Have you ever wondered how real estate professionals get so much data? Or maybe you're a data enthusiast looking to dive into the vast world of property information. If so, you've likely heard of Zillow, one of the biggest online real estate marketplaces. Zillow has a treasure trove of data, from property listings to agent details. But how do you get this data for your own projects? The answer is web scraping.
Web scraping is like being a digital detective. You use special tools to collect information from websites. In this guide, we'll explore how to scrape Zillow info. We'll cover what data you can get, why it can be tricky, and how to overcome those challenges. We'll also look at popular tools and techniques, including how to easily scrape Zillow agents data. So, let's get started on this exciting journey of data discovery!
Zillow Scraping Targets and Content
Zillow is a goldmine of real estate data. When you scrape Zillow info, you can gather many types of data. This data can be very useful for market analysis, research, or even building your own real estate tools. Here are some key things you can scrape:
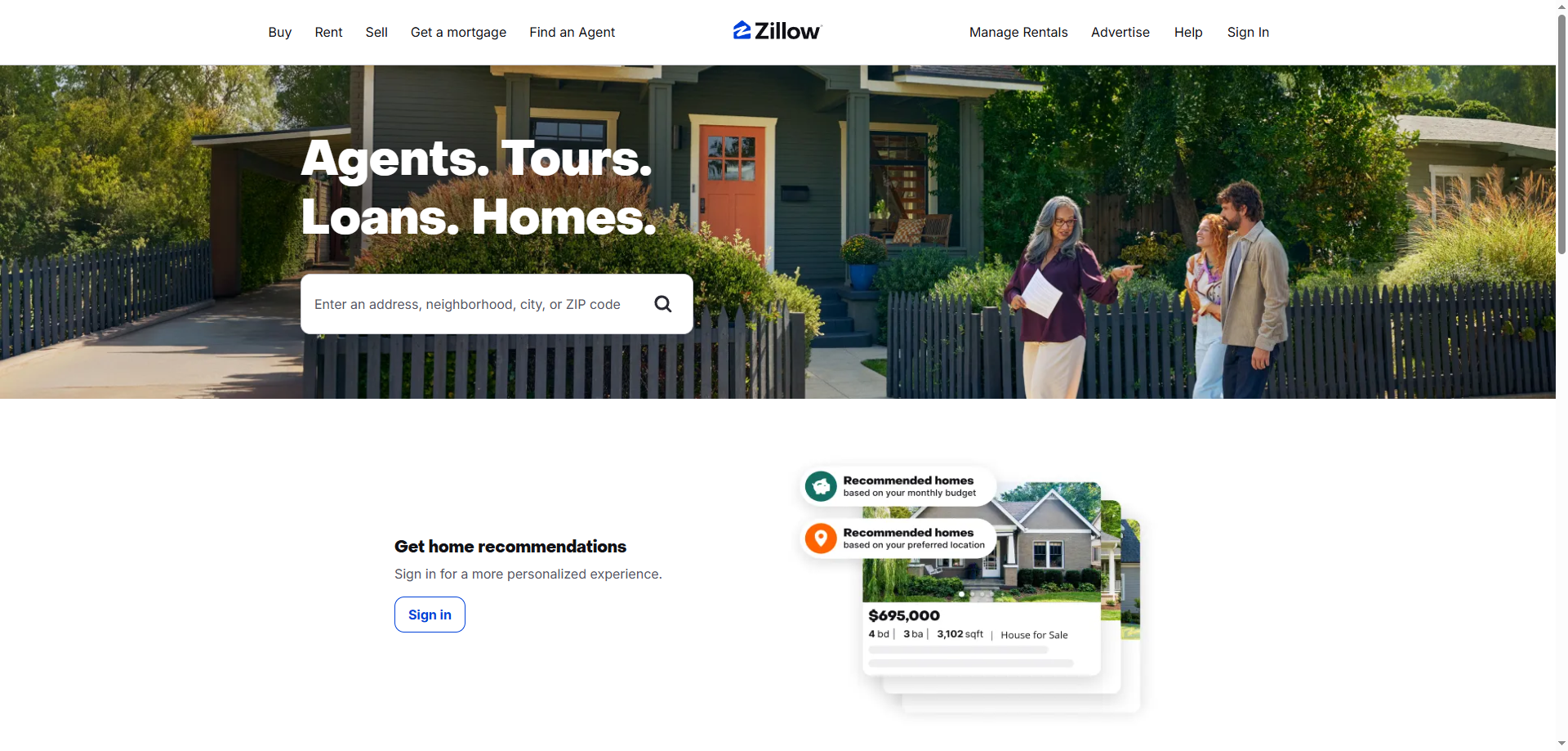
Property Listings
This is probably the most common target. Property listings include a lot of valuable information about homes for sale or rent. You can get details like:
•Addresses: The full street address of the property.
•Prices: The current asking price or rental price.
•Property Types: Is it a house, an apartment, a condo, or a townhouse?
•Bedrooms and Bathrooms: The number of bedrooms and bathrooms.
•Square Footage: The size of the property.
•Lot Size: The size of the land the property sits on.
•Property Descriptions: Detailed text descriptions of the home.
•Photos: Images of the interior and exterior of the property.
•Zestimate: Zillow's estimated market value for a home.
•Days on Zillow: How long the property has been listed on Zillow.
This information helps you understand market trends. It also helps you compare properties. You can see what homes are selling for in different areas. You can also track how long homes stay on the market.
Real Estate Agent Data
Zillow also lists many real estate agents. Scraping this data can be useful for networking or lead generation. You can often find:
•Agent Names: The full name of the real estate agent.
•Contact Information: Phone numbers and email addresses (if publicly available).
•Brokerage Information: The real estate company they work for.
•Agent Reviews and Ratings: What past clients say about their service.
•Listings by Agent: Which properties an agent is currently selling.
Knowing this helps you connect with agents. It also helps you understand their market presence. If you want to easy scrape Zillow agents data, you can focus on these specific details.
Why Scrape Zillow is Difficult
Now, you might be thinking, "This sounds great! I'll just start scraping." But hold on a minute. Scraping Zillow is not always easy. Zillow, like many large websites, has strong anti-scraping mechanisms in place. These are like digital security guards. They try to stop automated programs from collecting data. They do this to protect their data and ensure fair use of their platform.
So, why is scraping Zillow info difficult? Here are some common challenges:
•IP Blocking: Zillow can detect if many requests come from the same IP address in a short time. If they see this, they might block your IP address. This means you can't access the site anymore from that IP.
•CAPTCHAs: You might encounter CAPTCHAs. These are those little puzzles that ask you to prove you're not a robot. They are designed to stop automated scripts.
•Dynamic Content: Zillow uses a lot of JavaScript to load content. This means that when you first load a page, not all the data is there. It loads as you scroll or interact with the page. Traditional scrapers that just download the raw HTML might miss this data.
•Varying HTML Structures: The way Zillow's website is built can change. If the HTML structure changes, your scraping code might break. You'll need to update your code to match the new structure.
•User-Agent Checks: Websites often check your 'User-Agent' header. This tells them what browser and operating system you are using. If your scraper uses a generic or suspicious User-Agent, it might get blocked.
•Rate Limiting: Zillow might limit how many requests you can make in a certain period. If you send too many requests too quickly, they will temporarily block you.
These measures are in place to prevent abuse. They want to ensure their website runs smoothly for human users. This is why you need smart strategies to scrape Zillow info effectively and ethically.
Why Use Proxies to Scrape Zillow
Given Zillow's strong anti-scraping defenses, how can you still get the data you need? The answer often lies in using proxies. Proxies act as middlemen between your computer and the website you're trying to scrape. When you use a proxy, your request to Zillow doesn't come directly from your IP address. Instead, it comes from the proxy's IP address.
This is very helpful for several reasons:
•Bypass IP Blocks: If Zillow blocks one IP address, you can switch to another proxy IP. This allows you to continue scraping without interruption. It's like having many different disguises.
•Distribute Requests: You can send requests through many different proxies. This makes it look like many different users are accessing Zillow. This helps you avoid hitting rate limits.
•Access Geo-Restricted Content: Sometimes, certain data or features on Zillow might only be available in specific locations. Proxies allow you to appear as if you are browsing from that location.
•Maintain Anonymity: Proxies add a layer of anonymity to your scraping activities. This can be important for privacy and security.
So, using proxies is a key strategy to successfully scrape Zillow info at scale. They help you avoid detection and ensure a smooth data collection process.
Residential vs. Datacenter Proxies
When you decide to use proxies, you'll quickly learn there are different types. The two main types are residential proxies and datacenter proxies. Each has its own strengths and weaknesses, especially when it comes to scraping a site like Zillow.
Datacenter Proxies
Datacenter proxies are IP addresses that come from cloud servers or data centers. They are often very fast and cheap. They are good for tasks that need high speed and a lot of bandwidth. However, they have a big drawback: websites can easily detect them. This is because their IP addresses are known to belong to data centers, not real internet service providers (ISPs).
•Pros: Fast, affordable, high bandwidth.
•Cons: Easily detected by sophisticated anti-scraping systems, higher chance of getting blocked by Zillow.
Residential Proxies
Residential proxies are IP addresses that belong to real residential users. They are provided by actual ISPs. This means they look like regular internet users to websites. Because of this, they are much harder for websites like Zillow to detect and block.
•Pros: Very hard to detect, lower chance of getting blocked, appear as real users, good for geo-targeting.
•Cons: More expensive, can be slower than datacenter proxies.
For scraping Zillow, residential proxies are usually the better choice. They offer a higher success rate because they blend in better with normal user traffic. While they cost more, the investment often pays off in terms of successful data collection and fewer blocks. This is especially true if you want to easy scrape Zillow agents or property listings without constant interruptions.
How to Scrape Zillow with Python
Python is a very popular language for web scraping. It has many powerful libraries that make the job easier. When you want to scrape Zillow info using Python, you'll often hear about tools like BeautifulSoup and Scrapy. Let's look at how these can help you.
Using BeautifulSoup for Simple Scraping
BeautifulSoup is a Python library for pulling data out of HTML and XML files. It's great for simple scraping tasks. It helps you navigate, search, and modify the parse tree. Think of it as a tool that helps you find specific pieces of information on a web page.
Here's a very basic idea of how you might use BeautifulSoup:
1.Make a Request: First, you need to get the HTML content of the Zillow page. You can use the requests library in Python for this. It sends a request to the Zillow server and gets the page's HTML.
2.Parse the HTML: Once you have the HTML, you pass it to BeautifulSoup. BeautifulSoup then turns it into a tree-like structure. This structure makes it easy to find elements.
3.Find Data: You can then use BeautifulSoup's methods to find specific elements. For example, you can look for all property titles, prices, or addresses. You do this by looking at the HTML tags and classes.
Example (Conceptual Code - Not for direct execution on Zillow due to anti-scraping):
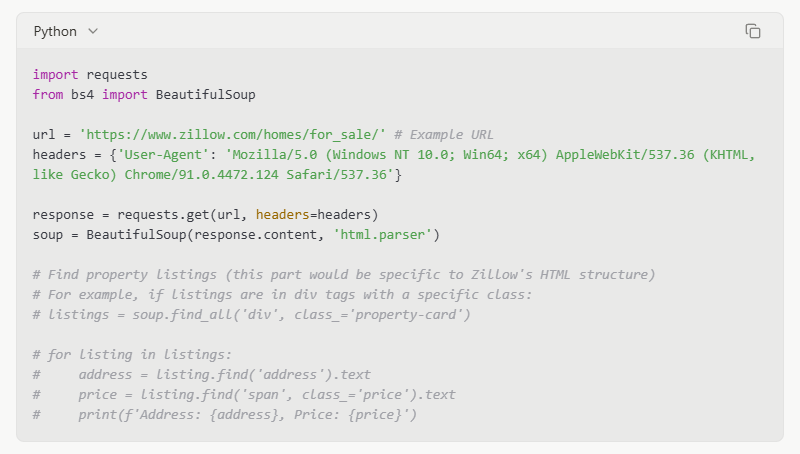
Note: The above code is a simplified example. Zillow's website is complex and uses dynamic content. Direct requests and simple parsing with BeautifulSoup might not get all the data. You would need to handle JavaScript rendering and other anti-scraping measures.
Using Scrapy for Advanced Scraping
For more complex and large-scale scraping projects, Scrapy is a better choice. Scrapy is a powerful Python framework for web crawling and scraping. It handles many things automatically, like making requests, handling cookies, and managing sessions. It's built for speed and efficiency.
Scrapy works by defining
'spiders'. These are classes that you write to define how to crawl a site and extract data. Scrapy can also handle concurrent requests, which means it can scrape many pages at once. This makes it much faster for large projects.
Key features of Scrapy:
•Robustness: It can handle broken HTML and various network issues.
•Scalability: Designed for large-scale data extraction.
•Middleware: Allows you to customize how requests are sent and responses are processed. This is where you can integrate proxies and handle user-agent rotation.
•Pipelines: Used to process the scraped data, such as cleaning it, validating it, and saving it to a database or file.
While Scrapy is more complex to set up than BeautifulSoup, it offers much more control and power for serious scraping tasks. If you plan to scrape Zillow info regularly and at a large scale, learning Scrapy is a worthwhile investment.
Other Tools and Considerations
Beyond BeautifulSoup and Scrapy, other tools and techniques can help:
•Selenium/Playwright: These are browser automation tools. They can control a real web browser. This is useful for scraping dynamic content that loads with JavaScript. They can click buttons, fill forms, and scroll pages, just like a human user. However, they are slower and use more resources.
•Headless Browsers: These are web browsers without a graphical user interface. They are often used with Selenium or Playwright to automate browser interactions in the background.
•API Scraping: Sometimes, websites have hidden APIs (Application Programming Interfaces) that they use to load data. If you can find and understand these APIs, you can often get data directly, which is much faster and more reliable than scraping HTML.
Remember, when using any of these tools to scrape Zillow info, you must always be mindful of Zillow's terms of service and legal considerations. Ethical scraping is important.
As we've discussed, Zillow's anti-scraping measures are sophisticated. They can detect traditional scraping methods. This is where advanced tools like the DICloak Antidetect Browser come into play. This browser is not just a regular web browser. It's designed to help you manage multiple online accounts with maximum anonymity. It does this by making your digital fingerprint unique and hard to detect.
Think of your digital fingerprint as a unique set of characteristics that websites can use to identify you. This includes your browser type, operating system, screen resolution, and even how you move your mouse. DICloak Antidetect Browser helps you create and manage many different, unique digital fingerprints. This makes it much harder for Zillow to link your scraping activities together and block you.
But DICloak offers even more. It has a powerful built-in RPA (Robotic Process Automation) feature. RPA allows you to automate repetitive tasks. You can record a series of actions you take in the browser, like navigating to a page, clicking on elements, or filling out forms. Then, you can play back these actions automatically. This is incredibly useful for scraping Zillow because:
•Mimics Human Behavior: RPA can simulate human-like interactions. This makes your scraping activities look more natural to Zillow's anti-bot systems. It can handle scrolling, delays, and clicks in a way that a simple script cannot.
•Handles Dynamic Content: Since RPA works by controlling a real browser, it can easily handle dynamic content loaded by JavaScript. It waits for elements to appear before interacting with them.
•Customizable Workflows: You can create custom RPA workflows to fit your specific scraping needs. For example, you can set up a workflow to visit property listings, extract specific data points, and then move to the next listing. This can help you easy scrape Zillow agents data or property details with precision.
If you're serious about scraping Zillow info and want a robust solution that can bypass advanced anti-scraping mechanisms, the DICloak Antidetect Browser with its RPA capabilities is a game-changer. It provides a powerful and flexible way to automate your data collection. If you are interested in using DICloak Antidetect Browser to customize RPA processes for scraping Zillow information, you can contact their customer service to tailor specific RPA scraping functions for your needs.
Conclusion
Scraping Zillow information can be a powerful way to gather valuable real estate data. However, it comes with its challenges. Zillow has strong anti-scraping measures. These include IP blocking, CAPTCHAs, and dynamic content. But with the right tools and strategies, you can overcome these hurdles.
Using proxies, especially residential proxies, is key to bypassing IP blocks and maintaining anonymity. Python libraries like BeautifulSoup and Scrapy offer robust solutions for data extraction. For more advanced and reliable scraping, especially when dealing with complex anti-bot systems, tools like the DICloak Antidetect Browser with its RPA functionality provide a significant advantage. They help you mimic human behavior and handle dynamic content effectively.
Remember, always scrape responsibly and ethically. Respect Zillow's terms of service. With the knowledge and tools discussed in this guide, you are well-equipped to scrape Zillow info and unlock the vast potential of real estate data. Whether you want to easy scrape Zillow agents or detailed property listings, the journey starts here.
 Web Proxy Tools
Web Proxy Tools Free Tools
Free Tools Cookie Plugin
Cookie Plugin UA Generator
UA Generator MAC Address Generator
MAC Address Generator IP Generator
IP Generator IP Address List
IP Address List 2FA Code Generator
2FA Code Generator World Clock
World Clock Anonymous Check
Anonymous Check WebRTC Leak Test
WebRTC Leak Test UUID Generator
UUID Generator Free Web Proxy Site
Free Web Proxy Site Proxy Checker
Proxy Checker FB Ad Checker
FB Ad Checker AI Web Scraping
AI Web Scraping Free SMM Tools
Free SMM Tools Twitter Shadowban Checker
Twitter Shadowban Checker Instagram Name Checker
Instagram Name Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator LinkedIn Headline Generator
LinkedIn Headline Generator Social Media Image Resizer
Social Media Image Resizer







