Web scraping rất cần thiết để thu thập dữ liệu, giúp doanh nghiệp phân tích xu hướng, theo dõi đối thủ cạnh tranh và đưa ra quyết định sáng suốt. Tuy nhiên, với nhu cầu dữ liệu ngày càng tăng, cũng có nhu cầu bảo vệ chống lại việc trích xuất trái phép, dẫn đến sự phát triển của các biện pháp bảo vệ bot cạp.
Bot cạp là công cụ tự động được sử dụng để trích xuất dữ liệu, nhưng chúng cũng có thể bị khai thác cho các mục đích xấu, như đánh cắp nội dung hoặc làm quá tải máy chủ. Để ngăn chặn những mối đe dọa này, các trang web triển khai các công nghệ chống cạo. Các công cụ quét thông thường được thiết kế để bắt chước hành vi của con người để thu thập thông tin có giá trị, nhưng các trang web ngày càng trở nên thành thạo trong việc phát hiện các hoạt động tự động này.
Hiểu cách vượt qua các biện pháp bảo vệ bot cạp này là rất quan trọng đối với việc cạo có đạo đức. Bài viết này đề cập đến cách hoạt động của trình quét web , các phương pháp bảo vệ phổ biến và các chiến lược đạo đức để vượt qua chúng. Nó cũng khám phá các công cụ quét web , nghiên cứu điển hình trong thế giới thực và câu trả lời cho các câu hỏi thường gặp.
Cuối cùng, bạn sẽ hiểu bảo vệ bot cạp và cách điều hướng nó một cách có trách nhiệm.
Nếu bạn muốn tìm hiểu thêm về các kỹ thuật quét web nâng cao, trước đây chúng ta đã thảo luận về các công cụ như Crawl4AI, cung cấp giải pháp mã nguồn mở để thu thập dữ liệu thông minh. Ngoài ra, chúng tôi đã khám phá tầm quan trọng của việc tích hợp các thành phần thiết yếu vào trình quét web của bạn để nâng cao hiệu quả của nó. Đối với những người muốn tận dụng AI để quét web, hướng dẫn của chúng tôi về cách sử dụng các công cụ hỗ trợ AI cung cấp thông tin chi tiết có giá trị.
Web Scraping: Cách thức hoạt động và ứng dụng của nó
Quét web là quá trình trích xuất dữ liệu từ các trang web bằng các công cụ tự động. Những công cụ này, thường được gọi là trình quét web hoặc bot, bắt chước hành vi duyệt web của con người để thu thập thông tin từ các trang web. Quá trình này thường liên quan đến việc gửi yêu cầu đến máy chủ web, truy xuất HTML của trang và phân tích cú pháp nội dung để trích xuất dữ liệu có liên quan.
Cách thức hoạt động của Web Scrapers
Trình quét web hoạt động bằng cách sử dụng các thuật toán cụ thể để điều hướng các trang web, tải xuống nội dung và sau đó phân tích cú pháp để tìm dữ liệu hữu ích. Các công cụ này được thiết kế để mô phỏng hành vi của người dùng thực, chẳng hạn như theo liên kết, nhấp vào nút và điền vào biểu mẫu. Hầu hết các công cụ quét web đều dựa vào các ngôn ngữ lập trình như Python, Java hoặc Node.js, kết hợp với các thư viện như BeautifulSoup, Scrapy hoặc Puppeteer để trích xuất dữ liệu hiệu quả.
1. Gửi yêu cầu: Trình quét gửi yêu cầu HTTP đến máy chủ của trang web để truy xuất nội dung HTML của trang.
2. Phân tích cú pháp HTML: Sau khi truy xuất nội dung, trình quét sẽ phân tích cú pháp HTML để trích xuất dữ liệu mong muốn, chẳng hạn như văn bản, hình ảnh hoặc liên kết.
3. Trích xuất dữ liệu: Sau khi phân tích cú pháp, công cụ quét thu thập thông tin ở định dạng có cấu trúc, chẳng hạn như CSV, JSON hoặc cơ sở dữ liệu, để phân tích thêm.
Các ứng dụng của Web Scraping
Cạo web được sử dụng rộng rãi trong các ngành công nghiệp khác nhau cho các mục đích đa dạng. Một số ứng dụng phổ biến bao gồm:
- Nghiên cứu thị trường: Thu thập dữ liệu từ trang web của đối thủ cạnh tranh cho phép doanh nghiệp theo dõi giá cả, chương trình khuyến mãi và xu hướng thị trường, mang lại lợi thế cạnh tranh.
- SEO: Thu thập dữ liệu từ các trang kết quả của công cụ tìm kiếm (SERP) giúp các chuyên gia SEO phân tích thứ hạng từ khóa, liên kết ngược và chiến lược SEO của đối thủ cạnh tranh. Bạn có thể đọc thêm về quét web SEO tại đây.
- Giám sát mạng xã hội: Thu thập các nền tảng truyền thông xã hội giúp doanh nghiệp theo dõi các đề cập đến thương hiệu, phân tích cảm xúc và mức độ tương tác của khách hàng.
- Thương mại điện tử: Các trang web thương mại điện tử sử dụng web scraping để tổng hợp thông tin sản phẩm từ nhiều nguồn, so sánh giá cả và phân tích đánh giá của khách hàng.
Quét web đã trở thành một công cụ không thể thiếu để ra quyết định dựa trên dữ liệu. Tuy nhiên, với các biện pháp bảo vệ bot cạp ngày càng tăng, điều quan trọng là phải điều hướng quy trình quét web một cách có trách nhiệm và đảm bảo tuân thủ các tiêu chuẩn pháp lý và đạo đức.
Hiểu về bảo vệ Scraper Bot
Khi quét web trở nên phổ biến hơn, các trang web đã thực hiện nhiều biện pháp khác nhau để bảo vệ nội dung của họ và ngăn chặn các bot tự động trích xuất dữ liệu. Bảo vệ bot cạp bao gồm một loạt các kỹ thuật được thiết kế để phát hiện và chặn các hoạt động cạo, đảm bảo rằng chỉ những người dùng hợp pháp mới có thể truy cập dữ liệu.
Các kỹ thuật bảo vệ Scraper Bot phổ biến
Các trang web sử dụng kết hợp các giải pháp công nghệ để ngăn chặn các bot cạp. Bao gồm các:
- Chặn IP: Một trong những kỹ thuật phổ biến nhất là chặn địa chỉ IP của những người dùng đáng ngờ. Nếu một địa chỉ IP cụ thể gửi một lượng lớn yêu cầu bất thường trong một khoảng thời gian ngắn, nó có thể bị gắn cờ là bot quét và quyền truy cập của nó có thể bị hạn chế.
- CAPTCHA: Thử thách CAPTCHA (Thử nghiệm Turing công cộng hoàn toàn tự động để phân biệt máy tính và con người) được thiết kế để xác minh rằng người dùng là con người. Các bài kiểm tra này thường yêu cầu người dùng giải các câu đố, chẳng hạn như xác định các ký tự bị méo hoặc chọn hình ảnh cụ thể. Nhiều trang web sử dụng CAPTCHA để ngăn các công cụ quét truy cập vào các trang của họ.
- Giới hạn tốc độ: Các trang web thường giới hạn số lượng yêu cầu mà người dùng có thể thực hiện trong một khung thời gian nhất định. Điều này được gọi là giới hạn tốc độ. Nếu người dùng vượt quá số lượng yêu cầu cho phép, họ có thể tạm thời bị chặn hoặc điều chỉnh.
- Dấu vân tay trình duyệt: Kỹ thuật này thu thập thông tin về trình duyệt của người dùng, chẳng hạn như phiên bản, hệ điều hành và plugin. Nếu những chi tiết này khớp với các mẫu đã biết của bot cạp, trang web có thể chặn yêu cầu.
- Theo dõi phiên: Các trang web có thể theo dõi các phiên của người dùng thông qua cookie hoặc các mã định danh khác. Nếu một phiên dường như được tự động hóa hoặc thiếu hành vi điển hình của người dùng (chẳng hạn như di chuyển chuột hoặc nhấp chuột), phiên đó có thể bị gắn cờ và chặn.
- Honeypots: Honeypot là một cái bẫy do các trang web đặt ra để phát hiện các bot cạo. Đó là một trường hoặc liên kết ẩn mà người dùng sẽ không tương tác, nhưng những người quét có thể cố gắng truy cập. Nếu một bot cạp tương tác với honeypot, nó sẽ bị gắn cờ là đáng ngờ.
Tại sao những biện pháp bảo vệ này lại quan trọng
Những kỹ thuật này rất quan trọng trong việc bảo vệ dữ liệu của trang web, đảm bảo rằng chỉ những người dùng được ủy quyền mới có thể truy cập dữ liệu đó. Tuy nhiên, những biện pháp bảo vệ này cũng đặt ra thách thức cho những người quét web cần truy cập dữ liệu vì những lý do chính đáng, chẳng hạn như nghiên cứu thị trường hoặc phân tích cạnh tranh. Hiểu cách thức hoạt động của các biện pháp bảo vệ này và cách điều hướng chúng là chìa khóa để quét web có đạo đức.
Bằng cách sử dụng các chiến lược để vượt qua các biện pháp bảo vệ này một cách có trách nhiệm, các công cụ quét web có thể tiếp tục thu thập dữ liệu có giá trị trong khi vẫn tôn trọng các biện pháp bảo mật của trang web.
Các chiến lược để vượt qua bảo vệ Scraper Bot
Mặc dù các trang web sử dụng nhiều kỹ thuật khác nhau để bảo vệ dữ liệu của họ khỏi các bot cạp, nhưng có những chiến lược mà những người quét web có đạo đức có thể sử dụng để vượt qua các biện pháp bảo vệ này. Chìa khóa để vượt qua các biện pháp bảo vệ bot cạp này một cách có trách nhiệm là bắt chước hành vi hợp pháp của người dùng trong khi vẫn nằm trong ranh giới của các nguyên tắc pháp lý và đạo đức.
1. Sử dụng proxy
Một trong những cách hiệu quả nhất để vượt qua chặn IP là sử dụng proxy. Proxy hoạt động như trung gian giữa trình quét và trang web, che giấu địa chỉ IP thực của trình quét Điều này khiến các trang web khó xác định và chặn công cụ cạp hơn.
- Proxy luân phiên: Proxy luân phiên thay đổi địa chỉ IP với mỗi yêu cầu, giúp phân phối các yêu cầu trên nhiều IP. Điều này làm giảm khả năng kích hoạt các chặn IP.
- Proxy dân cư: Proxy dân cư sử dụng địa chỉ IP thực từ các mạng dân cư thực tế, khiến chúng ít có khả năng bị gắn cờ là bot. Chúng cung cấp tính ẩn danh cao hơn và có hiệu quả trong việc vượt qua chặn địa lý và CAPTCHA.
2. Bắt chước hành vi của con người
Các trang web sử dụng các kỹ thuật tiên tiến để phát hiện hành vi không phải của con người, chẳng hạn như nhấp chuột nhanh, tỷ lệ yêu cầu cao hoặc thiếu tương tác với các yếu tố của trang web. Bắt chước hành vi của con người là chìa khóa để tránh bị phát hiện.
- Độ trễ giữa các yêu cầu: Giới thiệu độ trễ ngẫu nhiên giữa các yêu cầu mô phỏng hành vi duyệt web của con người và tránh kích hoạt các biện pháp bảo vệ giới hạn tốc độ.
- Mô phỏng chuyển động chuột và nhấp chuột: Mô phỏng chuyển động chuột và nhấp chuột trên các trang web làm cho trình quét trông giống con người hơn.
3. Bỏ qua CAPTCHA
CAPTCHA là một rào cản lớn đối với các công cụ cạo, nhưng có nhiều cách để vượt qua chúng. Mặc dù giải CAPTCHA theo cách thủ công là một tùy chọn, nhưng có nhiều phương pháp tự động hơn có sẵn.
- Trình giải CAPTCHA: Các công cụ như 2Captcha và AntiCaptcha cung cấp dịch vụ để giải CAPTCHA tự động. Họ gửi hình ảnh CAPTCHA cho nhân viên con người giải quyết nó, cho phép các công cụ quét tiếp tục hoạt động của họ.
- Trình duyệt không đầu: Sử dụng các trình duyệt không đầu như Puppeteer đôi khi có thể bỏ qua CAPTCHA bằng cách làm cho hoạt động quét xuất hiện giống như một người dùng hợp pháp hơn. Các trình duyệt này chạy trong nền mà không cần GUI.
4. Giả mạo tác nhân người dùng
Các trang web thường theo dõi tác nhân người dùng để xác định bot. Scraper có thể tránh bị phát hiện bằng cách giả mạo chuỗi tác nhân người dùng để làm cho nó xuất hiện như thể yêu cầu đến từ một trình duyệt hợp pháp.
- Xoay vòng User-Agent: Bằng cách xoay vòng chuỗi user-agent cho mỗi yêu cầu, scraper có thể ngụy trang thành các thiết bị và trình duyệt khác nhau. Các công cụ như User-Agent Switcher có thể giúp đạt được điều này.
5. Sử dụng trình duyệt thân thiện với CAPTCHA
Một số công cụ cạo được thiết kế để xử lý các thử thách CAPTCHA trong thời gian thực. Ví dụ: DICloak cung cấp một trình duyệt chống phát hiện giúp vượt qua CAPTCHA và các cơ chế chống cạo khác bằng cách sử dụng các kỹ thuật nâng cao để làm cho trình quét trông giống như một người dùng thông thường.
6. Chế độ tàng hình
Chế độ tàng hình đề cập đến các kỹ thuật tiên tiến liên quan đến việc che dấu chân kỹ thuật số của máy cạp. Điều này bao gồm ẩn dấu vân tay, dữ liệu phiên và mã định danh thiết bị duy nhất của công cụ cạp.
Mặt nạ dấu vân tay của trình duyệt: Các công cụ như DICloak giúp cô lập dấu vân tay của trình duyệt, khiến các trang web khó theo dõi và chặn trình quét hơn.
Bằng cách sử dụng các chiến lược này, trình quét web có thể vượt qua các cơ chế bảo vệ bot quét thông thường một cách hiệu quả trong khi vẫn đảm bảo tuân thủ và thực hành đạo đức. Hiểu và thực hiện các phương pháp này sẽ giúp bạn duy trì tính ẩn danh trong quá trình thu thập dữ liệu và giảm nguy cơ bị phát hiện và chặn.
Các công cụ và công nghệ để quét web hiệu quả
Để thực hiện quét web một cách hiệu quả và hiệu quả, có nhiều công cụ và công nghệ khác nhau. Những công cụ này giúp tự động hóa quá trình cạo, xử lý các trang web phức tạp và đảm bảo rằng các công cụ quét vượt qua các biện pháp bảo vệ trong khi vẫn duy trì đạo đức và tuân thủ các tiêu chuẩn pháp lý.
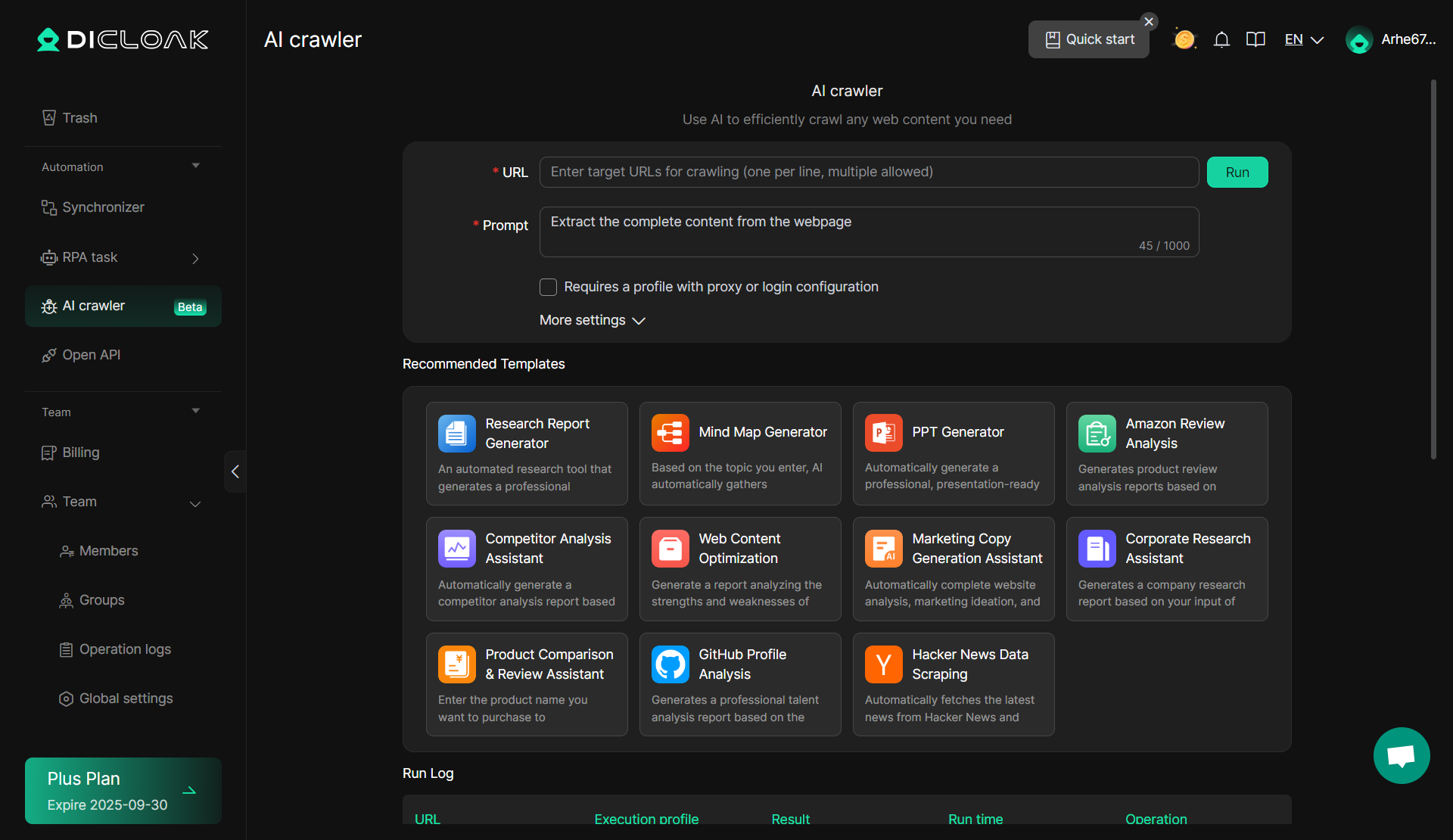
Đây là một công cụ đơn giản cho các nhu cầu cạo cơ bản và các doanh nghiệp đang tìm kiếm một giải pháp dễ sử dụng yêu cầu kiến thức kỹ thuật tối thiểu. Trình thu thập thông tin AI từ DICloak là một lựa chọn tuyệt vời.
DICloak: Trình thu thập thông tin AI
Một công cụ cạp đáng chú ý trong bộ của DICloak là Trình thu thập thông tin AI. Công cụ tích hợp này tận dụng trí tuệ nhân tạo để nâng cao trải nghiệm quét web , đặc biệt là khi xử lý các trang web động hoặc phức tạp. Trình thu thập thông tin AI bắt chước hành vi duyệt web của con người và có thể điều chỉnh theo các cấu hình web khác nhau, làm cho nó có hiệu quả cao trong việc vượt qua các hệ thống bảo vệ bot cạp. Nó có thể tự động thích ứng với các cấu trúc trang web khác nhau, cải thiện hiệu quả và tỷ lệ thành công của các tác vụ cạo.
- Ưu điểm: Trình thu thập thông tin AI tự động điều chỉnh theo cấu trúc trang web thay đổi và có thể vượt qua nhiều biện pháp bảo vệ chống quét phổ biến như CAPTCHA và chặn IP. Nó có hiệu quả cao cho việc cạo quy mô lớn và có thể xử lý nhiều tác vụ phức tạp mà không cần điều chỉnh thủ công liên tục.
- Không cần mã hóa: Chỉ cần nhập lời nhắc và bạn có thể bắt đầu cạo ngay lập tức — không cần kỹ năng viết mã.
- Cấu hình proxy và tài khoản: Dễ dàng định cấu hình proxy và tài khoản để thu thập sâu hơn vào dữ liệu nền tảng, nâng cao độ sâu của việc quét web của bạn và bỏ qua khả năng bảo vệ bot quét bằng cách bắt chước hành vi duyệt web của con người.
- 11 Mẫu dựng sẵn: Với 11 mẫu được cập nhật, Trình thu thập thông tin AI bao gồm nhiều tình huống và nhu cầu kinh doanh, cho phép thu thập dữ liệu nhanh chóng và hiệu quả.
- Nhiều trường hợp sử dụng: Trình thu thập thông tin AI hỗ trợ nhiều ứng dụng kinh doanh khác nhau, lý tưởng cho việc thu thập dữ liệu nhanh chóng, đơn giản giúp cải thiện hiệu quả hoạt động.
Nền tảng quét web chuyên nghiệp cho nhu cầu quét web quy mô lớn và nâng cao hơn, có một số nền tảng quét web chuyên nghiệp cung cấp nhiều khả năng kiểm soát, khả năng mở rộng và linh hoạt hơn.
Scrapy là một khung web mã nguồn mở được viết bằng Python. Nó được sử dụng rộng rãi để quét các trang web, trích xuất dữ liệu và lưu trữ nó ở nhiều định dạng khác nhau, chẳng hạn như JSON, CSV hoặc cơ sở dữ liệu. Scrapy đặc biệt thích hợp cho các tác vụ quét quy mô lớn, vì nó hỗ trợ thu thập dữ liệu nhiều trang đồng thời và các tính năng tích hợp của nó, chẳng hạn như xoay chuyển tác nhân người dùng, có thể giúp tránh bị phát hiện bởi hệ thống bảo vệ bot cạp. Đây là hướng dẫn.
- Ưu điểm: Nhanh, có thể mở rộng và hỗ trợ nhiều định dạng dữ liệu.
- Nhược điểm: Yêu cầu kiến thức lập trình để thiết lập và sử dụng.
BeautifulSoup là một thư viện Python giúp bạn dễ dàng thu thập dữ liệu từ các tệp HTML và XML. Nó được sử dụng tốt nhất cho các tác vụ cạo nhỏ hơn, nơi người dùng cần trích xuất dữ liệu từ một trang tĩnh hoặc các trang web đơn giản. Nó rất đơn giản để thiết lập và sử dụng, làm cho nó trở nên hoàn hảo cho người mới bắt đầu.
- Ưu điểm: Dễ sử dụng, tuyệt vời cho việc cạo quy mô nhỏ.
- Nhược điểm: Kém hiệu quả hơn đối với việc cạo quy mô lớn so với các framework như Scrapy.
Puppeteer là một thư viện Node.js cung cấp API cấp cao để điều khiển trình duyệt Chrome hoặc Chromium không đầu. Nó hữu ích để thu thập các trang web sử dụng JavaScript hoặc yêu cầu tương tác của người dùng (như nhấp vào nút hoặc điền vào biểu mẫu). Puppeteer có thể bỏ qua các kỹ thuật bảo vệ bot cạp phổ biến như CAPTCHA và đặc biệt hiệu quả để quét các trang web động.
- Ưu điểm: Xử lý các trang web nặng về JavaScript, mô phỏng hành vi giống con người.
- Nhược điểm: Chậm hơn so với các phương pháp cạo truyền thống.
Selenium là một công cụ phổ biến khác để tự động hóa trình duyệt. Nó có thể được sử dụng với nhiều ngôn ngữ lập trình khác nhau như Python, Java và C#. Selenium chủ yếu được sử dụng để kiểm tra các ứng dụng web, nhưng nó cũng rất hiệu quả cho các tác vụ quét web , đặc biệt là đối với các trang yêu cầu tương tác.
- Ưu điểm: Hoạt động với tất cả các trình duyệt web hiện đại và hỗ trợ nhiều ngôn ngữ.
- Nhược điểm: Yêu cầu nhiều tài nguyên hơn và có thể chậm hơn so với các công cụ không đầu như Puppeteer.
- Ưu điểm: Có thể mở rộng, dựa trên đám mây, hỗ trợ nhiều trường hợp sử dụng.
- Nhược điểm: Có thể tốn kém cho các hoạt động quy mô lớn.
Các công cụ và công nghệ này cung cấp một loạt các tính năng phục vụ cho các nhu cầu quét web khác nhau, từ các tác vụ quét đơn giản đến trích xuất dữ liệu quy mô lớn. Bằng cách chọn công cụ quét phù hợp, công cụ quét web có thể đảm bảo thu thập dữ liệu hiệu quả, có đạo đức và tuân thủ trong khi bỏ qua bảo vệ bot cạp thông thường.
Hạn chế của các công cụ này và cách cải thiện với DICloak
Mặc dù có nhiều công cụ và công nghệ có sẵn để quét web, nhưng chúng đi kèm với những hạn chế riêng. DICloak, với các tính năng chống phát hiện tiên tiến, có thể giúp vượt qua nhiều thách thức này, giúp quét web trở nên hiệu quả và an toàn.
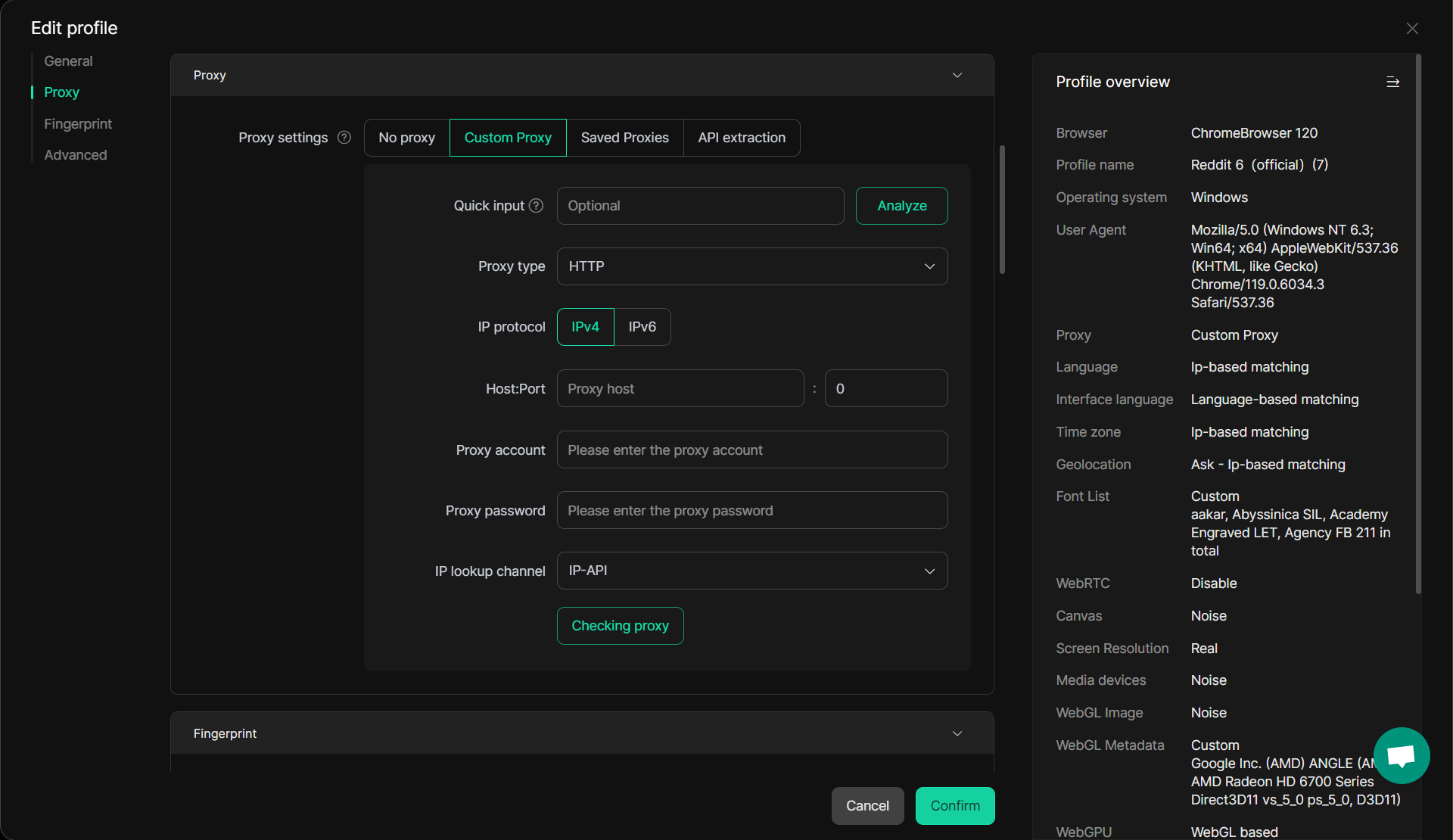
1. Vấn đề chặn IP và proxy
Nhiều công cụ quét web dựa vào proxy để vượt qua các hạn chế dựa trên IP. Tuy nhiên, việc sử dụng proxy đôi khi có thể dẫn đến hiệu suất chậm hơn hoặc tăng khả năng phát hiện bởi các cơ chế bảo vệ bot cạp. Các giải pháp proxy truyền thống có thể không thể ngụy trang hiệu quả các hoạt động cạo, đặc biệt là khi nhiều yêu cầu được gửi từ cùng một địa chỉ IP.
Giải pháp DICloak: DICloak giải quyết vấn đề này bằng cách cung cấp cấu hình proxy nâng cao, hỗ trợ proxy luân phiên và IP dân cư để đảm bảo duyệt web mượt mà và liền mạch. Khả năng chuyển đổi IP theo thời gian thực của nó khiến các trang web khó phát hiện và chặn trình quét hơn. Với DICloak, bạn có thể quản lý nhiều tài khoản và các tác vụ quét web mà không cần kích hoạt các biện pháp bảo mật như chặn IP.
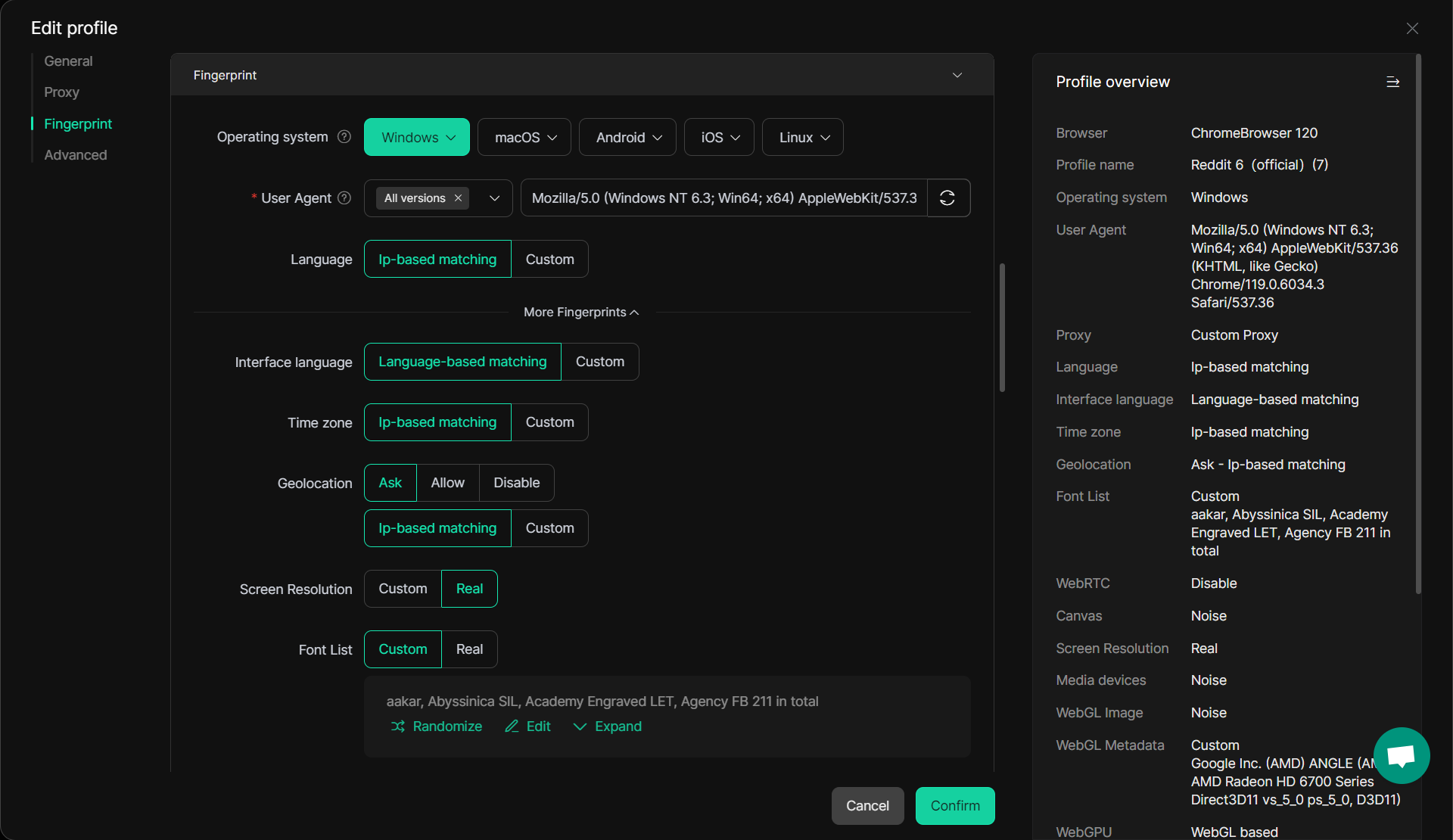
2. Phát hiện và lấy dấu vân tay của trình duyệt
Hầu hết các công cụ quét web truyền thống đều gặp khó khăn với dấu vân tay của trình duyệt, một kỹ thuật được các trang web sử dụng để xác định và chặn bot. Các công cụ này thường sử dụng chuỗi tác nhân người dùng tĩnh hoặc địa chỉ IP, giúp các trang web phát hiện và chặn các nỗ lực cạo dễ dàng hơn.
Giải pháp DICloak: DICloak cung cấp khả năng cách ly dấu vân tay trình duyệt phức tạp, đảm bảo rằng mỗi phiên quét xuất hiện dưới dạng một người dùng duy nhất với các dấu vân tay kỹ thuật số khác nhau. Bằng cách che giấu các mã định danh như độ phân giải màn hình, phông chữ và plugin, DICloak bắt chước hành vi duyệt web của con người, giảm khả năng bị phát hiện. Cách ly dấu vân tay này đặc biệt hữu ích để vượt qua các công nghệ chống cạo tinh vi. Đọc thêm về cách DICloak giúp cách ly dấu vân tay tại đây.
Ngoài các giải pháp hiệu quả mà DICloak cung cấp cho ba rủi ro nêu trên, DICloak AI Crawler là sự bổ sung hoàn hảo, khiến nó trở nên mạnh mẽ hơn. Khi bạn đang làm việc với các tác vụ quét web phức tạp, chuyên nghiệp, DICloak giúp bạn giảm thiểu rủi ro. Nhưng khi bạn cần thu thập dữ liệu một cách nhanh chóng và hiệu quả từ các nguồn đơn giản, DICloak sẽ bước vào để cải thiện hiệu quả của bạn.
Trình thu thập thông tin DICloak AI: Tăng cường bảo mật và tiện lợi
Trình thu thập thông tin AI của DICloak có thể cạo dữ liệu quy mô lớn một cách an toàn và hiệu quả mà không cần kích hoạt hệ thống phát hiện. Khả năng tự động điều chỉnh theo cấu trúc trang web thay đổi của nó làm cho nó hiệu quả cao đối với các trang web động, giảm nguy cơ bị phát hiện và chặn.
Các tính năng của trình thu thập thông tin DICloak AI:
- Không cần mã hóa: Chỉ cần nhập lời nhắc để bắt đầu quét ngay lập tức mà không cần mã hóa.
- Cấu hình proxy và tài khoản: Dễ dàng định cấu hình proxy và tài khoản để thu thập sâu hơn vào dữ liệu nền tảng, nâng cao độ sâu của quá trình quét web của bạn.
- 11 Mẫu dựng sẵn: Với 11 mẫu được cập nhật, Trình thu thập thông tin AI bao gồm nhiều tình huống và nhu cầu kinh doanh, cho phép thu thập dữ liệu nhanh chóng và hiệu quả.
- Nhiều trường hợp sử dụng: Trình thu thập thông tin AI hỗ trợ nhiều ứng dụng kinh doanh khác nhau, lý tưởng cho việc thu thập dữ liệu nhanh chóng, đơn giản giúp cải thiện hiệu quả hoạt động.
Câu hỏi thường gặp về Bỏ qua Bảo vệ Bot Scraper
Q1: Bảo vệ bot cạp là gì?
Bảo vệ bot cạp đề cập đến các kỹ thuật mà các trang web sử dụng để ngăn các bot tự động trích xuất dữ liệu. Chúng bao gồm các biện pháp như chặn IP, thử thách CAPTCHA, lấy dấu vân tay của trình duyệt và giới hạn tốc độ. Các trang web triển khai các biện pháp bảo vệ này để đảm bảo rằng chỉ những người dùng hợp pháp mới có thể truy cập nội dung và dữ liệu của họ, bảo vệ chống lại các hoạt động cạo độc hại.
Q2: Làm cách nào để vượt qua bảo vệ bot cạp một cách an toàn?
Để vượt qua bảo vệ bot cạp một cách có trách nhiệm, bạn có thể sử dụng các chiến lược như xoay proxy, mô phỏng hành vi của con người (ví dụ: thêm độ trễ giữa các yêu cầu), giả mạo chuỗi tác nhân người dùng và sử dụng trình giải CAPTCHA. Các phương pháp này cho phép bạn thực hiện quét web theo cách giảm thiểu rủi ro bị phát hiện và chặn, đảm bảo tuân thủ các tiêu chuẩn pháp lý và đạo đức.
Q3: Công cụ nào là tốt nhất để quét web?
Có một số công cụ cạo có sẵn để quét web hiệu quả, bao gồm:
- Scrapy: Một khuôn khổ nhanh, có thể mở rộng và mạnh mẽ để quét quy mô lớn.
- BeautifulSoup: Một công cụ đơn giản cho các nhiệm vụ cạo nhỏ hơn.
- Puppeteer: Tốt nhất để quét các trang web nặng về JavaScript.
- Selen: Tuyệt vời cho các trang yêu cầu tương tác của người dùng.
- DICloak: Một trình duyệt chống phát hiện giúp nâng cao hiệu quả quét bằng cách bỏ qua các hệ thống bảo vệ bot cạo thông thường.
Q4: DICloak giúp bảo vệ bot cạp như thế nào?
DICloak giúp vượt qua bảo vệ bot quét bằng cách cô lập dấu vân tay của trình duyệt, xoay IP và cung cấp cấu hình proxy nâng cao. Nó cho phép các công cụ quét web duy trì tính ẩn danh bằng cách ngăn các trang web phát hiện các hoạt động cạo. Ngoài ra, DICloak cung cấp khả năng quản lý phiên và có thể mô phỏng các tương tác giống như con người, giảm khả năng bị chặn hoặc gắn cờ là bot.
Q5: Bot cạp có thể được sử dụng cho mục đích đạo đức không?
Có, bot cạp có thể được sử dụng một cách có đạo đức cho các mục đích hợp pháp như nghiên cứu thị trường, phân tích đối thủ cạnh tranh và tổng hợp dữ liệu. Tuy nhiên, điều quan trọng là phải tuân theo các nguyên tắc pháp lý, tôn trọng các điều khoản dịch vụ của trang web và đảm bảo tuân thủ các biện pháp bảo vệ bot cạp. Quét web có đạo đức phải luôn tôn trọng quyền riêng tư và bảo mật của dữ liệu được cạo.
Q6: Tại sao việc quản lý các phiên cạo lại quan trọng?
Quản lý phiên và cookie là rất quan trọng trong việc quét web để đảm bảo rằng mỗi phiên được coi là một người dùng duy nhất. Quản lý phiên thích hợp ngăn các trang web theo dõi và chặn trình quét dựa trên cookie hoặc dữ liệu phiên được chia sẻ. DICloak vượt trội trong việc quản lý phiên, đảm bảo rằng các trình quét web có thể truy cập dữ liệu mà không kích hoạt các biện pháp bảo mật như cấm IP hoặc CAPTCHA.
Kết thúc
Tóm lại, quét web đã trở thành một công cụ mạnh mẽ để thu thập dữ liệu, cho phép doanh nghiệp có được thông tin chi tiết, theo dõi đối thủ cạnh tranh và cải thiện việc ra quyết định. Tuy nhiên, với sự gia tăng của các công nghệ bảo vệ bot cạp, việc điều hướng quy trình cạo một cách có trách nhiệm là điều cần thiết. Các công cụ như DICloak cung cấp các giải pháp nâng cao để vượt qua các biện pháp bảo vệ phổ biến như chặn IP, CAPTCHA và lấy dấu vân tay của trình duyệt, cho phép các trình quét web hoạt động với hiệu quả và bảo mật cao hơn.
Bằng cách sử dụng Trình thu thập thông tin AI của DICloak và các tính năng nâng cao khác, trình quét không chỉ có thể giảm rủi ro liên quan đến phát hiện và chặn mà còn hợp lý hóa quy trình cạo, cho phép thu thập dữ liệu nhanh hơn và chính xác hơn. Cho dù bạn đang giải quyết các nhiệm vụ quét phức tạp hay xử lý các nhu cầu trích xuất dữ liệu đơn giản hơn, DICloak đảm bảo tuân thủ các tiêu chuẩn pháp lý và đạo đức đồng thời cải thiện năng suất tổng thể.
Khi quét web tiếp tục đóng một vai trò quan trọng trong việc ra quyết định dựa trên dữ liệu, việc hiểu cách làm việc với các hệ thống bảo vệ bot cạp và sử dụng các công cụ phù hợp sẽ là chìa khóa để đảm bảo các hoạt động quét hiệu quả và có trách nhiệm.
 Công cụ miễn phí
Công cụ miễn phí Cookie Cắm -in
Cookie Cắm -in Trình tạo UA
Trình tạo UA Trình tạo địa chỉ MAC
Trình tạo địa chỉ MAC Trình tạo địa chỉ IP
Trình tạo địa chỉ IP Danh Sách Địa Chỉ IP
Danh Sách Địa Chỉ IP Trình tạo mã 2FA
Trình tạo mã 2FA Đồng Hồ Thế Giới
Đồng Hồ Thế Giới Kiểm tra ẩn danh
Kiểm tra ẩn danh WebRTC Leak Test
WebRTC Leak Test Trình tạo UUID
Trình tạo UUID Trình kiểm tra Proxy
Trình kiểm tra Proxy Kiểm tra FB Ads
Kiểm tra FB Ads Quét web bằng AI
Quét web bằng AI Công Cụ SMM Miễn Phí
Công Cụ SMM Miễn Phí Công Kiểm Tra Shadowban Twitter
Công Kiểm Tra Shadowban Twitter Công cụ Kiểm tra Tên Instagram
Công cụ Kiểm tra Tên Instagram Trình tạo UTM
Trình tạo UTM Trình tạo username
Trình tạo username Trinh tao hashtag AI
Trinh tao hashtag AI Trình tạo tiêu đề LinkedIn
Trình tạo tiêu đề LinkedIn Đổi kích thước ảnh mạng xã hội
Đổi kích thước ảnh mạng xã hội







