O web scraping é essencial para coletar dados, ajudar as empresas a analisar tendências, monitorar concorrentes e tomar decisões informadas. No entanto, com a crescente demanda por dados, há também uma necessidade de proteção contra extração não autorizada, levando ao desenvolvimento de proteções de bot scraper.
Os bots scraper são ferramentas automatizadas usadas para extrair dados, mas também podem ser explorados para fins maliciosos, como roubar conteúdo ou sobrecarregar servidores. Para evitar essas ameaças, os sites implementam tecnologias anti-scraping. As ferramentas comuns de scraper são projetadas para imitar o comportamento humano para coletar informações valiosas, mas os sites têm se tornado cada vez mais hábeis em detetar essas atividades automatizadas.
Entender como contornar essas proteções de bot scraper é crucial para a raspagem ética. Este artigo aborda como os web scrapers funcionam, métodos de proteção comuns e estratégias éticas para ignorá-los. Também explora ferramentas de web scraping , estudos de caso do mundo real e respostas a perguntas frequentes.
No final, você entenderá a proteção do bot scraper e como navegar por ela de forma responsável.
Se você estiver interessado em aprender mais sobre técnicas avançadas de web scraping, já discutimos ferramentas como o Crawl4AI, que oferece uma solução de código aberto para rastreamento inteligente. Além disso, exploramos a importância de integrar componentes essenciais em seu web scraper para melhorar sua eficácia. Para aqueles que procuram aproveitar a IA para a web scraping, nosso guia sobre o uso de ferramentas baseadas em IA fornece informações valiosas.
Web Scraping: Como funciona e suas aplicações
Web scraping é o processo de extração de dados de sites usando ferramentas automatizadas. Essas ferramentas, muitas vezes referidas como web scrapers ou bots, imitam o comportamento de navegação humana para coletar informações de páginas da web. O processo normalmente envolve o envio de solicitações para um servidor Web, a recuperação do HTML da página e a análise do conteúdo para extrair dados relevantes.
Como funcionam os Web Scrapers
Os Web scrapers funcionam usando algoritmos específicos para navegar em sites, baixar conteúdo e, em seguida, analisá-lo em busca de dados úteis. Essas ferramentas são projetadas para emular o comportamento de um usuário real, como seguir links, clicar em botões e preencher formulários. A maioria das ferramentas de web scraping depende de linguagens de programação como Python, Java ou Node.js, combinadas com bibliotecas como BeautifulSoup, Scrapy ou Puppeteer para uma extração de dados eficiente.
1.Enviando solicitações: O scraper envia solicitações HTTP para o servidor do site para recuperar o conteúdo HTML da página.
2.Análise HTML: Uma vez que o conteúdo é recuperado, o scraper analisa o HTML para extrair os dados desejados, como texto, imagens ou links.
3.Extração de dados: Após a análise, o scraper coleta as informações em um formato estruturado, como CSV, JSON ou bancos de dados, para análise posterior.
Aplicações de Web Scraping
Web scraping é amplamente utilizado em vários setores para diversos fins. Algumas aplicações comuns incluem:
- Pesquisa de mercado: A coleta de dados dos sites dos concorrentes permite que as empresas acompanhem preços, promoções e tendências de mercado, dando-lhes uma vantagem competitiva.
- SEO: Raspar dados de páginas de resultados de mecanismos de busca (SERPs) ajuda os profissionais de SEO a analisar rankings de palavras-chave, backlinks e estratégias de SEO dos concorrentes. Você pode ler mais sobre SEO web scraping aqui.
- Monitoramento de mídia social: raspar plataformas de mídia social ajuda as empresas a rastrear menções à marca, análise de sentimento e envolvimento do cliente.
- Comércio eletrônico: Os sites de comércio eletrônico usam o web scraping para agregar informações de produtos de várias fontes, comparar preços e analisar avaliações de clientes.
O web scraping tornou-se uma ferramenta indispensável para a tomada de decisões baseada em dados. No entanto, com o aumento das medidas de proteção do bot scraper , é crucial navegar no processo de web scraping de forma responsável e garantir a conformidade com os padrões legais e éticos.
Noções básicas sobre a proteção do Scraper Bot
À medida que o web scraping se tornou mais prevalente, os sites implementaram várias medidas para proteger seu conteúdo e impedir que bots automatizados extraiam dados. A proteção do bot Scraper envolve uma série de técnicas projetadas para detetar e bloquear atividades de scraping, garantindo que apenas usuários legítimos possam acessar os dados.
Técnicas comuns de proteção de bots de raspador
Os sites usam uma combinação de soluções tecnológicas para frustrar os bots scraper. Estes incluem:
- Bloqueio de IP: Uma das técnicas mais comuns é bloquear os endereços IP de usuários suspeitos. Se um determinado endereço IP enviar um volume anormalmente alto de solicitações em um curto período, ele pode ser sinalizado como um bot scraper e seu acesso pode ser restrito.
- CAPTCHAs: Os desafios CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) são projetados para verificar se um usuário é humano. Esses testes geralmente exigem que os usuários resolvam quebra-cabeças, como identificar personagens distorcidos ou selecionar imagens específicas. Muitos sites usam CAPTCHAs para impedir que ferramentas de scraper acessem suas páginas.
- Limitação de taxa: Os sites geralmente limitam o número de solicitações que um usuário pode fazer dentro de um determinado período de tempo. Isso é conhecido como limitação de taxa. Se um usuário exceder o número permitido de solicitações, elas poderão ser temporariamente bloqueadas ou limitadas.
- Impressão digital do navegador: essa técnica coleta informações sobre o navegador de um usuário, como a versão, o sistema operacional e os plugins. Se esses detalhes corresponderem aos padrões conhecidos de um bot scraper, o site pode bloquear a solicitação.
- Rastreamento de sessão: Os sites podem rastrear as sessões do usuário por meio de cookies ou outros identificadores. Se uma sessão parecer automatizada ou não tiver um comportamento típico do usuário (como movimento do mouse ou cliques), ela poderá ser sinalizada e bloqueada.
- Honeypots: Um honeypot é uma armadilha criada por sites para detetar bots de scraping. É um campo oculto ou link com o qual os usuários humanos não interagem, mas os scrapers podem tentar acessar. Se um bot scraper interage com o honeypot, ele é sinalizado como suspeito.
Por que essas proteções são importantes
Estas técnicas são fundamentais na salvaguarda dos dados do website, garantindo que apenas utilizadores autorizados o possam aceder. No entanto, essas proteções também representam um desafio para os web scrapers que precisam acessar dados por motivos legítimos, como pesquisa de mercado ou análise competitiva. Entender como essas proteções funcionam e como navegar nelas é a chave para o web scraping ético.
Ao empregar estratégias para contornar essas proteções de forma responsável, os web scrapers podem continuar a coletar dados valiosos, respeitando as medidas de segurança dos sites.
Estratégias para contornar a proteção do Scraper Bot
Embora os sites usem várias técnicas para proteger seus dados de bots scraper, existem estratégias que os web scrapers éticos podem usar para contornar essas proteções. A chave para contornar essas proteções de bot scraper de forma responsável é imitar o comportamento legítimo do usuário, permanecendo dentro dos limites das diretrizes legais e éticas.
1. Usando proxies
Uma das maneiras mais eficazes de contornar o bloqueio de IP é usando proxies. Os proxies atuam como intermediários entre o scraper e o site, mascarando o endereço IP real do scraper . Isso torna mais difícil para os sites identificar e bloquear a ferramenta scraper.
- Proxies rotativos: proxies rotativos alteram o endereço IP a cada solicitação, o que ajuda a distribuir solicitações entre vários IPs. Isso reduz a probabilidade de acionar blocos IP.
- Proxies residenciais: Os proxies residenciais usam endereços IP reais de redes residenciais reais, tornando-os menos propensos a serem sinalizados como bots. Eles oferecem maior anonimato e são eficazes para contornar o bloqueio geográfico e CAPTCHAs.
2. Emulando o comportamento humano
Os sites usam técnicas avançadas para detetar comportamentos não humanos, como cliques rápidos, altas taxas de solicitação ou falta de interação com os elementos do site. Imitar o comportamento humano é fundamental para evitar a deteção.
- Atrasos entre solicitações: a introdução de atrasos aleatórios entre solicitações simula o comportamento de navegação humana e evita acionar proteções de limitação de taxa.
- Simulação de movimento e clique do mouse: Simular movimentos do mouse e cliques em páginas da web faz com que o raspador pareça mais humano.
3. Ignorando CAPTCHAs
Os CAPTCHAs são uma grande barreira para os scrapers, mas há maneiras de contorná-los. Embora a resolução manual de CAPTCHAs seja uma opção, existem métodos mais automatizados disponíveis.
- CAPTCHA Solvers: Ferramentas como 2Captcha e AntiCaptcha oferecem serviços para resolver CAPTCHAs automaticamente. Eles enviam a imagem do CAPTCHA para trabalhadores humanos que a resolvem, permitindo que os raspadores continuem suas operações.
- Navegadores sem cabeça: Usar navegadores sem cabeça como o Puppeteer às vezes pode ignorar CAPTCHAs, fazendo com que a atividade de raspagem pareça mais como um usuário legítimo. Esses navegadores são executados em segundo plano sem a necessidade de uma GUI.
4. Falsificação do agente do usuário
Os sites geralmente rastreiam agentes de usuário para identificar bots. Os raspadores podem evitar a deteção falsificando a cadeia de caracteres do agente do usuário para fazer parecer que a solicitação está vindo de um navegador legítimo.
- Agentes de usuário rotativos: Ao girar cadeias de caracteres de agente do usuário para cada solicitação, os scrapers podem se disfarçar como diferentes dispositivos e navegadores. Ferramentas como o User-Agent Switcher podem ajudar a conseguir isso.
5. Usando navegadores compatíveis com CAPTCHA
Algumas ferramentas de raspagem são projetadas para lidar com desafios CAPTCHA em tempo real. Por exemplo, o DICloak oferece um navegador anti-detecção que ajuda a contornar o CAPTCHA e outros mecanismos anti-scraping usando técnicas avançadas para fazer o scraper parecer um usuário comum.
6. Modo furtivo
O modo furtivo refere-se a técnicas avançadas que envolvem mascarar a pegada digital do raspador. Isso inclui ocultar a impressão digital do raspador, os dados da sessão e os identificadores exclusivos do dispositivo.
Mascaramento de impressão digital do navegador: Ferramentas como o DICloak ajudam a isolar as impressões digitais do navegador, tornando mais difícil para os sites rastrear e bloquear raspadores.
Ao usar essas estratégias, os web scrapers podem efetivamente ignorar os mecanismos comuns de proteção do bot scraper , garantindo a conformidade e as práticas éticas. Compreender e implementar esses métodos ajudará você a manter o anonimato durante a coleta de dados e reduzir o risco de deteção e bloqueio.
Ferramentas e tecnologias para um web scraping eficaz
Para realizar web scraping de forma eficiente e eficaz, uma variedade de ferramentas e tecnologias estão disponíveis. Essas ferramentas ajudam a automatizar o processo de raspagem, lidar com sites complexos e garantir que os raspadores ignorem as proteções, permanecendo éticos e em conformidade com os padrões legais.
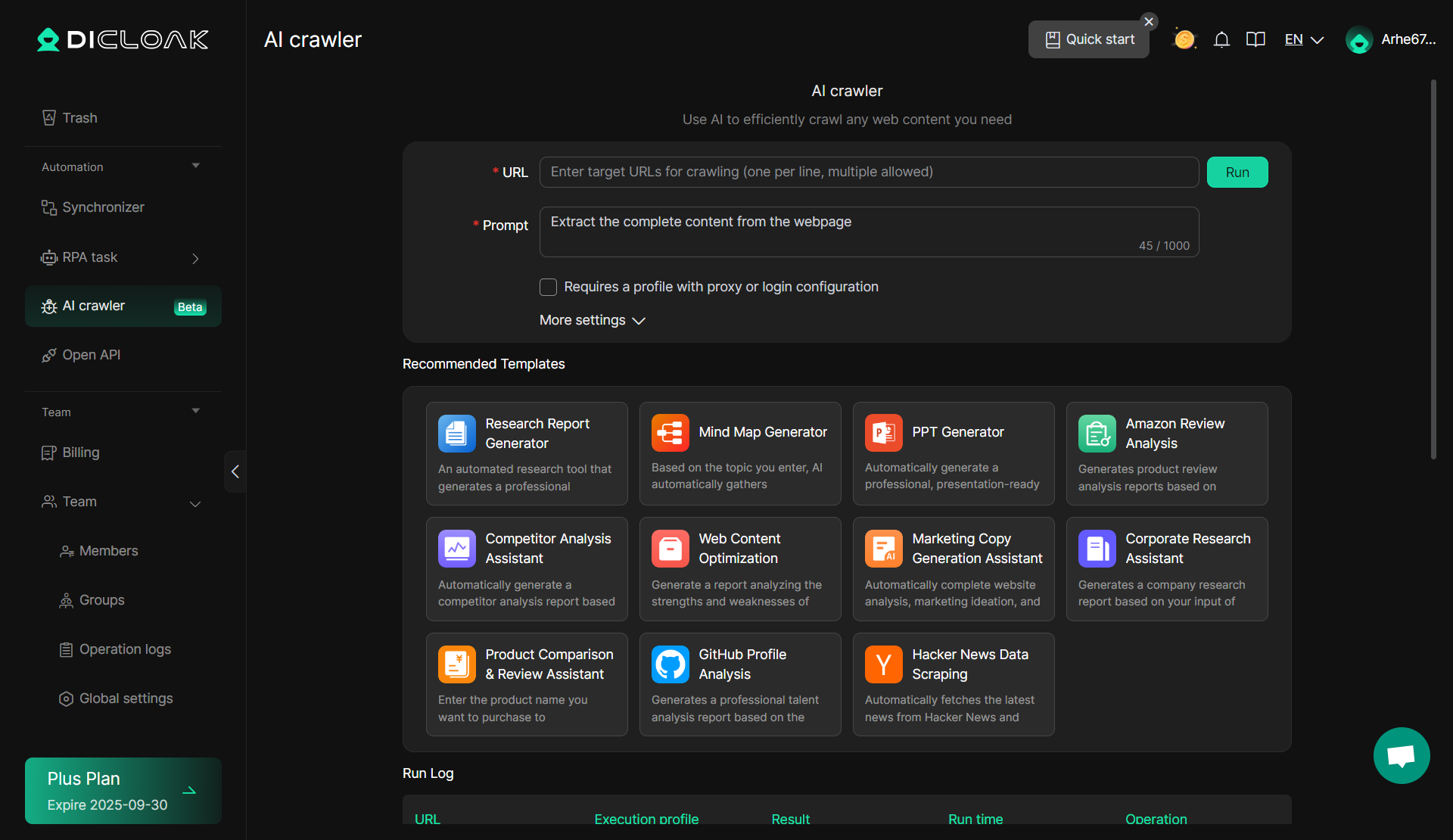
Aqui está uma ferramenta simples para necessidades básicas de raspagem e empresas que procuram uma solução fácil de usar que requer conhecimento técnico mínimo. O AI Crawler da DICloak é uma excelente escolha.
DICloak: Rastreador de IA
Uma ferramenta de scraper notável no pacote do DICloak é o AI Crawler. Esta ferramenta integrada aproveita a inteligência artificial para melhorar a experiência de web scraping , especialmente ao lidar com sites dinâmicos ou complexos. O AI Crawler imita o comportamento de navegação humana e pode se ajustar a vários perfis da web, tornando-o altamente eficaz para contornar os sistemas de proteção de bots scraper . Pode adaptar-se autonomamente a diferentes estruturas de websites, melhorando a eficiência e a taxa de sucesso das tarefas de scraping.
- Vantagens: O AI Crawler se ajusta automaticamente às mudanças nas estruturas do site e pode ignorar muitas proteções anti-scraping comuns, como CAPTCHA e bloqueio de IP. É altamente eficiente para raspagem em grande escala e pode lidar com uma variedade de tarefas complexas sem a necessidade de ajustes manuais constantes.
- Sem necessidade de codificação: basta inserir um prompt e você pode começar a raspar imediatamente, sem necessidade de habilidades de codificação.
- Configuração de proxy e conta: configure facilmente proxies e contas para se aprofundar nos dados da plataforma, aumentando a profundidade do seu web scraping e ignorando a proteção do bot scraper imitando o comportamento de navegação humana.
- 11 modelos pré-construídos: Com 11 modelos atualizados, o AI Crawler cobre uma ampla gama de cenários e necessidades de negócios, permitindo uma coleta de dados rápida e eficiente.
- Ampla gama de casos de uso: O AI Crawler suporta vários aplicativos de negócios, tornando-o ideal para a coleta rápida e simples de dados que melhora a eficiência operacional.
Plataformas profissionais de web scraping Para necessidades de web scraping mais avançadas e em grande escala, existem várias plataformas profissionais de scraping que oferecem mais controle, escalabilidade e flexibilidade.
Scrapy é um framework web scraper de código aberto escrito em Python. É amplamente utilizado para raspar sites, extrair dados e armazená-los em vários formatos, como JSON, CSV ou bancos de dados. O Scrapy é particularmente adequado para tarefas de raspagem em grande escala, pois suporta o rastreamento de várias páginas simultaneamente, e seus recursos internos, como a rotação do agente do usuário, podem ajudar a evitar a deteção por sistemas de proteção de bot de scraper . Aqui está o tutorial.
- Vantagens: Rápido, escalável e suporta vários formatos de dados.
- Desvantagens: Requer conhecimentos de programação para configurar e usar.
BeautifulSoup é uma biblioteca Python que facilita a coleta de dados de arquivos HTML e XML. É melhor usado para tarefas de raspagem menores, onde os usuários precisam extrair dados de uma página estática ou sites simples. É simples de configurar e usar, tornando-o perfeito para iniciantes.
- Vantagens: Fácil de usar, ótimo para raspagem em pequena escala.
- Desvantagens: Menos eficiente para raspagem em grande escala em comparação com estruturas como Scrapy.
- Vantagens: Lida com sites pesados em JavaScript, emula o comportamento humano.
- Desvantagens: Mais lento do que os métodos tradicionais de raspagem.
Selenium é outra ferramenta popular para automatizar navegadores. Ele pode ser usado com várias linguagens de programação como Python, Java e C#. Selenium é usado principalmente para testar aplicações web, mas também é muito eficaz para tarefas de web scraping , especialmente para páginas que exigem interação.
- Vantagens: Funciona com todos os navegadores modernos e suporta vários idiomas.
- Desvantagens: Requer mais recursos e pode ser mais lento do que ferramentas sem cabeça como o Puppeteer.
- Vantagens: Escalável, baseado na nuvem, suporta vários casos de uso.
- Desvantagens: Pode ser caro para operações de grande escala.
Essas ferramentas e tecnologias oferecem uma gama de recursos que atendem a diferentes necessidades de web scraping , desde tarefas simples de scraping até extração de dados em larga escala. Ao escolher a ferramenta de scraper certa, os web scrapers podem garantir uma coleta de dados eficiente, ética e compatível, ignorando a proteção comum do bot scraper.
Desvantagens dessas ferramentas e como melhorar com DICloak
Embora existam muitas ferramentas e tecnologias disponíveis para web scraping, elas vêm com seu próprio conjunto de limitações. O DICloak, com seus recursos avançados de antidetecção, pode ajudar a superar muitos desses desafios, tornando o web scraping eficiente e seguro.
1. Bloqueio de IP e problemas de proxy
Muitas ferramentas de web scraping dependem de proxies para contornar restrições baseadas em IP. No entanto, o uso de proxies às vezes pode levar a um desempenho mais lento ou maior deteção por mecanismos de proteção de bot scraper . As soluções de proxy tradicionais podem não ser capazes de disfarçar eficazmente as atividades de scraping, especialmente quando várias solicitações são enviadas do mesmo endereço IP.
Solução DICloak: DICloak resolve este problema oferecendo configuração de proxy avançada, suportando proxies rotativos e IPs residenciais para garantir uma navegação suave e perfeita. Sua capacidade de comutação de IP em tempo real torna mais difícil para os sites detetar e bloquear scrapers. Com o DICloak, você pode gerenciar várias contas e tarefas de web scraping sem acionar medidas de segurança, como bloqueio de IP.
2. Deteção e impressão digital do navegador
A maioria das ferramentas tradicionais de web scraping luta com a impressão digital do navegador, uma técnica usada por sites para identificar e bloquear bots. Essas ferramentas normalmente usam cadeias de caracteres estáticas do agente do usuário ou endereços IP, tornando mais fácil para os sites detetar e bloquear tentativas de raspagem.
Solução DICloak: DICloak fornece isolamento sofisticado de impressão digital do navegador, garantindo que cada sessão de raspagem apareça como um usuário único com diferentes impressões digitais. Ao mascarar identificadores como resolução de tela, fontes e plugins, o DICloak imita o comportamento de navegação humana, reduzindo as chances de deteção. Este isolamento de impressões digitais é especialmente útil para contornar tecnologias sofisticadas anti-scraping. Leia mais sobre como o DICloak ajuda com o isolamento de impressões digitais aqui.
Além das soluções eficazes que o DICloak fornece para os três riscos mencionados acima, o DICloak AI Crawler é o complemento perfeito, tornando-o ainda mais poderoso. Quando está a trabalhar com tarefas complexas e profissionais de web scraping , o DICloak ajuda-o a reduzir os riscos. Mas quando você precisa coletar dados de forma rápida e eficiente de fontes simples, o DICloak entra em ação para melhorar sua eficiência.
DICloak AI Crawler: Segurança e conveniência aprimoradas
O AI Crawler da DICloak pode coletar dados em grande escala de forma segura e eficaz sem acionar sistemas de deteção. A sua capacidade de se ajustar autonomamente às mudanças nas estruturas do site torna-o altamente eficiente para sites dinâmicos, reduzindo o risco de deteção e bloqueio.
DICloak AI Crawler Características:
- Sem necessidade de codificação: basta inserir um prompt para começar a raspar imediatamente, sem necessidade de codificação.
- Configuração de proxy e conta: configure facilmente proxies e contas para aprofundar os dados da plataforma, aumentando a profundidade do seu web scraping.
- 11 modelos pré-construídos: Com 11 modelos atualizados, o AI Crawler cobre uma ampla gama de cenários e necessidades de negócios, permitindo uma coleta de dados rápida e eficiente.
- Ampla gama de casos de uso: O AI Crawler suporta vários aplicativos de negócios, tornando-o ideal para a coleta rápida e simples de dados que melhora a eficiência operacional.
Perguntas frequentes sobre como Bypassing Scraper Bot Protection
P1: O que é a proteção de bot scraper?
A proteção do bot scraper refere-se às técnicas que os sites usam para impedir que bots automatizados extraiam dados. Isso inclui medidas como bloqueio de IP, desafios de CAPTCHA, impressão digital do navegador e limitação de taxa. Os sites implementam essas proteções para garantir que apenas usuários legítimos possam acessar seus conteúdos e dados, protegendo contra atividades maliciosas de scraping.
P2: Como posso ignorar a proteção do bot scraper com segurança?
Para ignorar a proteção do bot scraper de forma responsável, você pode usar estratégias como rotação de proxies, emulação do comportamento humano (por exemplo, adição de atrasos entre solicitações), falsificação de cadeias de caracteres do agente do usuário e uso de solucionadores CAPTCHA. Estes métodos permitem-lhe realizar web scraping de forma a minimizar o risco de deteção e bloqueio, garantindo o cumprimento das normas legais e éticas.
P3: Quais são as melhores ferramentas para web scraping?
Existem várias ferramentas de scraper disponíveis para um web scraping eficaz, incluindo:
- Scrapy: Uma estrutura rápida, escalável e poderosa para raspagem em grande escala.
- BeautifulSoup: Uma ferramenta simples para tarefas de raspagem menores.
- Puppeteer: Ideal para raspar sites pesados em JavaScript.
- Selenium: Ótimo para páginas que exigem interação do usuário.
- DICloak: Um navegador anti-detecção que melhora a eficiência de raspagem ignorando sistemas comuns de proteção de bots de scraper .
P4: Como o DICloak ajuda com a proteção do bot scraper?
O DICloak ajuda a contornar a proteção do bot scraper isolando as impressões digitais do navegador, girando IPs e oferecendo configurações avançadas de proxy. Ele permite que os web scrapers mantenham o anonimato, impedindo que sites detetem atividades de scraping. Além disso, o DICloak fornece gerenciamento de sessão e pode simular interações semelhantes às humanas, reduzindo a probabilidade de ser bloqueado ou sinalizado como um bot.
P5: Os scraper bots podem ser usados para fins éticos?
Sim, os bots scraper podem ser usados eticamente para fins legítimos, como pesquisa de mercado, análise da concorrência e agregação de dados. No entanto, é importante seguir as diretrizes legais, respeitar os termos de serviço do site e garantir a conformidade com as medidas de proteção do bot scraper . A raspagem ética da web deve sempre respeitar a privacidade e a segurança dos dados que estão sendo raspados.
P6: Por que é importante gerenciar sessões de raspagem?
O gerenciamento de sessão e cookies é crucial no web scraping para garantir que cada sessão seja tratada como um usuário único. O gerenciamento adequado da sessão impede que os sites rastreiem e bloqueiem scrapers com base em cookies compartilhados ou dados de sessão. O DICloak se destaca no gerenciamento de sessões, garantindo que os web scrapers possam acessar dados sem acionar medidas de segurança, como proibições de IP ou CAPTCHAs.
Conclusão
Em conclusão, o web scraping tornou-se uma ferramenta poderosa para coletar dados, permitindo que as empresas obtenham insights, rastreiem concorrentes e melhorem a tomada de decisões. No entanto, com o aumento das tecnologias de proteção de bots de scraper , navegar no processo de raspagem de forma responsável é essencial. Ferramentas como DICloak fornecem soluções avançadas para contornar proteções comuns, como bloqueio de IP, CAPTCHA e impressão digital do navegador, permitindo que os web scrapers operem com maior eficiência e segurança.
Ao usar o AI Crawler da DICloak e outros recursos avançados, os scrapers podem não apenas reduzir os riscos associados à deteção e bloqueio, mas também simplificar o processo de scraping, permitindo uma coleta de dados mais rápida e precisa. Se você está lidando com tarefas complexas de raspagem ou lidando com necessidades mais simples de extração de dados, o DICloak garante a conformidade com os padrões legais e éticos, melhorando a produtividade geral.
Como o web scraping continua a desempenhar um papel crucial na tomada de decisões baseada em dados, entender como trabalhar com sistemas de proteção de bots scraper e usar as ferramentas certas será fundamental para garantir práticas de scraping eficazes e responsáveis.
 Ferramentas Gratuitas
Ferramentas Gratuitas Cookie Plugin
Cookie Plugin Gerador de UA
Gerador de UA Gerador de Endereço MAC
Gerador de Endereço MAC Gerador de Endereço IP
Gerador de Endereço IP Lista de Endereços IP
Lista de Endereços IP Gerador de Código 2FA
Gerador de Código 2FA Relógio Mundial
Relógio Mundial Verificação de Anonimato
Verificação de Anonimato WebRTC Leak Test
WebRTC Leak Test Gerador de UUID
Gerador de UUID Verificador de Proxy
Verificador de Proxy Verificador de Anúncios FB
Verificador de Anúncios FB Coleta Web com IA
Coleta Web com IA Ferramentas SMM Grátis
Ferramentas SMM Grátis Verificador de Shadowban do Twitter
Verificador de Shadowban do Twitter Verificador de Nomes do Instagram
Verificador de Nomes do Instagram Gerador UTM
Gerador UTM Gerador de nomes de usuário
Gerador de nomes de usuário Gerador de hashtags com IA
Gerador de hashtags com IA







