Bạn đã bao giờ muốn thu thập thông tin từ Reddit cho nghiên cứu, phân tích thị trường hoặc tạo nội dung chưa? Bạn không đơn độc! Là một người đã dành nhiều năm làm việc với các công cụ trích xuất dữ liệu, tôi đã phát hiện ra rằng Reddit là một kho tàng thông tin—nếu bạn biết cách truy cập đúng cách.
Trong hướng dẫn toàn diện này, tôi sẽ hướng dẫn bạn mọi thứ bạn cần biết về các công cụ trích xuất dữ liệu từ Reddit: chúng là gì, cách chúng hoạt động, những công cụ nào là tốt nhất cho cả người mới bắt đầu và chuyên gia, và cách sử dụng chúng một cách đạo đức và hợp pháp. Tôi thậm chí sẽ chia sẻ một số trải nghiệm cá nhân và mẹo mà tôi đã học được trong quá trình này.
Bạn có thể trích xuất gì từ Reddit?
Trước khi đi vào các công cụ và kỹ thuật, hãy cùng khám phá loại dữ liệu nào bạn thực sự có thể trích xuất từ Reddit. Nền tảng này cung cấp một kho tàng thông tin trên hàng ngàn cộng đồng (subreddit), khiến nó trở nên vô giá cho các nhà nghiên cứu, nhà tiếp thị và người tạo nội dung.

Bài viết và Chủ đề
Mục tiêu phổ biến nhất cho việc trích xuất dữ liệu từ Reddit là các bài viết và các chủ đề liên quan. Khi tôi lần đầu tiên bắt đầu trích xuất dữ liệu từ Reddit cho một dự án nghiên cứu thị trường, tôi đã rất ngạc nhiên khi thấy có bao nhiêu thông tin về người tiêu dùng đang ẩn hiện ngay trước mắt. Bạn có thể trích xuất:
•Tiêu đề và nội dung bài viết
•Số lượng upvote và downvote
•Ngày và giờ đăng bài
•Các chủ đề bình luận và các phản hồi lồng ghép
•Giải thưởng và sự công nhận đặc biệt
Ví dụ, khi tôi trích xuất dữ liệu từ r/TechSupport cho một khách hàng, chúng tôi đã phát hiện ra những vấn đề lặp đi lặp lại với một sản phẩm mà không xuất hiện trong các phiếu dịch vụ khách hàng của họ. Thông tin này đã giúp họ khắc phục một vấn đề trước khi nó trở thành một cơn ác mộng PR!
Thông tin Subreddit
Mỗi subreddit là một cộng đồng với văn hóa và trọng tâm riêng. Việc trích xuất dữ liệu từ subreddit có thể tiết lộ:
•Số lượng người đăng ký và xu hướng tăng trưởng
•Quy tắc và hướng dẫn của cộng đồng
•Mô hình đăng bài và thời gian hoạt động cao điểm
•Thông tin về người điều hành
•Các subreddit liên quan
Tôi đã từng sử dụng cách tiếp cận này để giúp một công ty game xác định các subreddit nào sẽ tiếp nhận tốt nhất sản phẩm mới của họ, dựa trên kích thước cộng đồng và các mô hình tương tác với các trò chơi tương tự.
Hồ sơ người dùng
Dữ liệu người dùng có thể cung cấp những hiểu biết quý giá về các mô hình hành vi và sở thích:
•Lịch sử đăng bài và bình luận
•Điểm karma
•Tuổi tài khoản
•Cộng đồng hoạt động
•Lịch sử giải thưởng
Hãy nhớ rằng mặc dù dữ liệu này có sẵn công khai, nhưng điều quan trọng là tôn trọng quyền riêng tư và ẩn danh bất kỳ dữ liệu nào bạn thu thập để phân tích hoặc báo cáo.
Các công cụ thu thập dữ liệu Reddit hàng đầu được so sánh
Sau khi thử nghiệm hàng chục công cụ trong nhiều năm, tôi đã thu hẹp các lựa chọn xuống những công cụ thu thập dữ liệu Reddit hiệu quả nhất có sẵn vào năm 2025. Hãy so sánh chúng dựa trên tính dễ sử dụng, tính năng và chi phí.
Ưu điểm:
•Miễn phí và mã nguồn mở
•Truy cập toàn diện vào API của Reddit
•Tài liệu xuất sắc và hỗ trợ cộng đồng
•Tự động xử lý giới hạn tốc độ
•Có thể tùy chỉnh cao cho các nhu cầu cụ thể
Nhược điểm:
•Cần có kiến thức về Python
•Quá trình thiết lập bao gồm việc tạo tài khoản nhà phát triển Reddit
•Bị giới hạn bởi các quy định của API Reddit
Phù hợp nhất cho: Các nhà phát triển và nhà khoa học dữ liệu có kinh nghiệm với mã và cần các giải pháp tùy chỉnh.
Tôi đã sử dụng PRAW cho một số dự án nghiên cứu quy mô lớn, và độ tin cậy của nó là không thể sánh kịp. Đường cong học tập là xứng đáng với quyền kiểm soát mà nó mang lại cho tôi về chính xác dữ liệu nào cần trích xuất và cách xử lý nó.
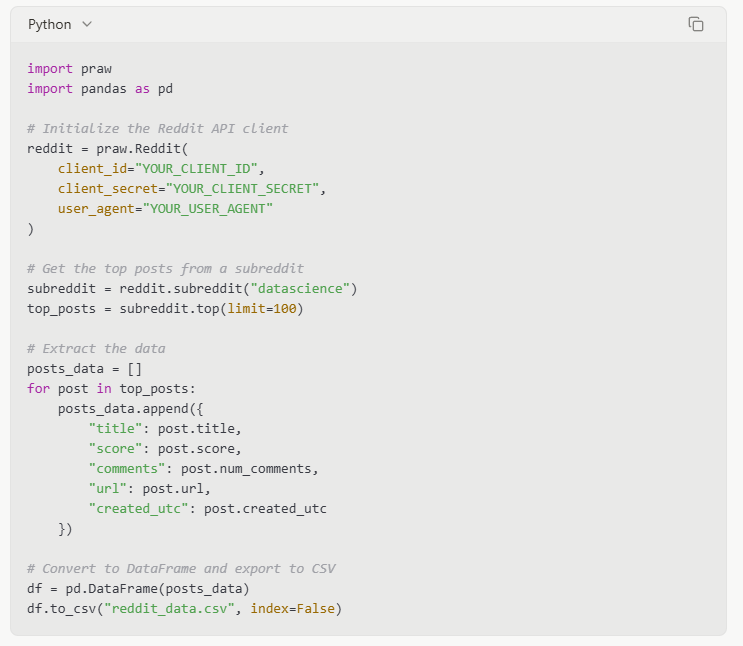
Ví dụ mã:
•Không cần lập trình—giao diện hoàn toàn trực quan
•Tự động xử lý tải nội dung động
•Tùy chọn thực thi dựa trên đám mây
•Lập lịch thu thập dữ liệu theo khoảng thời gian đều đặn
•Nhiều định dạng xuất (CSV, Excel, JSON)
•Phiên bản miễn phí có giới hạn về số lượng bản ghi
•Các gói trả phí bắt đầu từ 75 đô la/tháng
•Đường cong học tập cho các tác vụ thu thập dữ liệu phức tạp
•Có thể cần điều chỉnh khi bố cục của Reddit thay đổi
Tốt nhất cho: Người dùng doanh nghiệp và nhà nghiên cứu không có kinh nghiệm lập trình cần thu thập dữ liệu thường xuyên.
Octoparse đã cứu tôi khi tôi cần hoàn thành một dự án phân tích Reddit nhưng không có thời gian để viết mã tùy chỉnh. Giao diện trực quan giúp tôi dễ dàng chọn chính xác dữ liệu mà tôi muốn, và việc thực thi trên đám mây có nghĩa là tôi có thể thiết lập và quên đi.
Apify Reddit Scraper
•Giải pháp đã được xây dựng sẵn dành riêng cho Reddit
•Không cần xác thực
•Giao diện thân thiện với người dùng với thiết lập tối thiểu
•Xử lý phân trang và luồng bình luận
•Tùy chọn xuất mạnh mẽ
•Giá cả dựa trên mức sử dụng có thể tăng lên cho các dự án lớn
•Ít tùy chỉnh hơn so với các giải pháp dựa trên mã
•Thỉnh thoảng có độ trễ với nội dung rất mới
Tốt nhất cho: Các chuyên gia marketing và nhà nghiên cứu cần kết quả nhanh chóng mà không cần thiết lập kỹ thuật.
Khi làm việc với một nhóm marketing cần dữ liệu Reddit ngay lập tức, Apify là lựa chọn của tôi. Chúng tôi đã có thể thu thập dữ liệu cảm xúc từ các subreddit liên quan đến sản phẩm trong chưa đầy một giờ, điều này sẽ mất vài ngày để lập trình từ đầu.
• Chuyên biệt cho cấu trúc của Reddit
• Không cần đăng nhập cho việc thu thập dữ liệu cơ bản
• Khả năng xử lý theo lô
• Cân bằng tốt giữa tính khả dụng và các tính năng
• Mức giá phải chăng
• Công cụ mới hơn với cộng đồng nhỏ hơn
• Tài liệu có thể đầy đủ hơn
• Một số tính năng nâng cao yêu cầu đăng ký trả phí
Phù hợp nhất cho: Các doanh nghiệp nhỏ và các nhà nghiên cứu cá nhân cần dữ liệu Reddit thường xuyên mà không gặp phức tạp kỹ thuật.
Tôi đã bắt đầu sử dụng Scrupp năm ngoái cho một dự án cá nhân theo dõi xu hướng trò chơi, và tôi đã ấn tượng với cách nó xử lý cấu trúc bình luận lồng ghép của Reddit—điều mà nhiều công cụ thu thập dữ liệu gặp khó khăn.

• Xử lý nội dung được render bằng JavaScript
• Có thể mô phỏng tương tác của người dùng
• Hoạt động tốt với cuộn vô hạn của Reddit
• Rất tùy biến
• Cần kiến thức lập trình
• Tốn tài nguyên hơn so với các giải pháp dựa trên API
• Cần bảo trì thường xuyên khi các trang web thay đổi
Phù hợp nhất cho: Các nhà phát triển cần thu thập nội dung không dễ dàng truy cập qua API.
Khi tôi cần thu thập dữ liệu từ một subreddit sử dụng các widget tùy chỉnh và cuộn vô hạn, Selenium là công cụ duy nhất có thể đáng tin cậy ghi lại mọi thứ. Nó cần nhiều công sức để thiết lập, nhưng có thể xử lý hầu hết mọi thách thức thu thập dữ liệu.
Các giải pháp không cần mã cho việc thu thập dữ liệu Reddit
Không phải ai cũng có thời gian hoặc kỹ năng kỹ thuật để viết mã cho việc trích xuất dữ liệu. May mắn thay, đã có một số công cụ không cần mã xuất hiện giúp việc thu thập dữ liệu từ Reddit trở nên dễ dàng cho mọi người.
Hướng Dẫn Bước-Đến-Bước Với Octoparse
Hãy để tôi hướng dẫn bạn cách tôi đã sử dụng Octoparse để thu thập dữ liệu từ một subreddit mà không cần viết một dòng mã nào:
1.Tải xuống và cài đặt Octoparse từ trang web chính thức của họ
2.Tạo một nhiệm vụ mới bằng cách nhấp vào nút "+"
3.Nhập URL Reddit mà bạn muốn thu thập dữ liệu (ví dụ: https://www.reddit.com/r/datascience/)
4.Sử dụng giao diện nhấp và chọn để chọn các phần tử bạn muốn trích xuất:
•Nhấp vào tiêu đề bài viết để chọn tất cả các tiêu đề
•Nhấp vào số lượng upvote để chọn tất cả các số lượng
•Nhấp vào tên người dùng để chọn tất cả các tác giả
5.Cấu hình phân trang bằng cách yêu cầu Octoparse nhấp vào nút "Tiếp theo" hoặc cuộn xuống
6.Chạy nhiệm vụ trên máy tính cục bộ của bạn hoặc trên đám mây
7.Xuất dữ liệu dưới dạng CSV, Excel hoặc JSON
Lần đầu tiên tôi sử dụng phương pháp này, tôi đã có thể trích xuất hơn 500 bài viết từ r/TechGadgets trong khoảng 20 phút, với đầy đủ tiêu đề, điểm số và số lượng bình luận—tất cả mà không cần viết mã!
Các Tùy Chọn Không Cần Mã Khác
Nếu Octoparse không đáp ứng nhu cầu của bạn, hãy xem xét các lựa chọn thay thế sau:
•ParseHub: Tuyệt vời cho các trang web phức tạp với gói miễn phí hào phóng
•Import.io: Tập trung vào doanh nghiệp với các công cụ chuyển đổi mạnh mẽ
•Webscraper.io: Tiện ích mở rộng trình duyệt cho các nhiệm vụ thu thập dữ liệu nhanh chóng, đơn giản
Tôi nhận thấy rằng mỗi công cụ đều có những điểm mạnh riêng, nhưng Octoparse cung cấp sự cân bằng tốt nhất giữa sức mạnh và tính khả dụng cho Reddit cụ thể.
Có Hợp Pháp Khi Thu Thập Dữ Liệu Từ Reddit Không?
Đây có lẽ là câu hỏi phổ biến nhất mà tôi nghe, và câu trả lời không phải là trắng đen. Dựa trên nghiên cứu và kinh nghiệm của tôi, đây là những gì bạn cần biết:
Cảnh Quan Pháp Lý
Việc thu thập dữ liệu từ web bản thân nó không phải là bất hợp pháp, nhưng cách bạn thực hiện và những gì bạn làm với dữ liệu rất quan trọng. Khi nói đến Reddit:
1. Điều khoản dịch vụ của Reddit cho phép "sử dụng cá nhân, phi thương mại" các dịch vụ của họ
2. Đạo luật gian lận và lạm dụng máy tính (CFAA) đã được diễn giải khác nhau trong các vụ án khác nhau liên quan đến việc thu thập dữ liệu từ web
3. Vụ hiQ Labs kiện LinkedIn đã thiết lập một số tiền lệ rằng việc thu thập dữ liệu công khai có thể hợp pháp
Trong kinh nghiệm của tôi, hầu hết các vấn đề pháp lý phát sinh không phải từ hành động thu thập dữ liệu mà từ cách dữ liệu được sử dụng sau đó.
Các cân nhắc về đạo đức
Ngoài tính hợp pháp, còn có những cân nhắc đạo đức quan trọng:
• Tôn trọng robots.txt: Tệp robots.txt của Reddit cung cấp hướng dẫn cho việc truy cập tự động
• Giới hạn tần suất: Các yêu cầu quá mức có thể gây gánh nặng cho máy chủ của Reddit
• Quan ngại về quyền riêng tư: Mặc dù dữ liệu là công khai, người dùng có thể không mong đợi nó bị thu thập hàng loạt
• Ghi nhận: Nếu công bố những hiểu biết, hãy ghi nhận Reddit và người dùng của nó một cách thích hợp
Tôi luôn khuyên khách hàng nên ẩn danh dữ liệu khi báo cáo kết quả và minh bạch về các phương pháp thu thập dữ liệu.
Các thực tiễn tốt nhất để tuân thủ pháp luật
Để ở trong tình trạng an toàn:
1. Đọc và tôn trọng Điều khoản dịch vụ của Reddit
2. Thực hiện giới hạn tần suất trong các công cụ thu thập dữ liệu của bạn
3. Không thu thập dữ liệu từ các subreddit riêng tư hoặc nội dung yêu cầu đăng nhập
4. Ẩn danh dữ liệu người dùng trong phân tích và báo cáo của bạn
5. Sử dụng API chính thức khi có thể
6. Cân nhắc mục đích của việc thu thập dữ liệu của bạn
Tôi đã từng tư vấn cho một công ty muốn thu thập dữ liệu từ Reddit để lấy đánh giá sản phẩm. Chúng tôi đã quyết định sử dụng API chính thức với ghi nhận thích hợp, và thậm chí đã liên hệ với các quản trị viên của các subreddit liên quan để đảm bảo tính minh bạch. Cách tiếp cận này không chỉ giúp chúng tôi tuân thủ pháp luật mà còn xây dựng được thiện chí với các cộng đồng mà chúng tôi đang nghiên cứu.
Vượt qua các biện pháp chống thu thập dữ liệu
Reddit, giống như nhiều nền tảng khác, thực hiện các biện pháp để ngăn chặn việc thu thập dữ liệu quá mức. Dưới đây là cách để điều hướng những thách thức này một cách có trách nhiệm:
Các cơ chế chống thu thập dữ liệu phổ biến
Trong những năm tháng làm web scraping, tôi đã gặp phải một số kỹ thuật chống scraping trên Reddit:
1. Giới hạn tần suất: Hạn chế số lượng yêu cầu từ một IP duy nhất
2. CAPTCHA: Thách thức các công cụ tự động bằng các bài kiểm tra xác minh
3. Chặn IP: Tạm thời hoặc vĩnh viễn chặn các IP nghi ngờ
4. Phát hiện User-Agent: Xác định và chặn các công cụ scraper
5. Tải nội dung động: Làm cho nội dung khó truy cập hơn bằng cách lập trình
Các chiến lược vượt qua có trách nhiệm
Mặc dù tôi không khuyến khích việc vượt qua một cách quyết liệt, nhưng những phương pháp này có thể giúp bạn scrape một cách có trách nhiệm:
Luân phiên Proxy
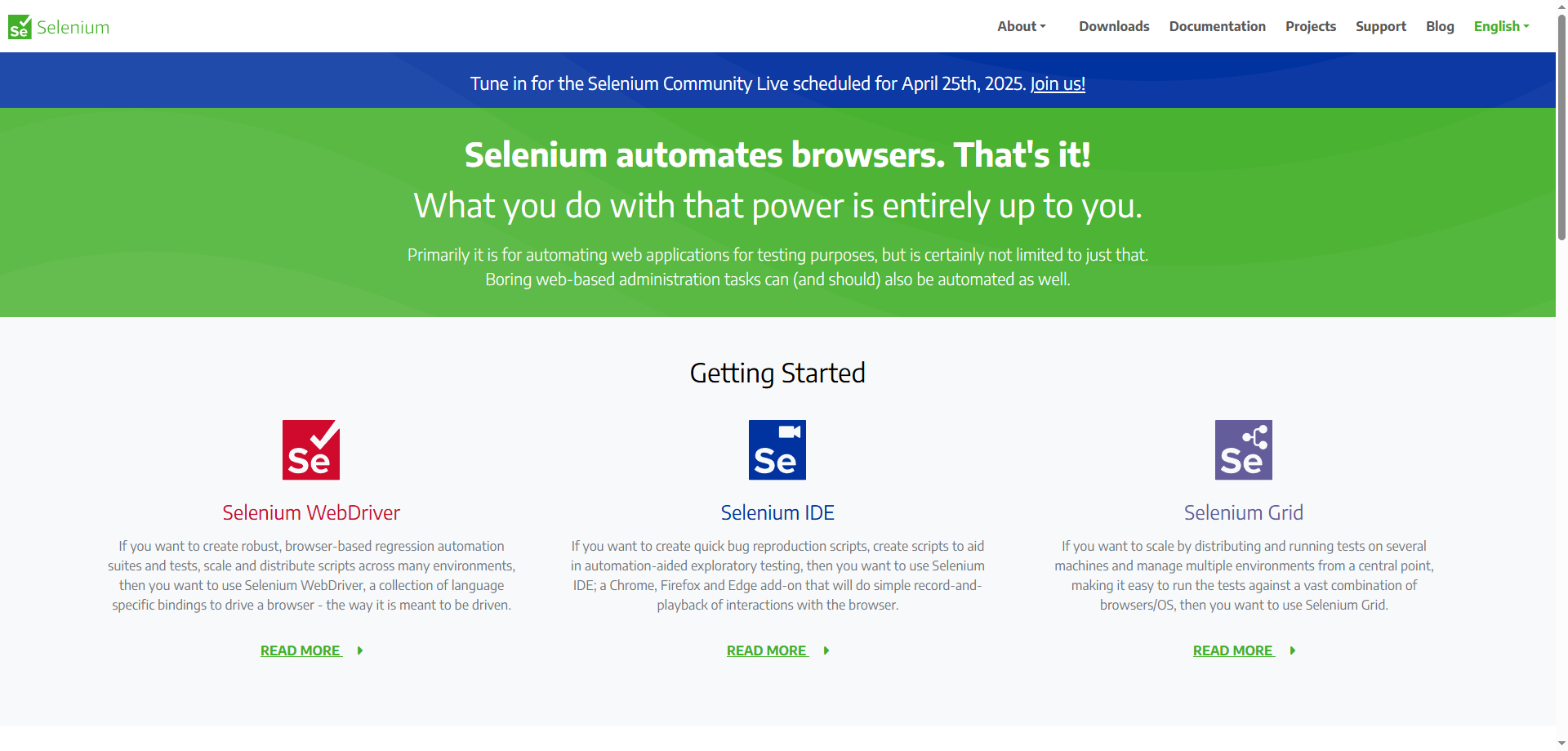
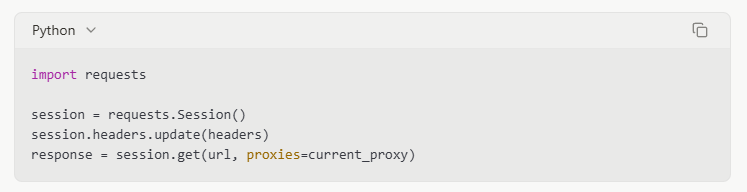
Sử dụng nhiều địa chỉ IP thông qua các proxy có thể giúp phân phối yêu cầu và tránh kích hoạt giới hạn tần suất. Tôi thường sử dụng một nhóm từ 5-10 proxy cho các dự án scraping vừa phải, luân phiên giữa chúng cho mỗi yêu cầu.
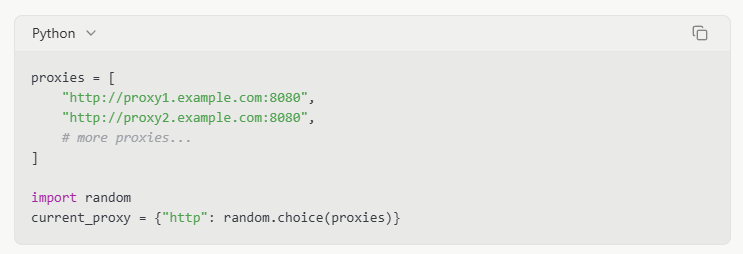
Quản lý Header Yêu cầu
Thiết lập các header trình duyệt thực tế có thể giúp scraper của bạn hòa nhập với lưu lượng truy cập bình thường:
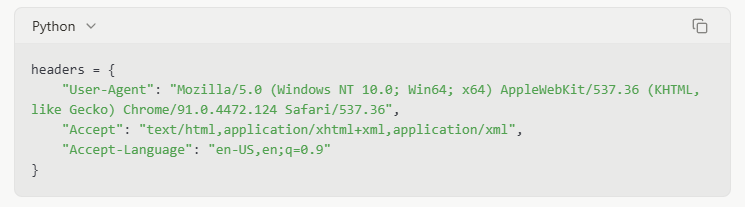
Thời gian tôn trọng
Thêm độ trễ giữa các yêu cầu mô phỏng các mẫu duyệt web của con người và giảm tải cho máy chủ:
Quản lý Phiên
Giữ cookies và thông tin phiên có thể làm cho các yêu cầu trông hợp pháp hơn:
Xuất và Sử dụng Dữ liệu Reddit
Khi bạn đã scrape thành công Reddit, bước tiếp theo là tổ chức và xuất dữ liệu đó ở định dạng có thể sử dụng.
Xuất CSV
DICloak chủ yếu được biết đến như một trình duyệt chống phát hiện để quản lý nhiều tài khoản, nhưng chức năng RPA của nó làm cho nó trở nên mạnh mẽ đặc biệt cho việc thu thập dữ liệu từ Reddit:
1.Quản lý dấu vân tay trình duyệt: DICloak tạo ra các dấu vân tay trình duyệt độc đáo và nhất quán giúp tránh các hệ thống phát hiện tinh vi của Reddit
2.Quy trình tự động: Tính năng RPA cho phép bạn tạo ra các quy trình thu thập dữ liệu tùy chỉnh có thể chạy theo lịch trình
3.Hỗ trợ nhiều tài khoản: Hoàn hảo nếu bạn cần truy cập các tài khoản Reddit khác nhau cho các dự án thu thập dữ liệu khác nhau
4.Tích hợp proxy: Hoạt động liền mạch với các proxy để phân phối yêu cầu
5.Trình tạo quy trình trực quan: Tạo các chuỗi thu thập dữ liệu mà không cần lập trình
Nếu bạn quan tâm đến việc thiết lập các quy trình RPA tùy chỉnh cho việc thu thập dữ liệu từ Reddit, bạn có thể liên hệ với đội ngũ hỗ trợ khách hàng của DICloak để thảo luận về các yêu cầu cụ thể của bạn. Họ cung cấp sự hỗ trợ cá nhân hóa trong việc tạo ra các giải pháp thu thập dữ liệu hiệu quả mà tôn trọng cả các giới hạn kỹ thuật và điều khoản dịch vụ của Reddit.
Kết luận
Việc thu thập dữ liệu từ Reddit mang lại cơ hội tuyệt vời cho các nhà nghiên cứu, nhà tiếp thị và những người đam mê dữ liệu để khai thác một trong những nguồn tài nguyên phong phú nhất của internet về nội dung và thảo luận do người dùng tạo ra. Trong suốt hướng dẫn này, chúng tôi đã khám phá các công cụ và kỹ thuật khác nhau có sẵn, từ các giải pháp dựa trên mã như PRAW đến các tùy chọn không cần mã như Octoparse, cũng như các phương pháp nâng cao sử dụng tự động hóa RPA của DICloak.
Các điểm chính rút ra từ nhiều năm kinh nghiệm của tôi với việc thu thập dữ liệu từ Reddit là:
1.Chọn công cụ phù hợp với trình độ kỹ năng và nhu cầu của bạn
2.Luôn thu thập dữ liệu một cách có trách nhiệm và đạo đức
3.Hãy chú ý đến các vấn đề pháp lý và điều khoản dịch vụ của Reddit
4.Thực hiện giới hạn tỷ lệ và xoay vòng proxy hợp lý
5.Xử lý và xuất dữ liệu của bạn ở các định dạng phù hợp với mục tiêu phân tích của bạn
Dù bạn đang tiến hành nghiên cứu học thuật, thu thập thông tin thị trường hay theo dõi xu hướng, các phương pháp được nêu trong hướng dẫn này sẽ giúp bạn trích xuất dữ liệu quý giá từ Reddit một cách hiệu quả và có trách nhiệm.
Hãy nhớ rằng bối cảnh của việc thu thập dữ liệu từ web đang liên tục phát triển, với các nền tảng thường xuyên cập nhật cấu trúc và biện pháp bảo vệ của họ. Hãy cập nhật thông tin về những thay đổi trên nền tảng của Reddit và điều chỉnh chiến lược thu thập dữ liệu của bạn cho phù hợp.
Bạn đã thử bất kỳ phương pháp thu thập dữ liệu nào từ Reddit chưa? Tôi rất muốn nghe về những trải nghiệm của bạn và bất kỳ mẹo nào bạn có thể đã phát hiện ra trong quá trình này!
Các câu hỏi thường gặp
Có vi phạm quy định của Reddit khi thu thập dữ liệu từ trang web của họ không?
Thỏa thuận người dùng của Reddit không cấm rõ ràng việc thu thập dữ liệu, nhưng nó hạn chế các yêu cầu tự động và yêu cầu tuân thủ robots.txt. Đối với việc thu thập dữ liệu quy mô lớn, việc sử dụng API chính thức được khuyến nghị khi có thể.
Làm thế nào để tôi tránh bị chặn khi thu thập dữ liệu từ Reddit?
Thực hiện các phương pháp thu thập dữ liệu tôn trọng: sử dụng độ trễ giữa các yêu cầu, xoay vòng địa chỉ IP qua các proxy, thiết lập các tác nhân người dùng thực tế và giới hạn khối lượng và tần suất thu thập dữ liệu của bạn.
Sự khác biệt giữa việc sử dụng API của Reddit và thu thập dữ liệu từ web là gì?
API cung cấp dữ liệu có cấu trúc với sự cho phép rõ ràng nhưng có giới hạn tốc độ và yêu cầu xác thực. Việc thu thập dữ liệu từ web có thể truy cập nội dung không có sẵn qua API nhưng mang lại nhiều cân nhắc về pháp lý và đạo đức hơn.
Tôi có thể bán dữ liệu tôi thu thập từ Reddit không?
Bán dữ liệu thô thu thập từ Reddit thường không được khuyến nghị và có thể vi phạm các điều khoản dịch vụ của họ. Tuy nhiên, việc bán những hiểu biết và phân tích được rút ra từ dữ liệu đó có thể chấp nhận được trong một số bối cảnh.
Làm thế nào để tôi thu thập các bình luận trên Reddit được tải động?
Đối với các bình luận được tải động, các công cụ như Selenium hoặc tự động hóa RPA của DICloak có thể mô phỏng việc cuộn và nhấp vào nút "tải thêm bình luận" để truy cập nội dung lồng ghép hoặc phân trang.
 Công cụ miễn phí
Công cụ miễn phí Cookie Cắm -in
Cookie Cắm -in Trình tạo UA
Trình tạo UA Trình tạo địa chỉ MAC
Trình tạo địa chỉ MAC Trình tạo địa chỉ IP
Trình tạo địa chỉ IP Danh Sách Địa Chỉ IP
Danh Sách Địa Chỉ IP Trình tạo mã 2FA
Trình tạo mã 2FA Đồng Hồ Thế Giới
Đồng Hồ Thế Giới Kiểm tra ẩn danh
Kiểm tra ẩn danh WebRTC Leak Test
WebRTC Leak Test Trình tạo UUID
Trình tạo UUID Trình kiểm tra Proxy
Trình kiểm tra Proxy Kiểm tra FB Ads
Kiểm tra FB Ads Quét web bằng AI
Quét web bằng AI Công Cụ SMM Miễn Phí
Công Cụ SMM Miễn Phí Công Kiểm Tra Shadowban Twitter
Công Kiểm Tra Shadowban Twitter Công cụ Kiểm tra Tên Instagram
Công cụ Kiểm tra Tên Instagram Trình tạo UTM
Trình tạo UTM Trình tạo username
Trình tạo username Trinh tao hashtag AI
Trinh tao hashtag AI Trình tạo tiêu đề LinkedIn
Trình tạo tiêu đề LinkedIn Đổi kích thước ảnh mạng xã hội
Đổi kích thước ảnh mạng xã hội







