, our proxies help scraping professionals avoid blocks, reduce downtime, and ensure reliable data access at scale.
Real-World Applications
The combination of anti-detect browsers and high-quality proxies unlocks a wide range of powerful web scraping use cases across industries. Let’s take a closer look at common real-world scenarios where this tech pairing proves invaluable:
Price Monitoring Across Regions
E-commerce companies and analysts rely on anti-detect browsers to scrape prices from online marketplaces without triggering geo-restrictions or IP bans. By pairing rotating proxies with unique browser profiles, scrapers can simulate local users in multiple countries and compare regional pricing or discounts.
Travel Aggregation and Fare Intelligence
Flight and hotel booking platforms often serve different content depending on the user’s location and browser configuration. Using an anti-detect browser, scrapers can vary fingerprints while proxies simulate requests from different cities or countries – helping gather accurate, location-specific travel data.
SERP Scraping and SEO Monitoring
Search engines personalize results based on location, device, and past behavior. Scraping SERPs without detection requires a convincing browser identity and reliable proxy routing. Anti-detect browsers allow scrapers to emulate desktop or mobile users, while proxies unlock local results from global regions.
Lead Generation and Public Data Collection
B2B marketers use scraping to gather contact details, reviews, and listings from platforms like directories or job boards. Anti-detect setups allow persistent, authenticated sessions – even on login-gated sites – while proxies ensure requests don’t originate from the same IP.
Ad Verification and Fraud Detection
Brands and ad tech companies use scraping to verify that ads appear correctly across geos and devices. Combining anti-detect profiles with location-specific proxies enables a realistic preview of how users experience campaigns – and helps detect hidden redirects or click fraud.
A Unified Approach to Stealth Scraping
Modern anti-bot systems don’t rely on a single signal – they analyze everything from your IP address to your browser fingerprint and user behavior. To reliably bypass these defenses, scraping operations must apply stealth at every level:
- Network identity: Use rotating, high-quality proxies to avoid detection and access geo-restricted data. Infatica provides ethically sourced residential, mobile, and datacenter proxies – built for scraping at scale. Try them with promo code DICLOAK10 for an exclusive discount.
- Browser fingerprint: Anti-detect browsers like DICloak are essential for evading fingerprint-based detection, letting you emulate real, unique users with precision.
- User behavior: Combine your anti-detect setup with automation frameworks (e.g., Puppeteer, Selenium) enhanced by human-like actions – randomized delays, scrolling, and navigation patterns.
Together, these components form a reliable foundation for scalable, low-risk web scraping – enabling teams to extract critical data without being blocked.
 Web Proxy Tools
Web Proxy Tools Free Tools
Free Tools Cookie Plugin
Cookie Plugin UA Generator
UA Generator MAC Address Generator
MAC Address Generator IP Generator
IP Generator IP Address List
IP Address List 2FA Code Generator
2FA Code Generator World Clock
World Clock Anonymous Check
Anonymous Check WebRTC Leak Test
WebRTC Leak Test UUID Generator
UUID Generator Free Web Proxy Site
Free Web Proxy Site Proxy Checker
Proxy Checker FB Ad Checker
FB Ad Checker AI Web Scraping
AI Web Scraping Free SMM Tools
Free SMM Tools Twitter Shadowban Checker
Twitter Shadowban Checker Instagram Name Checker
Instagram Name Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator






