Have you ever wanted to gather information from Reddit for research, market analysis, or content creation? You're not alone! As someone who's spent years working with data extraction tools, I've discovered that Reddit is a goldmine of insights—if you know how to access it properly.
In this comprehensive guide, I'll walk you through everything you need to know about Reddit scrapers: what they are, how they work, which tools are best for beginners and pros alike, and how to use them ethically and legally. I'll even share some personal experiences and tips I've learned along the way.
What Can You Scrape from Reddit?
Before diving into the tools and techniques, let's explore what kind of data you can actually extract from Reddit. This platform offers a wealth of information across thousands of communities (subreddits), making it invaluable for researchers, marketers, and content creators.

Posts and Threads
The most common targets for Reddit scraping are posts and their associated threads. When I first started scraping Reddit for a market research project, I was amazed at how much consumer insight was hiding in plain sight. You can extract:
•Post titles and content
•Upvote and downvote counts
•Posting dates and times
•Comment threads and nested replies
•Awards and special recognitions
For example, when I scraped r/TechSupport for a client, we discovered recurring issues with a product that weren't showing up in their customer service tickets. This insight helped them fix a problem before it became a PR nightmare!
Subreddit Information
Each subreddit is a community with its own culture and focus. Scraping subreddit data can reveal:
•Subscriber counts and growth trends
•Community rules and guidelines
•Posting patterns and peak activity times
•Moderator information
•Related subreddits
I once used this approach to help a gaming company identify which subreddits would be most receptive to their new release, based on community size and engagement patterns with similar games.
User Profiles
User data can provide valuable insights into behavior patterns and preferences:
•Posting and comment history
•Karma scores
•Account age
•Active communities
•Award history
Remember that while this data is publicly available, it's important to respect privacy and anonymize any data you collect for analysis or reporting.
Top Reddit Scraper Tools Compared
After testing dozens of tools over the years, I've narrowed down the options to the most effective Reddit scrapers available in 2025. Let's compare them based on ease of use, features, and cost.
Pros:
•Free and open-source
•Comprehensive access to Reddit's API
•Excellent documentation and community support
•Handles rate limiting automatically
•Highly customizable for specific needs
Cons:
•Requires Python knowledge
•Setup process involves creating a Reddit developer account
•Limited by Reddit API restrictions
Best for: Developers and data scientists who are comfortable with code and need customizable solutions.
I've used PRAW for several large-scale research projects, and its reliability is unmatched. The learning curve was worth it for the control it gave me over exactly what data to extract and how to process it.
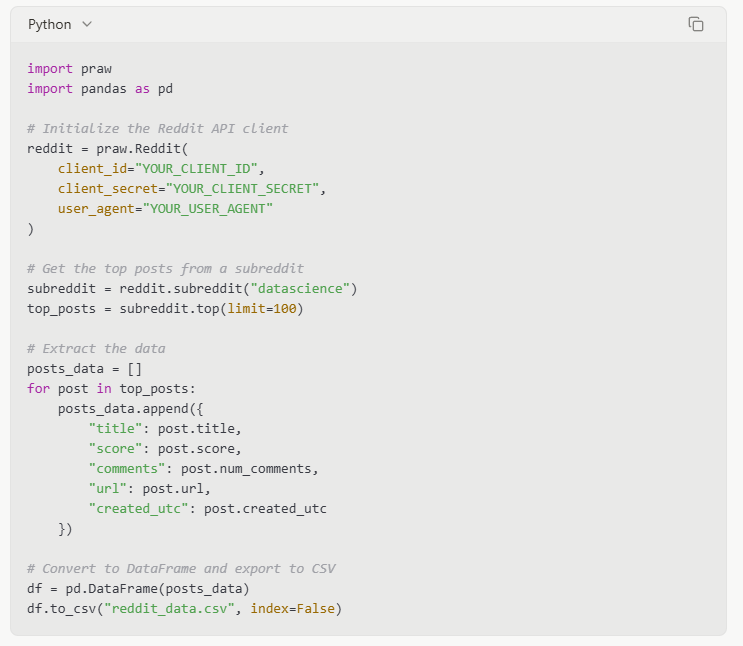
Code example:
Pros:
•No coding required—fully visual interface
•Handles dynamic content loading automatically
•Cloud-based execution options
•Scheduled scraping at regular intervals
•Multiple export formats (CSV, Excel, JSON)
Cons:
•Free version has limitations on number of records
•Paid plans start at $75/month
•Learning curve for complex scraping tasks
•May require adjustments as Reddit's layout changes
Best for: Business users and researchers without programming experience who need regular data extraction.
Octoparse saved me when I needed to deliver a Reddit analysis project but didn't have time to write custom code. The visual interface made it easy to select exactly what data I wanted, and the cloud execution meant I could set it and forget it.
Apify Reddit Scraper
Pros:
•Pre-built solution specifically for Reddit
•No authentication required
•User-friendly interface with minimal setup
•Handles pagination and comment threading
•Robust export options
Cons:
•Usage-based pricing can add up for large projects
•Less customizable than code-based solutions
•Occasional delays with very new content
Best for: Marketing professionals and researchers who need quick results without technical setup.
When working with a marketing team that needed Reddit data ASAP, Apify was my go-to. We were able to extract sentiment data from product-related subreddits in under an hour, which would have taken days to code from scratch.
Pros:
•Specialized for Reddit's structure
•No login required for basic scraping
•Batch processing capabilities
•Good balance of usability and features
•Affordable pricing tiers
Cons:
•Newer tool with smaller community
•Documentation could be more comprehensive
•Some advanced features require paid subscription
Best for: Small businesses and individual researchers who need regular Reddit data without technical complexity.
I started using Scrupp last year for a personal project tracking gaming trends, and I've been impressed with how it handles Reddit's nested comment structure—something many scrapers struggle with.

Pros:
•Free and open-source
•Handles JavaScript-rendered content
•Can simulate user interactions
•Works well with Reddit's infinite scrolling
•Highly customizable
Cons:
•Requires programming knowledge
•More resource-intensive than API-based solutions
•Needs regular maintenance as websites change
Best for: Developers who need to scrape content that's not easily accessible through the API.
When I needed to scrape a subreddit that used custom widgets and infinite scrolling, Selenium was the only tool that could reliably capture everything. It's more work to set up, but it can handle almost any scraping challenge.
No-Code Solutions for Reddit Scraping
Not everyone has the time or technical skills to write code for data extraction. Fortunately, several no-code tools have emerged that make Reddit scraping accessible to everyone.
Octoparse Step-by-Step Guide
Let me walk you through how I used Octoparse to scrape a subreddit without writing a single line of code:
1.Download and install Octoparse from their official website
2.Create a new task by clicking the "+" button
3.Enter the Reddit URL you want to scrape (e.g., https://www.reddit.com/r/datascience/)
4.Use the point-and-click interface to select the elements you want to extract:
•Click on a post title to select all titles
•Click on upvote counts to select all counts
•Click on usernames to select all authors
5.Configure pagination by telling Octoparse to click the "Next" button or scroll down
6.Run the task either on your local machine or in the cloud
7.Export the data as CSV, Excel, or JSON
The first time I used this approach, I was able to extract 500+ posts from r/TechGadgets in about 20 minutes, complete with titles, scores, and comment counts—all without writing code!
Other No-Code Options
If Octoparse doesn't meet your needs, consider these alternatives:
•ParseHub: Great for complex websites with a generous free tier
•Import.io: Enterprise-focused with powerful transformation tools
•Webscraper.io: Browser extension for quick, simple scraping tasks
I've found that each has its strengths, but Octoparse offers the best balance of power and usability for Reddit specifically.
Is It Legal to Scrape Reddit?
This is perhaps the most common question I hear, and the answer isn't black and white. Based on my research and experience, here's what you need to know:
The Legal Landscape
Web scraping itself is not illegal, but how you do it and what you do with the data matters enormously. When it comes to Reddit:
1.Reddit's Terms of Service allow for "personal, non-commercial use" of their services
2.The Computer Fraud and Abuse Act (CFAA) has been interpreted differently in various court cases regarding web scraping
3.The hiQ Labs v. LinkedIn case established some precedent that scraping publicly available data may be legal
In my experience, most legal issues arise not from the act of scraping itself, but from how the data is used afterward.
Ethical Considerations
Beyond legality, there are important ethical considerations:
•Respect robots.txt: Reddit's robots.txt file provides guidelines for automated access
•Rate limiting: Excessive requests can burden Reddit's servers
•Privacy concerns: Even though data is public, users may not expect it to be collected en masse
•Attribution: If publishing insights, credit Reddit and its users appropriately
I always advise clients to anonymize data when reporting findings and to be transparent about data collection methods.
Best Practices for Legal Compliance
To stay on the safe side:
1.Read and respect Reddit's Terms of Service
2.Implement rate limiting in your scraping tools
3.Don't scrape private subreddits or content requiring login
4.Anonymize user data in your analysis and reporting
5.Use the official API when possible
6.Consider the purpose of your data collection
I once consulted for a company that wanted to scrape Reddit for product reviews. We decided to use the official API with proper attribution, and even reached out to moderators of relevant subreddits to ensure transparency. This approach not only kept us legally compliant but also built goodwill with the communities we were studying.
Bypassing Anti-Scraping Measures
Reddit, like many platforms, implements measures to prevent excessive scraping. Here's how to navigate these challenges responsibly:
Common Anti-Scraping Mechanisms
In my years of web scraping, I've encountered several anti-scraping techniques on Reddit:
1.Rate limiting: Restricting the number of requests from a single IP
2.CAPTCHAs: Challenging automated tools with verification tests
3.IP blocking: Temporarily or permanently blocking suspicious IPs
4.User-Agent detection: Identifying and blocking scraper tools
5.Dynamic content loading: Making content harder to access programmatically
Responsible Bypassing Strategies
While I don't advocate for aggressive circumvention, these approaches can help you scrape responsibly:
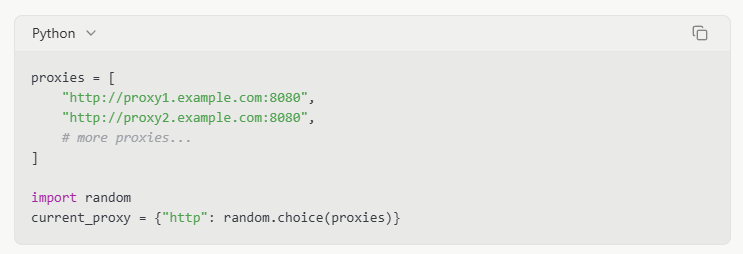
Proxy Rotation
Using multiple IP addresses through proxies can help distribute requests and avoid triggering rate limits. I typically use a pool of 5-10 proxies for moderate scraping projects, rotating between them for each request.
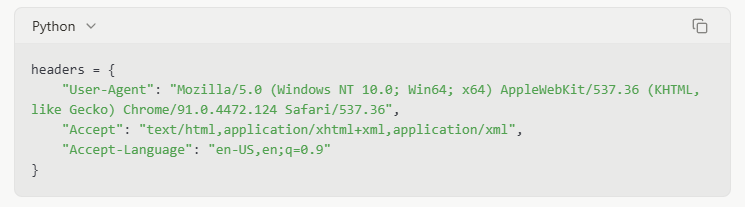
Request Headers Management
Setting realistic browser headers can help your scraper blend in with normal traffic:
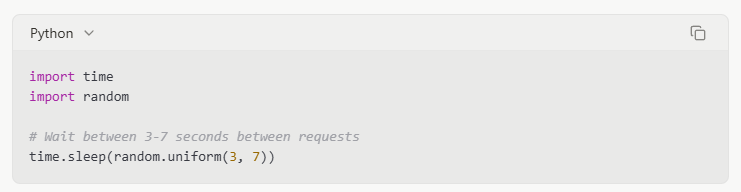
Respectful Timing
Adding delays between requests mimics human browsing patterns and reduces server load:
Session Management
Maintaining cookies and session information can make requests appear more legitimate:
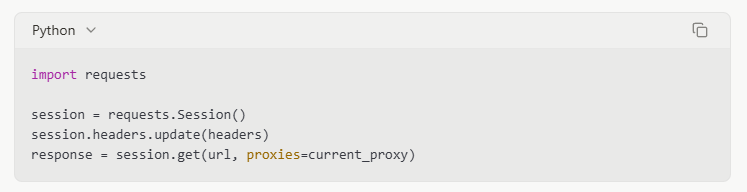
Exporting and Using Reddit Data
Once you've successfully scraped Reddit, the next step is organizing and exporting that data in a usable format.
CSV Export
CSV (Comma-Separated Values) is perfect for tabular data and compatibility with spreadsheet software:

I prefer CSV for most projects because it's easy to open in Excel or Google Sheets for quick analysis or sharing with non-technical team members.
JSON Export
JSON (JavaScript Object Notation) is better for preserving nested data structures like comment threads:
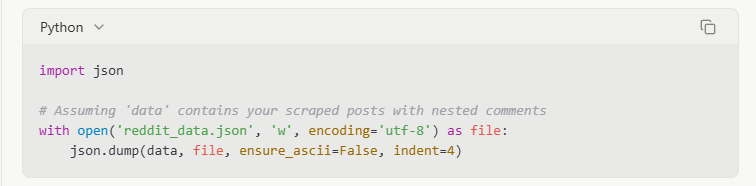
When I scraped a discussion-heavy subreddit, JSON was essential for maintaining the parent-child relationships in comment threads, which would have been flattened in a CSV format.
Pandas DataFrames
For data analysis in Python, converting to a Pandas DataFrame offers powerful processing capabilities:

I've found this approach particularly useful for projects requiring data visualization or statistical analysis, as Pandas integrates well with tools like Matplotlib and Seaborn.
Advanced Reddit Scraping with DICloak's RPA Automation
While the tools we've discussed so far work well for many scenarios, there are situations where you need more sophisticated solutions—especially when dealing with Reddit's increasingly complex anti-bot measures or when managing multiple scraping projects simultaneously.
This is where DICloak'Antidetect Browser with RPA (Robotic Process Automation) capabilities comes into play. I discovered this tool last year, and it's completely changed my approach to complex scraping projects.
What Makes DICloak Different for Reddit Scraping
DICloak is primarily known as an antidetect browser for managing multiple accounts, but its RPA functionality makes it exceptionally powerful for Reddit scraping:
1.Browser Fingerprint Management: DICloak creates unique, consistent browser fingerprints that help avoid Reddit's sophisticated detection systems
2.Automated Workflows: The RPA feature lets you create custom scraping workflows that can run on schedule
3.Multi-Account Support: Perfect if you need to access different Reddit accounts for various scraping projects
4.Proxy Integration: Seamlessly works with proxies to distribute requests
5.Visual Workflow Builder: Create scraping sequences without coding
If you're interested in setting up custom RPA workflows for Reddit scraping, you can contact DICloak's customer support team to discuss your specific requirements. They offer personalized assistance in creating efficient scraping solutions that respect both Reddit's technical limitations and terms of service.
Conclusion
Reddit scraping offers incredible opportunities for researchers, marketers, and data enthusiasts to tap into one of the internet's richest sources of user-generated content and discussions. Throughout this guide, we've explored the various tools and techniques available, from code-based solutions like PRAW to no-code options like Octoparse, as well as advanced approaches using DICloak's RPA automation.
The key takeaways from my years of experience with Reddit scraping are:
1.Choose the right tool for your skill level and needs
2.Always scrape responsibly and ethically
3.Be mindful of legal considerations and Reddit's terms of service
4.Implement proper rate limiting and proxy rotation
5.Process and export your data in formats that suit your analysis goals
Whether you're conducting academic research, gathering market insights, or tracking trends, the approaches outlined in this guide will help you extract valuable data from Reddit effectively and responsibly.
Remember that the landscape of web scraping is constantly evolving, with platforms updating their structures and protections regularly. Stay informed about changes to Reddit's platform and adjust your scraping strategies accordingly.
Have you tried any of these Reddit scraping methods? I'd love to hear about your experiences and any tips you might have discovered along the way!
Frequently Asked Questions
Is it against Reddit's rules to scrape their website?
Reddit's User Agreement doesn't explicitly forbid scraping, but it does limit automated requests and requires compliance with robots.txt. For large-scale scraping, using the official API is recommended when possible.
How can I avoid getting blocked while scraping Reddit?
Implement respectful scraping practices: use delays between requests, rotate IP addresses through proxies, set realistic user agents, and limit your scraping volume and frequency.
What's the difference between using Reddit's API and web scraping?
The API provides structured data with explicit permission but has rate limits and requires authentication. Web scraping can access content not available through the API but carries more legal and ethical considerations.
Can I sell the data I scrape from Reddit?
Selling raw scraped data from Reddit is generally not recommended and may violate their terms of service. However, selling insights and analysis derived from that data may be acceptable in some contexts.
How do I scrape Reddit comments that are loaded dynamically?
For dynamically loaded comments, tools like Selenium or DICloak's RPA automation can simulate scrolling and clicking "load more comments" buttons to access nested or paginated content.
What's the best format to store Reddit data for analysis?
For simple tabular data, CSV works well. For preserving nested structures like comment threads, JSON is better. For immediate analysis in Python, Pandas DataFrames offer the most flexibility.
 Web Proxy Tools
Web Proxy Tools Free Tools
Free Tools Cookie Plugin
Cookie Plugin UA Generator
UA Generator MAC Address Generator
MAC Address Generator IP Generator
IP Generator IP Address List
IP Address List 2FA Code Generator
2FA Code Generator World Clock
World Clock Anonymous Check
Anonymous Check WebRTC Leak Test
WebRTC Leak Test UUID Generator
UUID Generator Free Web Proxy Site
Free Web Proxy Site Proxy Checker
Proxy Checker FB Ad Checker
FB Ad Checker AI Web Scraping
AI Web Scraping Free SMM Tools
Free SMM Tools Twitter Shadowban Checker
Twitter Shadowban Checker Instagram Name Checker
Instagram Name Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator LinkedIn Headline Generator
LinkedIn Headline Generator Social Media Image Resizer
Social Media Image Resizer






