Web scraping is essential for collecting data, helping businesses analyze trends, monitor competitors, and make informed decisions. However, with the growing demand for data, there is also a need for protection against unauthorized extraction, leading to the development of scraper bot protections.
Scraper bots are automated tools used to extract data, but they can also be exploited for malicious purposes, like stealing content or overloading servers. To prevent these threats, websites implement anti-scraping technologies. Common scraper tools are designed to mimic human behavior to collect valuable information, but websites have become increasingly adept at detecting these automated activities.
Understanding how to bypass these scraper bot protections is crucial for ethical scraping. This article covers how web scrapers work, common protection methods, and ethical strategies to bypass them. It also explores web scraping tools, real-world case studies, and answers to frequently asked questions.
By the end, you'll understand scraper bot protection and how to navigate it responsibly.
If you're interested in learning more about advanced web scraping techniques, we've previously discussed tools like Crawl4AI, which offers an open-source solution for smart crawling. Additionally, we explored the importance of integrating essential components into your web scraper to enhance its effectiveness. For those looking to leverage AI for web scraping, our guide on using AI-powered tools provides valuable insights.
Web Scraping: How It Works and Its Applications
Web scraping is the process of extracting data from websites using automated tools. These tools, often referred to as web scrapers or bots, mimic human browsing behavior to collect information from web pages. The process typically involves sending requests to a web server, retrieving the page's HTML, and parsing the content to extract relevant data.
How Web Scrapers Work
Web scrapers work by using specific algorithms to navigate websites, download content, and then parse it for useful data. These tools are designed to emulate a real user’s behavior, such as following links, clicking buttons, and filling out forms. Most web scraping tools rely on programming languages like Python, Java, or Node.js, combined with libraries like BeautifulSoup, Scrapy, or Puppeteer for efficient data extraction.
1.Sending Requests: The scraper sends HTTP requests to the website’s server to retrieve the HTML content of the page.
2.Parsing HTML: Once the content is retrieved, the scraper parses the HTML to extract the desired data, such as text, images, or links.
3.Data Extraction: After parsing, the scraper collects the information in a structured format, such as CSV, JSON, or databases, for further analysis.
Applications of Web Scraping
Web scraping is widely used across various industries for diverse purposes. Some common applications include:
- Market Research: Scraping data from competitors’ websites allows businesses to track prices, promotions, and market trends, giving them a competitive edge.
- SEO: Scraping data from search engine results pages (SERPs) helps SEO professionals analyze keyword rankings, backlinks, and competitors’ SEO strategies. You can read more about SEO web scraping here.
- Social Media Monitoring: Scraping social media platforms helps businesses track brand mentions, sentiment analysis, and customer engagement.
- E-commerce: E-commerce websites use web scraping to aggregate product information from multiple sources, compare prices, and analyze customer reviews.
Web scraping has become an indispensable tool for data-driven decision-making. However, with increasing scraper bot protection measures, it’s crucial to navigate the web scraping process responsibly and ensure compliance with legal and ethical standards.
Understanding Scraper Bot Protection
As web scraping has become more prevalent, websites have implemented various measures to protect their content and prevent automated bots from extracting data. Scraper bot protection involves a range of techniques designed to detect and block scraping activities, ensuring that only legitimate users can access the data.
Common Scraper Bot Protection Techniques
Websites use a combination of technological solutions to thwart scraper bots. These include:
- IP Blocking: One of the most common techniques is blocking the IP addresses of suspicious users. If a particular IP address sends an unusually high volume of requests in a short period, it may be flagged as a scraper bot, and its access may be restricted.
- CAPTCHAs: CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) challenges are designed to verify that a user is human. These tests often require users to solve puzzles, such as identifying distorted characters or selecting specific images. Many websites use CAPTCHAs to prevent scraper tools from accessing their pages.
- Rate Limiting: Websites often limit the number of requests a user can make within a certain time frame. This is known as rate limiting. If a user exceeds the allowed number of requests, they may be temporarily blocked or throttled.
- Browser Fingerprinting: This technique collects information about a user's browser, such as the version, operating system, and plugins. If these details match known patterns of a scraper bot, the site may block the request.
- Session Tracking: Websites may track user sessions through cookies or other identifiers. If a session appears to be automated or lacks typical user behavior (such as mouse movement or clicks), it may be flagged and blocked.
- Honeypots: A honeypot is a trap set by websites to detect scraping bots. It’s a hidden field or link that human users won’t interact with, but scrapers may try to access. If a scraper bot interacts with the honeypot, it’s flagged as suspicious.
Why These Protections Matter
These techniques are critical in safeguarding the website's data, ensuring that only authorized users can access it. However, these protections also pose a challenge for web scrapers who need to access data for legitimate reasons, such as market research or competitive analysis. Understanding how these protections work and how to navigate them is key to ethical web scraping.
By employing strategies to bypass these protections responsibly, web scrapers can continue to gather valuable data while respecting websites' security measures.
Strategies to Bypass Scraper Bot Protection
While websites use various techniques to protect their data from scraper bots, there are strategies that ethical web scrapers can use to bypass these protections. The key to bypassing these scraper bot protections responsibly is to mimic legitimate user behavior while staying within the boundaries of legal and ethical guidelines.
1. Using Proxies
One of the most effective ways to bypass IP blocking is by using proxies. Proxies act as intermediaries between the scraper and the website, masking the scraper's actual IP address. This makes it harder for websites to identify and block the scraper tool.
- Rotating Proxies: Rotating proxies change the IP address with each request, which helps distribute requests across multiple IPs. This reduces the likelihood of triggering IP blocks.
- Residential Proxies: Residential proxies use real IP addresses from actual residential networks, making them less likely to be flagged as bots. They offer higher anonymity and are effective at bypassing geo-blocking and CAPTCHAs.
2. Emulating Human Behavior
Websites use advanced techniques to detect non-human behavior, such as rapid clicking, high request rates, or lack of interaction with the site’s elements. Mimicking human behavior is key to avoiding detection.
- Delays Between Requests: Introducing random delays between requests simulates human browsing behavior and avoids triggering rate-limiting protections.
- Mouse Movement and Click Simulation: Simulating mouse movements and clicks on web pages makes the scraper appear more human-like.
3. Bypassing CAPTCHAs
CAPTCHAs are a major barrier for scrapers, but there are ways to bypass them. Although solving CAPTCHAs manually is an option, there are more automated methods available.
- CAPTCHA Solvers: Tools like 2Captcha and AntiCaptcha offer services to solve CAPTCHAs automatically. They send the CAPTCHA image to human workers who solve it, allowing scrapers to continue their operations.
- Headless Browsers: Using headless browsers like Puppeteer can sometimes bypass CAPTCHAs by making the scraping activity appear more like a legitimate user. These browsers run in the background without the need for a GUI.
4. User-Agent Spoofing
Websites often track user agents to identify bots. Scrapers can avoid detection by spoofing the user-agent string to make it appear as if the request is coming from a legitimate browser.
- Rotating User-Agents: By rotating user-agent strings for each request, scrapers can disguise themselves as different devices and browsers. Tools like User-Agent Switcher can help achieve this.
5. Using CAPTCHA-Friendly Browsers
Some scraping tools are designed to handle CAPTCHA challenges in real-time. For instance, DICloak offers an anti-detect browser that helps bypass CAPTCHA and other anti-scraping mechanisms by using advanced techniques to make the scraper look like a regular user.
6. Stealth Mode
Stealth mode refers to advanced techniques that involve masking the scraper’s digital footprint. This includes hiding the scraper’s fingerprint, session data, and unique device identifiers.
Browser Fingerprint Masking: Tools like DICloak help isolate browser fingerprints, making it harder for websites to track and block scrapers.
By using these strategies, web scrapers can effectively bypass common scraper bot protection mechanisms while ensuring compliance and ethical practices. Understanding and implementing these methods will help you maintain anonymity during data collection and reduce the risk of detection and blocking.
Tools and Technologies for Effective Web Scraping
To carry out web scraping efficiently and effectively, a variety of tools and technologies are available. These tools help automate the scraping process, handle complex websites, and ensure that scrapers bypass protections while remaining ethical and compliant with legal standards.
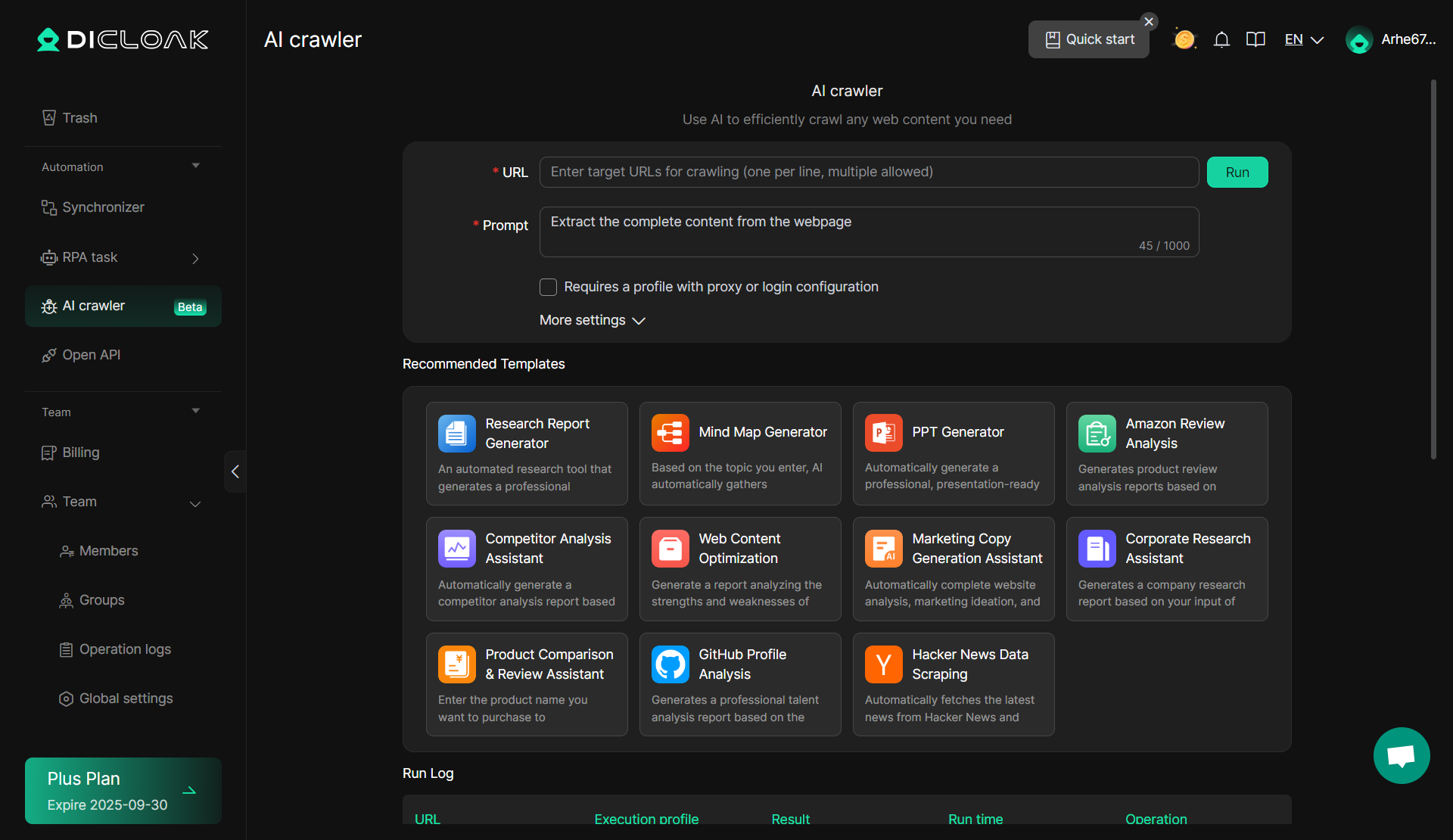
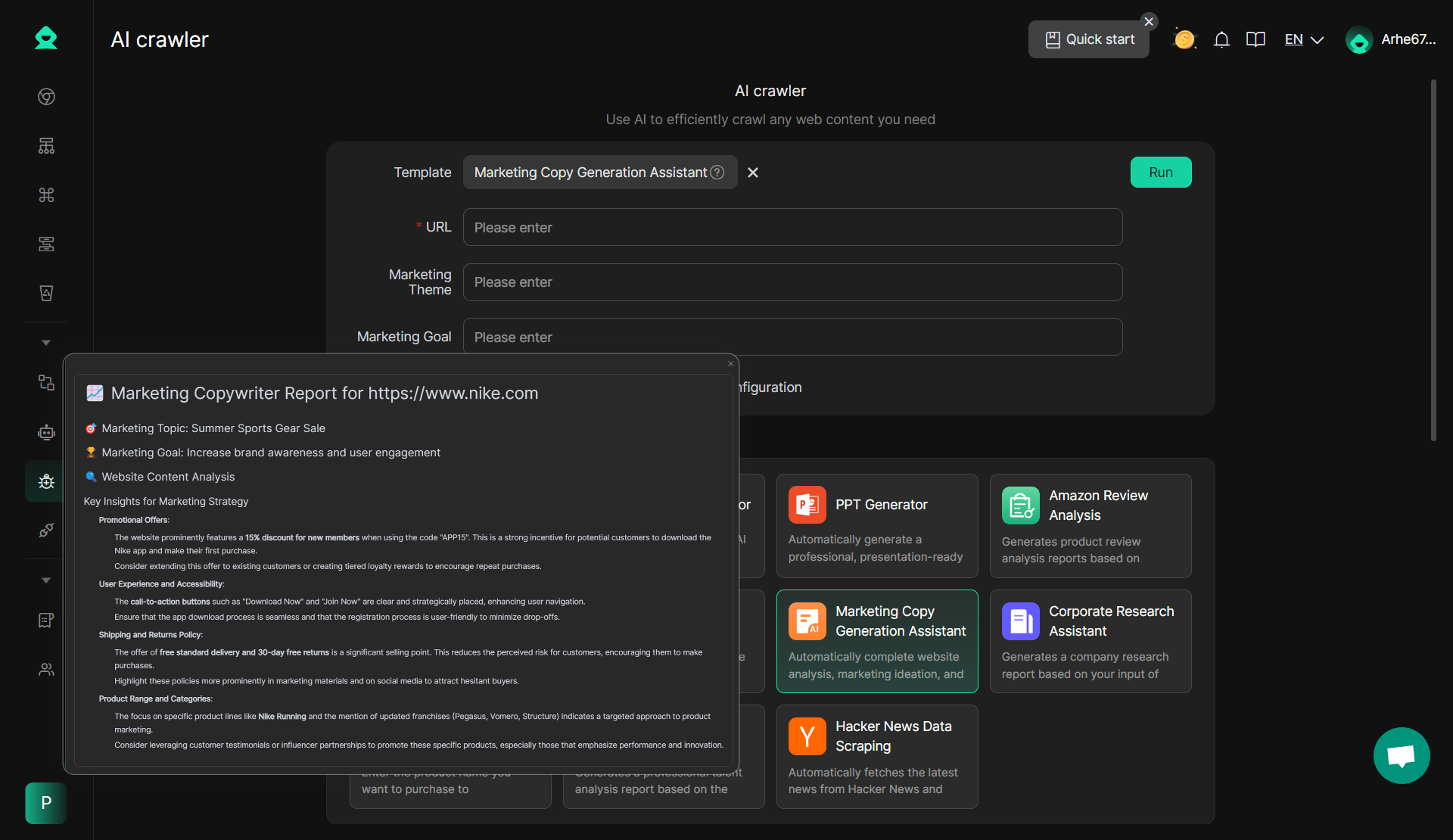
Here is a simple tool for basic scraping needs and businesses looking for an easy-to-use solution that requires minimal technical knowledge. The AI Crawler from DICloak is an excellent choice.
DICloak: AI Crawler
One notable scraper tool in DICloak's suite is the AI Crawler. This built-in tool leverages artificial intelligence to enhance the web scraping experience, especially when dealing with dynamic or complex websites. The AI Crawler mimics human browsing behavior and can adjust to varying web profiles, making it highly effective at bypassing scraper bot protection systems. It can autonomously adapt to different website structures, improving the efficiency and success rate of scraping tasks.
- Advantages:The AI Crawler automatically adjusts to changing website structures and can bypass many common anti-scraping protections like CAPTCHA and IP blocking. It is highly efficient for large-scale scraping and can handle a variety of complex tasks without the need for constant manual adjustments.
- No Coding Required: Simply input a prompt, and you can start scraping immediately—no coding skills needed.
- Proxy and Account Configuration: Easily configure proxies and accounts to scrape deeper into platform data, enhancing the depth of your web scraping and bypassing scraper bot protection by mimicing human browsing behavior.
- 11 Pre-built Templates: With 11 updated templates, the AI Crawler covers a wide range of scenarios and business needs, enabling quick and efficient data collection.
- Wide Range of Use Cases: The AI Crawler supports various business applications, making it ideal for fast, simple data scraping that improves operational efficiency.
Professional web scraping platforms for more advanced and large-scale web scraping needs, there are several professional scraping platforms that offer more control, scalability, and flexibility.
Scrapy is an open-source web scraper framework written in Python. It is widely used for scraping websites, extracting data, and storing it in various formats, such as JSON, CSV, or databases. Scrapy is particularly suitable for large-scale scraping tasks, as it supports crawling multiple pages simultaneously, and its built-in features, such as user-agent rotation, can help avoid detection by scraper bot protection systems. Here is tutorial.
- Advantages: Fast, scalable, and supports multiple data formats.
- Disadvantages: Requires programming knowledge to set up and use.
BeautifulSoup is a Python library that makes it easy to scrape data from HTML and XML files. It is best used for smaller scraping tasks, where users need to extract data from a static page or simple websites. It’s simple to set up and use, making it perfect for beginners.
- Advantages: Easy to use, great for small-scale scraping.
- Disadvantages: Less efficient for large-scale scraping compared to frameworks like Scrapy.
Puppeteer is a Node.js library that provides a high-level API to control headless Chrome or Chromium browsers. It’s useful for scraping websites that use JavaScript or require user interactions (like clicking buttons or filling forms). Puppeteer can bypass common scraper bot protection techniques like CAPTCHA and is especially effective for scraping dynamic websites.
- Advantages: Handles JavaScript-heavy websites, emulates human-like behavior.
- Disadvantages: Slower than traditional scraping methods.
Selenium is another popular tool for automating browsers. It can be used with various programming languages like Python, Java, and C#. Selenium is primarily used for testing web applications, but it’s also very effective for web scraping tasks, especially for pages that require interaction.
- Advantages: Works with all modern web browsers and supports multiple languages.
- Disadvantages: Requires more resources and can be slower than headless tools like Puppeteer.
Apify is a platform that provides web scraping and automation tools using a cloud-based approach. It allows users to create web scraper bots, automate workflows, and integrate with APIs. Apify is ideal for businesses looking to scale their web scraping efforts and collect data from various online sources.
- Advantages: Scalable, cloud-based, supports multiple use cases.
- Disadvantages: Can be expensive for large-scale operations.
These tools and technologies offer a range of features that cater to different web scraping needs, from simple scraping tasks to large-scale data extraction. By choosing the right scraper tool, web scrapers can ensure efficient, ethical, and compliant data collection while bypassing common scraper bot protection.
Drawbacks of These Tools and How to Improve with DICloak
While there are many tools and technologies available for web scraping, they come with their own set of limitations. DICloak, with its advanced anti-detection features, can help overcome many of these challenges, making web scraping both efficient and secure.
1. IP Blocking and Proxy Issues
Many web scraping tools rely on proxies to bypass IP-based restrictions. However, using proxies can sometimes lead to slower performance or increased detection by scraper bot protection mechanisms. Traditional proxy solutions might not be able to effectively disguise scraping activities, especially when multiple requests are sent from the same IP address.
DICloak Solution: DICloak solves this issue by offering advanced proxy configuration, supporting rotating proxies and residential IPs to ensure smooth and seamless browsing. Its real-time IP switching capability makes it harder for websites to detect and block scrapers. With DICloak, you can manage multiple accounts and web scraping tasks without triggering security measures like IP blocking.
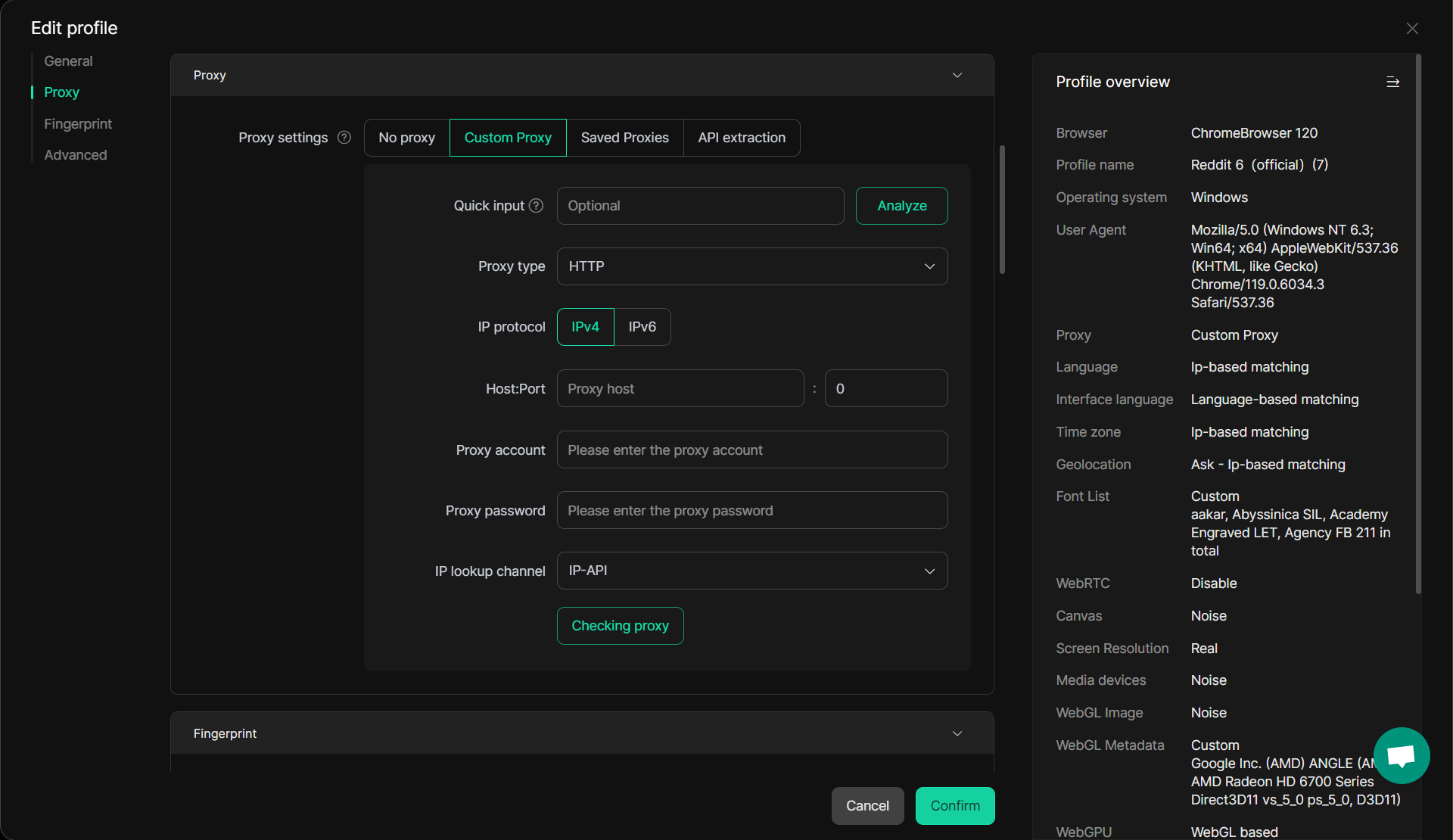
2. Browser Fingerprinting and Detection
Most traditional web scraping tools struggle with browser fingerprinting, a technique used by websites to identify and block bots. These tools typically use static user-agent strings or IP addresses, making it easier for websites to detect and block scraping attempts.
DICloak Solution: DICloak provides sophisticated browser fingerprint isolation, ensuring that each scraping session appears as a unique user with different digital fingerprints. By masking identifiers like screen resolution, fonts, and plugins, DICloak mimics human browsing behavior, reducing the chances of detection. This fingerprint isolation is especially useful for bypassing sophisticated anti-scraping technologies. Read more on how DICloak helps with fingerprint isolation here.
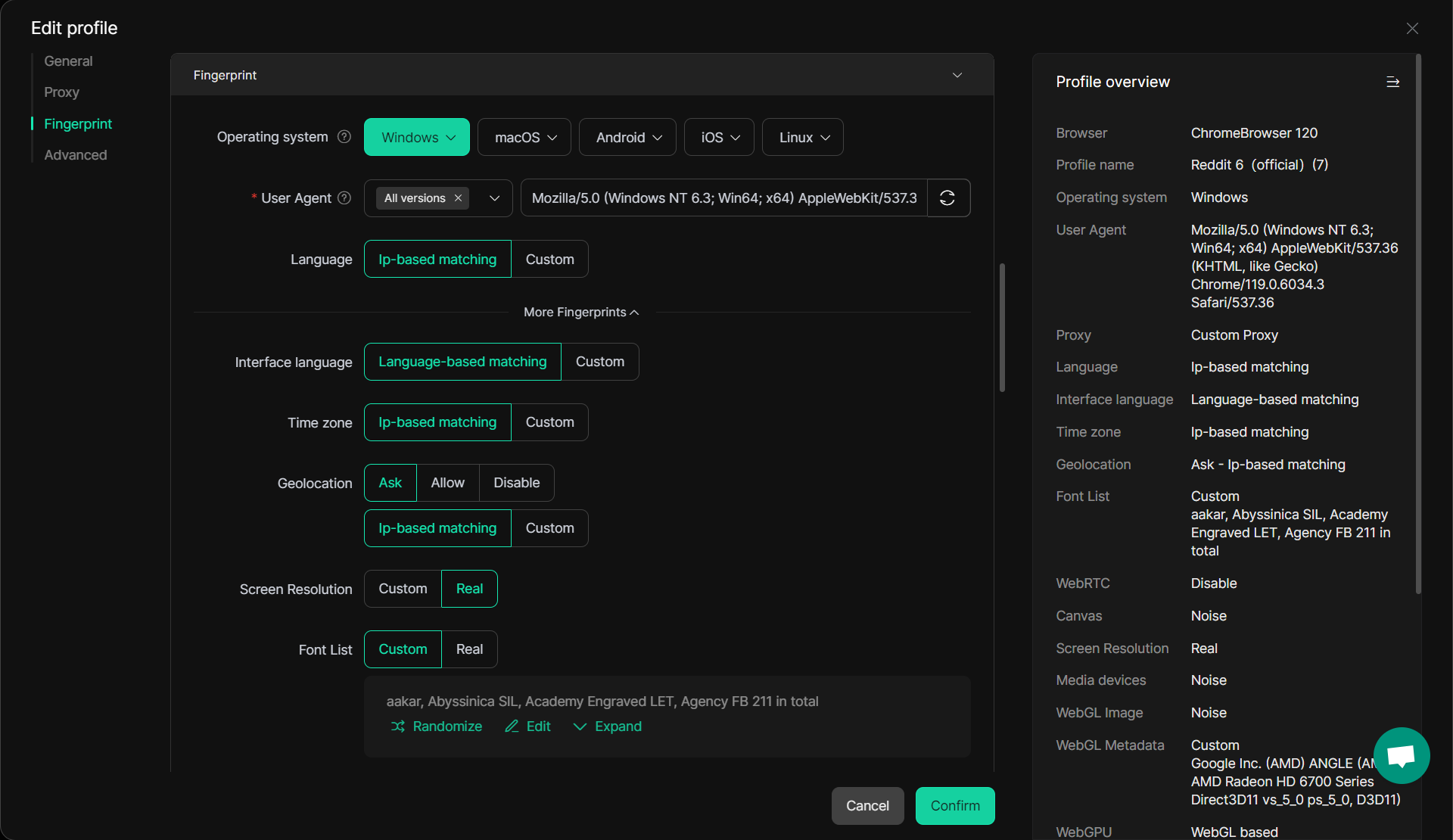
In addition to the effective solutions DICloak provides for the three risks mentioned above, the DICloak AI Crawler is the perfect complement, making it even more powerful. When you're working with complex, professional web scraping tasks, DICloak helps you reduce the risks. But when you need to scrape data quickly and efficiently from simple sources, DICloak steps in to improve your efficiency.
DICloak AI Crawler: Enhanced Security and Convenience
DICloak's AI Crawler can safely and effectively scrape large-scale data without triggering detection systems. Its ability to autonomously adjust to changing website structures makes it highly efficient for dynamic sites, reducing the risk of detection and blocking.
DICloak AI Crawler Features:
- No Coding Required: Simply input a prompt to start scraping immediately, with no coding necessary.
- Proxy and Account Configuration: Easily configure proxies and accounts to scrape deeper into platform data, enhancing the depth of your web scraping.
- 11 Pre-built Templates: With 11 updated templates, the AI Crawler covers a wide range of scenarios and business needs, enabling quick and efficient data collection.
- Wide Range of Use Cases: The AI Crawler supports various business applications, making it ideal for fast, simple data scraping that improves operational efficiency.
FAQs about Bypassing Scraper Bot Protection
Q1: What is scraper bot protection?
Scraper bot protection refers to the techniques websites use to prevent automated bots from extracting data. These include measures such as IP blocking, CAPTCHA challenges, browser fingerprinting, and rate limiting. Websites implement these protections to ensure that only legitimate users can access their content and data, safeguarding against malicious scraping activities.
Q2: How can I bypass scraper bot protection safely?
To bypass scraper bot protection responsibly, you can use strategies such as rotating proxies, emulating human behavior (e.g., adding delays between requests), spoofing user-agent strings, and using CAPTCHA solvers. These methods allow you to perform web scraping in a way that minimizes the risk of detection and blocking, ensuring compliance with legal and ethical standards.
Q3: What tools are best for web scraping?
There are several scraper tools available for effective web scraping, including:
- Scrapy: A fast, scalable, and powerful framework for large-scale scraping.
- BeautifulSoup: A simple tool for smaller scraping tasks.
- Puppeteer: Best for scraping JavaScript-heavy websites.
- Selenium: Great for pages requiring user interaction.
- DICloak: An anti-detect browser that enhances scraping efficiency by bypassing common scraper bot protection systems.
Q4: How does DICloak help with scraper bot protection?
DICloak helps bypass scraper bot protection by isolating browser fingerprints, rotating IPs, and offering advanced proxy configurations. It allows web scrapers to maintain anonymity by preventing websites from detecting scraping activities. Additionally, DICloak provides session management and can simulate human-like interactions, reducing the likelihood of being blocked or flagged as a bot.
Q5: Can scraper bots be used for ethical purposes?
Yes, scraper bots can be used ethically for legitimate purposes such as market research, competitor analysis, and data aggregation. However, it’s important to follow legal guidelines, respect website terms of service, and ensure compliance with scraper bot protection measures. Ethical web scraping should always respect the privacy and security of the data being scraped.
Q6: Why is it important to manage scraping sessions?
Session and cookie management is crucial in web scraping to ensure that each session is treated as a unique user. Proper session management prevents websites from tracking and blocking scrapers based on shared cookies or session data. DICloak excels at managing sessions, ensuring that web scrapers can access data without triggering security measures like IP bans or CAPTCHAs.
Conclusion
In conclusion, web scraping has become a powerful tool for gathering data, allowing businesses to gain insights, track competitors, and improve decision-making. However, with the rise of scraper bot protection technologies, navigating the scraping process responsibly is essential. Tools like DICloak provide advanced solutions to bypass common protections such as IP blocking, CAPTCHA, and browser fingerprinting, allowing web scrapers to operate with increased efficiency and security.
By using DICloak’s AI Crawler and other advanced features, scrapers can not only reduce the risks associated with detection and blocking but also streamline the scraping process, enabling faster and more accurate data collection. Whether you're tackling complex scraping tasks or handling simpler data extraction needs, DICloak ensures compliance with legal and ethical standards while improving overall productivity.
As web scraping continues to play a crucial role in data-driven decision-making, understanding how to work with scraper bot protection systems and using the right tools will be key to ensuring both effective and responsible scraping practices.
 Web Proxy Tools
Web Proxy Tools Free Tools
Free Tools Cookie Plugin
Cookie Plugin UA Generator
UA Generator MAC Address Generator
MAC Address Generator IP Generator
IP Generator IP Address List
IP Address List 2FA Code Generator
2FA Code Generator World Clock
World Clock Anonymous Check
Anonymous Check WebRTC Leak Test
WebRTC Leak Test UUID Generator
UUID Generator Free Web Proxy Site
Free Web Proxy Site Proxy Checker
Proxy Checker FB Ad Checker
FB Ad Checker AI Web Scraping
AI Web Scraping Free SMM Tools
Free SMM Tools Twitter Shadowban Checker
Twitter Shadowban Checker Instagram Name Checker
Instagram Name Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator







