Você já quis reunir informações do Reddit para pesquisa, análise de mercado ou criação de conteúdo? Você não está sozinho! Como alguém que passou anos trabalhando com ferramentas de extração de dados, descobri que o Reddit é uma mina de insights—se você souber como acessá-lo corretamente.
Neste guia abrangente, vou te mostrar tudo o que você precisa saber sobre scrapers do Reddit: o que são, como funcionam, quais ferramentas são melhores para iniciantes e profissionais, e como usá-las de forma ética e legal. Vou até compartilhar algumas experiências pessoais e dicas que aprendi ao longo do caminho.
O Que Você Pode Extrair do Reddit?
Antes de mergulhar nas ferramentas e técnicas, vamos explorar que tipo de dados você pode realmente extrair do Reddit. Esta plataforma oferece uma riqueza de informações em milhares de comunidades (subreddits), tornando-a inestimável para pesquisadores, profissionais de marketing e criadores de conteúdo.

Postagens e Tópicos
Os alvos mais comuns para a extração de dados do Reddit são postagens e seus tópicos associados. Quando comecei a extrair dados do Reddit para um projeto de pesquisa de mercado, fiquei impressionado com a quantidade de insights do consumidor que estavam escondidos à vista de todos. Você pode extrair:
•Títulos e conteúdos das postagens
•Contagens de upvotes e downvotes
•Datas e horários das postagens
•Tópicos de comentários e respostas aninhadas
•Prêmios e reconhecimentos especiais
Por exemplo, quando extraí dados do r/TechSupport para um cliente, descobrimos problemas recorrentes com um produto que não estavam aparecendo nos tickets de atendimento ao cliente. Esse insight os ajudou a resolver um problema antes que se tornasse um pesadelo de relações públicas!
Informações do Subreddit
Cada subreddit é uma comunidade com sua própria cultura e foco. A extração de dados de subreddits pode revelar:
•Contagens de assinantes e tendências de crescimento
•Regras e diretrizes da comunidade
•Padrões de postagem e horários de pico de atividade
•Informações sobre moderadores
•Subreddits relacionados
Uma vez usei essa abordagem para ajudar uma empresa de jogos a identificar quais subreddits seriam mais receptivos ao seu novo lançamento, com base no tamanho da comunidade e nos padrões de engajamento com jogos semelhantes.
Perfis de Usuário
Os dados dos usuários podem fornecer insights valiosos sobre padrões de comportamento e preferências:
•Histórico de postagens e comentários
•Pontuações de karma
•Idade da conta
•Comunidades ativas
•Histórico de prêmios
Lembre-se de que, embora esses dados estejam disponíveis publicamente, é importante respeitar a privacidade e anonimizar quaisquer dados que você colete para análise ou relatórios.
Principais Ferramentas de Scraping do Reddit Comparadas
Após testar dezenas de ferramentas ao longo dos anos, reduzi as opções para os scrapers do Reddit mais eficazes disponíveis em 2025. Vamos compará-los com base na facilidade de uso, recursos e custo.
Prós:
•Gratuito e de código aberto
•Acesso abrangente à API do Reddit
•Excelente documentação e suporte da comunidade
•Gerencia limites de taxa automaticamente
•Altamente personalizável para necessidades específicas
Contras:
•Requer conhecimento de Python
•O processo de configuração envolve a criação de uma conta de desenvolvedor do Reddit
•Limitado pelas restrições da API do Reddit
Melhor para: Desenvolvedores e cientistas de dados que estão confortáveis com código e precisam de soluções personalizáveis.
Usei o PRAW para vários projetos de pesquisa em grande escala, e sua confiabilidade é incomparável. A curva de aprendizado valeu a pena pelo controle que me deu sobre exatamente quais dados extrair e como processá-los.
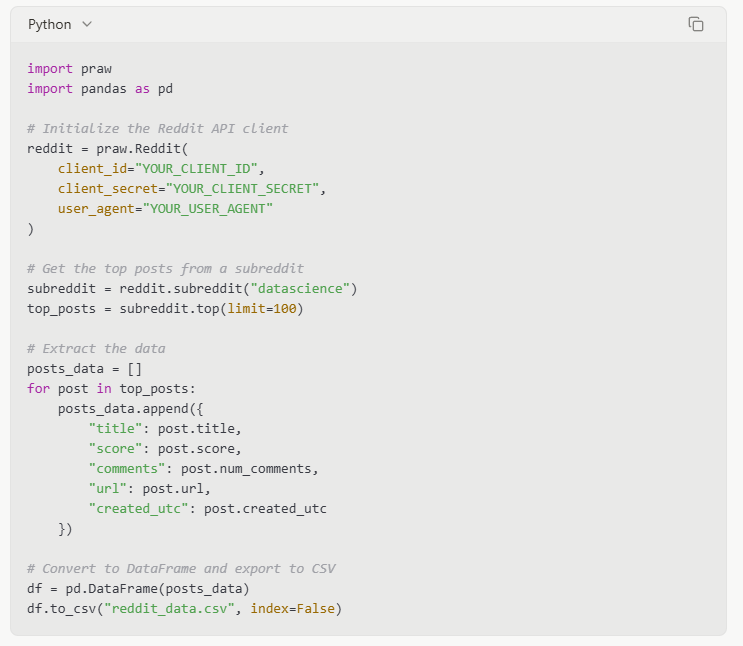
Exemplo de código:
•Sem necessidade de codificação—interface totalmente visual
•Lida automaticamente com o carregamento de conteúdo dinâmico
•Opções de execução baseadas em nuvem
•Raspagem programada em intervalos regulares
•Múltiplos formatos de exportação (CSV, Excel, JSON)
•A versão gratuita tem limitações no número de registros
•Os planos pagos começam em $75/mês
•Curva de aprendizado para tarefas de raspagem complexas
•Pode exigir ajustes à medida que o layout do Reddit muda
Melhor para: Usuários empresariais e pesquisadores sem experiência em programação que precisam de extração de dados regular.
Octoparse me salvou quando precisei entregar um projeto de análise do Reddit, mas não tinha tempo para escrever código personalizado. A interface visual facilitou a seleção exata dos dados que eu queria, e a execução em nuvem significou que eu poderia configurar e esquecer.
Apify Reddit Scraper
•Solução pré-construída especificamente para o Reddit
•Sem necessidade de autenticação
•Interface amigável com configuração mínima
•Lida com paginação e encadeamento de comentários
•Opções de exportação robustas
•Preços baseados em uso podem se acumular para projetos grandes
•Menos personalizável do que soluções baseadas em código
•Atrasos ocasionais com conteúdo muito novo
Melhor para: Profissionais de marketing e pesquisadores que precisam de resultados rápidos sem configuração técnica.
Quando trabalhei com uma equipe de marketing que precisava de dados do Reddit o mais rápido possível, Apify foi a minha escolha. Conseguimos extrair dados de sentimento de subreddits relacionados a produtos em menos de uma hora, o que levaria dias para codificar do zero.
•Especializado na estrutura do Reddit
•Sem login necessário para raspagem básica
•Capacidades de processamento em lote
•Bom equilíbrio entre usabilidade e recursos
•Preços acessíveis
•Ferramenta mais nova com uma comunidade menor
•A documentação poderia ser mais abrangente
•Alguns recursos avançados requerem assinatura paga
Melhor para: Pequenas empresas e pesquisadores individuais que precisam de dados regulares do Reddit sem complexidade técnica.
Comecei a usar o Scrupp no ano passado para um projeto pessoal de acompanhamento de tendências de jogos, e fiquei impressionado com como ele lida com a estrutura de comentários aninhados do Reddit—algo com que muitos raspadores têm dificuldades.

•Lida com conteúdo renderizado em JavaScript
•Pode simular interações do usuário
•Funciona bem com a rolagem infinita do Reddit
•Altamente personalizável
•Requer conhecimento em programação
•Mais intensivo em recursos do que soluções baseadas em API
•Necessita de manutenção regular à medida que os sites mudam
Melhor para: Desenvolvedores que precisam raspar conteúdo que não é facilmente acessível através da API.
Quando precisei raspar um subreddit que usava widgets personalizados e rolagem infinita, o Selenium foi a única ferramenta que conseguiu capturar tudo de forma confiável. É mais trabalhoso para configurar, mas pode lidar com quase qualquer desafio de raspagem.
Soluções Sem Código para Raspagem do Reddit
Nem todo mundo tem o tempo ou as habilidades técnicas para escrever código para extração de dados. Felizmente, várias ferramentas sem código surgiram que tornam a extração de dados do Reddit acessível a todos.
Guia Passo a Passo do Octoparse
Deixe-me mostrar como usei o Octoparse para extrair dados de um subreddit sem escrever uma única linha de código:
1. Baixe e instale o Octoparse a partir do site oficial deles
2. Crie uma nova tarefa clicando no botão "+"
3. Insira a URL do Reddit que você deseja extrair (por exemplo, https://www.reddit.com/r/datascience/)
4. Use a interface de apontar e clicar para selecionar os elementos que você deseja extrair:
• Clique no título de uma postagem para selecionar todos os títulos
• Clique nas contagens de votos positivos para selecionar todas as contagens
• Clique nos nomes de usuário para selecionar todos os autores
5. Configure a paginação dizendo ao Octoparse para clicar no botão "Próximo" ou rolar para baixo
6. Execute a tarefa em sua máquina local ou na nuvem
7. Exporte os dados como CSV, Excel ou JSON
Na primeira vez que usei essa abordagem, consegui extrair mais de 500 postagens do r/TechGadgets em cerca de 20 minutos, completas com títulos, pontuações e contagens de comentários — tudo isso sem escrever código!
Outras Opções Sem Código
Se o Octoparse não atender às suas necessidades, considere estas alternativas:
• ParseHub: Ótimo para sites complexos com um plano gratuito generoso
• Import.io: Focado em empresas com ferramentas de transformação poderosas
• Webscraper.io: Extensão de navegador para tarefas de extração rápidas e simples
Descobri que cada um tem suas forças, mas o Octoparse oferece o melhor equilíbrio de poder e usabilidade especificamente para o Reddit.
É Legal Extrair Dados do Reddit?
Esta é talvez a pergunta mais comum que ouço, e a resposta não é simples. Com base na minha pesquisa e experiência, aqui está o que você precisa saber:
O Cenário Legal
A extração de dados da web em si não é ilegal, mas como você faz isso e o que você faz com os dados é extremamente importante. Quando se trata do Reddit:
1. Os Termos de Serviço do Reddit permitem "uso pessoal e não comercial" de seus serviços
2. A Lei de Fraude e Abuso de Computadores (CFAA) foi interpretada de maneira diferente em vários casos judiciais relacionados à extração de dados da web
3. O caso hiQ Labs v. LinkedIn estabeleceu algum precedente de que a extração de dados publicamente disponíveis pode ser legal
Na minha experiência, a maioria das questões legais surge não do ato de extração em si, mas de como os dados são utilizados posteriormente.
Considerações Éticas
Além da legalidade, existem importantes considerações éticas:
• Respeitar o robots.txt: O arquivo robots.txt do Reddit fornece diretrizes para acesso automatizado
• Limitação de taxa: Solicitações excessivas podem sobrecarregar os servidores do Reddit
• Preocupações com a privacidade: Mesmo que os dados sejam públicos, os usuários podem não esperar que sejam coletados em massa
• Atribuição: Se publicar insights, credite o Reddit e seus usuários de forma apropriada
Eu sempre aconselho os clientes a anonimizar dados ao relatar descobertas e a serem transparentes sobre os métodos de coleta de dados.
Melhores Práticas para Conformidade Legal
Para ficar do lado seguro:
1. Leia e respeite os Termos de Serviço do Reddit
2. Implemente limitação de taxa em suas ferramentas de extração
3. Não extraia subreddits privados ou conteúdo que exija login
4. Anonimize os dados dos usuários em sua análise e relatórios
5. Use a API oficial sempre que possível
6. Considere o propósito da sua coleta de dados
Uma vez, consultei uma empresa que queria extrair dados do Reddit para avaliações de produtos. Decidimos usar a API oficial com a devida atribuição e até entramos em contato com moderadores de subreddits relevantes para garantir transparência. Essa abordagem não apenas nos manteve em conformidade legal, mas também construiu boa vontade com as comunidades que estávamos estudando.
Contornando Medidas Anti-Extração
O Reddit, como muitas plataformas, implementa medidas para prevenir a extração excessiva. Aqui está como navegar por esses desafios de forma responsável:
Mecanismos Comuns de Anti-Extração
Nos meus anos de web scraping, encontrei várias técnicas anti-scraping no Reddit:
1.Limitação de taxa: Restringir o número de solicitações de um único IP
2.CAPTCHAs: Desafiar ferramentas automatizadas com testes de verificação
3.Bloqueio de IP: Bloquear temporária ou permanentemente IPs suspeitos
4.Detectação de User-Agent: Identificar e bloquear ferramentas de scraping
5.Carregamento dinâmico de conteúdo: Tornar o conteúdo mais difícil de acessar programaticamente
Estratégias de Bypass Responsáveis
Embora eu não defenda a elisão agressiva, essas abordagens podem ajudar você a fazer scraping de forma responsável:
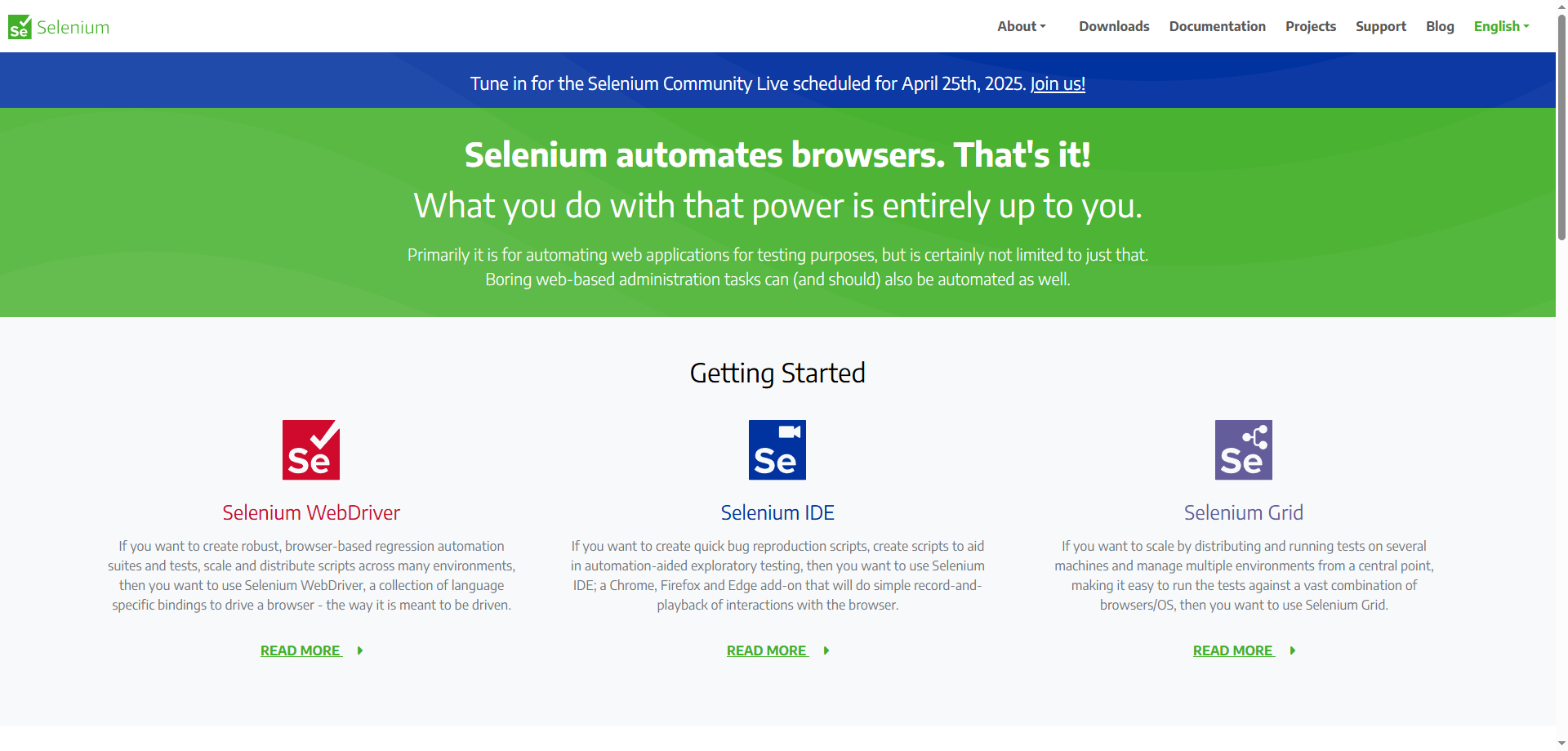
Rotação de Proxy
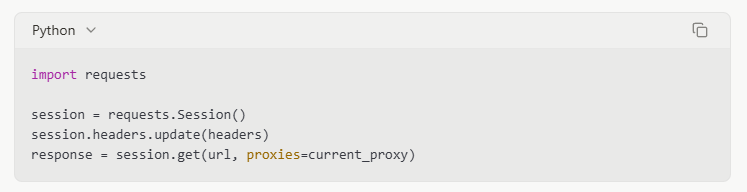
Usar múltiplos endereços IP através de proxies pode ajudar a distribuir solicitações e evitar acionar limites de taxa. Normalmente, uso um pool de 5-10 proxies para projetos de scraping moderados, alternando entre eles para cada solicitação.
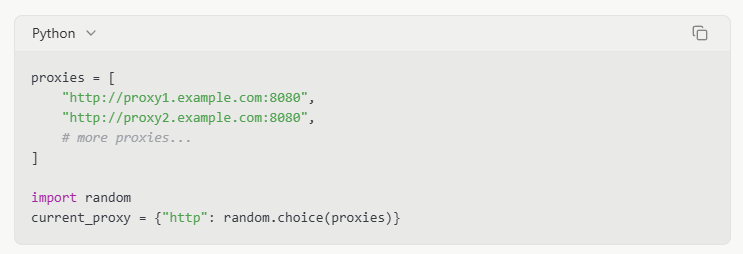
Gerenciamento de Cabeçalhos de Solicitação
Definir cabeçalhos de navegador realistas pode ajudar seu scraper a se misturar ao tráfego normal:
Tempo Respeitoso
Adicionar atrasos entre solicitações imita padrões de navegação humana e reduz a carga do servidor:
Gerenciamento de Sessão
Manter cookies e informações de sessão pode fazer com que as solicitações pareçam mais legítimas:
Exportando e Usando Dados do Reddit
Uma vez que você tenha feito scraping com sucesso do Reddit, o próximo passo é organizar e exportar esses dados em um formato utilizável.
Exportação CSV
CSV (Valores Separados por Vírgula) é perfeito para dados tabulares e compatibilidade com software de planilhas:

Eu prefiro CSV para a maioria dos projetos porque é fácil de abrir no Excel ou Google Sheets para uma análise rápida ou compartilhamento com membros da equipe não técnicos.
Exportação JSON
JSON (Notação de Objetos JavaScript) é melhor para preservar estruturas de dados aninhadas, como threads de comentários:
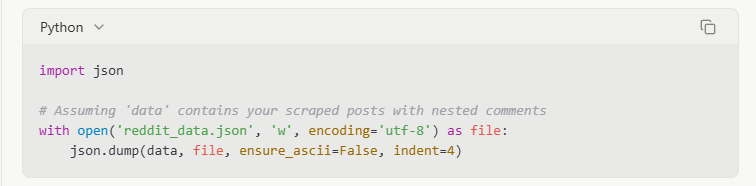
Quando eu coletei dados de um subreddit com muitas discussões, o JSON foi essencial para manter as relações pai-filho nas threads de comentários, que teriam sido achatadas em um formato CSV.
DataFrames do Pandas
Para análise de dados em Python, converter para um DataFrame do Pandas oferece poderosas capacidades de processamento:

Eu achei essa abordagem particularmente útil para projetos que exigem visualização de dados ou análise estatística, já que o Pandas se integra bem com ferramentas como Matplotlib e Seaborn.
Raspagem Avançada do Reddit com a Automação RPA do DICloak
Embora as ferramentas que discutimos até agora funcionem bem para muitos cenários, há situações em que você precisa de soluções mais sofisticadas—especialmente ao lidar com as cada vez mais complexas medidas anti-bot do Reddit ou ao gerenciar vários projetos de raspagem simultaneamente.
É aqui que o Navegador Antidetect do DICloak com capacidades de RPA (Automação de Processos Robóticos) entra em cena. Eu descobri essa ferramenta no ano passado, e ela mudou completamente minha abordagem para projetos de raspagem complexos.
O que Torna o DICloak Diferente para Raspagem do Reddit
DICloak é conhecido principalmente como um navegador antidetect para gerenciar várias contas, mas sua funcionalidade de RPA o torna excepcionalmente poderoso para scraping do Reddit:
1.Gerenciamento de Impressões de Navegador: DICloak cria impressões de navegador únicas e consistentes que ajudam a evitar os sofisticados sistemas de detecção do Reddit
2.Fluxos de Trabalho Automatizados: A funcionalidade de RPA permite que você crie fluxos de trabalho de scraping personalizados que podem ser executados conforme agendado
3.Suporte a Múltiplas Contas: Perfeito se você precisar acessar diferentes contas do Reddit para vários projetos de scraping
4.Integração de Proxy: Funciona perfeitamente com proxies para distribuir solicitações
5.Construtor de Fluxo de Trabalho Visual: Crie sequências de scraping sem codificação
Se você estiver interessado em configurar fluxos de trabalho de RPA personalizados para scraping do Reddit, pode entrar em contato com a equipe de suporte ao cliente do DICloak para discutir suas necessidades específicas. Eles oferecem assistência personalizada na criação de soluções de scraping eficientes que respeitam tanto as limitações técnicas do Reddit quanto os termos de serviço.
Conclusão
O scraping do Reddit oferece oportunidades incríveis para pesquisadores, profissionais de marketing e entusiastas de dados aproveitarem uma das fontes mais ricas de conteúdo gerado por usuários e discussões da internet. Ao longo deste guia, exploramos as várias ferramentas e técnicas disponíveis, desde soluções baseadas em código como PRAW até opções sem código como Octoparse, além de abordagens avançadas usando a automação RPA do DICloak.
Os principais aprendizados da minha experiência de anos com scraping do Reddit são:
1.Escolha a ferramenta certa para seu nível de habilidade e necessidades
2.Sempre faça scraping de forma responsável e ética
3.Tenha em mente as considerações legais e os termos de serviço do Reddit
4.Implante limitação de taxa adequada e rotação de proxies
5.Processar e exportar seus dados em formatos que atendam aos seus objetivos de análise
Seja você um pesquisador acadêmico, coletando insights de mercado ou acompanhando tendências, as abordagens descritas neste guia ajudarão você a extrair dados valiosos do Reddit de forma eficaz e responsável.
Lembre-se de que o cenário de web scraping está em constante evolução, com plataformas atualizando suas estruturas e proteções regularmente. Mantenha-se informado sobre as mudanças na plataforma do Reddit e ajuste suas estratégias de scraping de acordo.
Você já tentou algum desses métodos de scraping do Reddit? Adoraria ouvir sobre suas experiências e quaisquer dicas que você possa ter descoberto ao longo do caminho!
Perguntas Frequentes
É contra as regras do Reddit fazer scraping em seu site?
O Acordo de Usuário do Reddit não proíbe explicitamente o scraping, mas limita solicitações automatizadas e exige conformidade com o robots.txt. Para scraping em larga escala, é recomendado usar a API oficial sempre que possível.
Como posso evitar ser bloqueado enquanto faço scraping no Reddit?
Implemente práticas de scraping respeitosas: use atrasos entre as solicitações, gire endereços IP através de proxies, defina agentes de usuário realistas e limite seu volume e frequência de scraping.
Qual é a diferença entre usar a API do Reddit e fazer web scraping?
A API fornece dados estruturados com permissão explícita, mas tem limites de taxa e requer autenticação. O web scraping pode acessar conteúdo não disponível através da API, mas envolve mais considerações legais e éticas.
Posso vender os dados que extraio do Reddit?
Vender dados brutos extraídos do Reddit geralmente não é recomendado e pode violar seus termos de serviço. No entanto, vender insights e análises derivadas desses dados pode ser aceitável em alguns contextos.
Como faço para extrair comentários do Reddit que são carregados dinamicamente?
Para comentários carregados dinamicamente, ferramentas como Selenium ou a automação RPA do DICloak podem simular a rolagem e clicar em botões "carregar mais comentários" para acessar conteúdo aninhado ou paginado.
Qual é o melhor formato para armazenar dados do Reddit para análise?
Para dados tabulares simples, CSV funciona bem. Para preservar estruturas aninhadas como threads de comentários, JSON é melhor. Para análise imediata em Python, os DataFrames do Pandas oferecem a maior flexibilidade.
 Ferramentas Gratuitas
Ferramentas Gratuitas Cookie Plugin
Cookie Plugin Gerador de UA
Gerador de UA Gerador de Endereço MAC
Gerador de Endereço MAC Gerador de Endereço IP
Gerador de Endereço IP Lista de Endereços IP
Lista de Endereços IP Gerador de Código 2FA
Gerador de Código 2FA Relógio Mundial
Relógio Mundial Verificação de Anonimato
Verificação de Anonimato WebRTC Leak Test
WebRTC Leak Test Gerador de UUID
Gerador de UUID Verificador de Proxy
Verificador de Proxy Verificador de Anúncios FB
Verificador de Anúncios FB Coleta Web com IA
Coleta Web com IA Ferramentas SMM Grátis
Ferramentas SMM Grátis Verificador de Shadowban do Twitter
Verificador de Shadowban do Twitter Verificador de Nomes do Instagram
Verificador de Nomes do Instagram Gerador UTM
Gerador UTM Gerador de nomes de usuário
Gerador de nomes de usuário Gerador de hashtags com IA
Gerador de hashtags com IA Gerador de títulos para LinkedIn
Gerador de títulos para LinkedIn Redimensionador de imagens sociais
Redimensionador de imagens sociais







