Você já se perguntou como os profissionais de imóveis obtêm tantos dados? Ou talvez você seja um entusiasta de dados querendo mergulhar no vasto mundo das informações sobre propriedades. Se sim, você provavelmente já ouviu falar do Zillow, um dos maiores marketplaces de imóveis online. O Zillow possui um tesouro de dados, desde listagens de propriedades até detalhes de agentes. Mas como você obtém esses dados para seus próprios projetos? A resposta é web scraping.
Web scraping é como ser um detetive digital. Você usa ferramentas especiais para coletar informações de sites. Neste guia, vamos explorar como raspar informações do Zillow. Vamos abordar quais dados você pode obter, por que isso pode ser complicado e como superar esses desafios. Também vamos olhar para ferramentas e técnicas populares, incluindo como raspar facilmente os dados dos agentes do Zillow. Então, vamos começar esta empolgante jornada de descoberta de dados!
Zillow Alvos e Conteúdo de Scraping
O Zillow é uma mina de ouro de dados imobiliários. Quando você raspa informações do Zillow, pode coletar muitos tipos de dados. Esses dados podem ser muito úteis para análise de mercado, pesquisa ou até mesmo para construir suas próprias ferramentas imobiliárias. Aqui estão algumas coisas-chave que você pode raspar:
Listagens de Propriedades
Este é provavelmente o alvo mais comum. As listagens de propriedades incluem muitas informações valiosas sobre casas à venda ou para alugar. Você pode obter detalhes como:
•Endereços: O endereço completo da propriedade.
•Preços: O preço atual de venda ou aluguel.
•Tipos de Propriedade: É uma casa, um apartamento, um condomínio ou uma casa geminada?
•Quartos e Banheiros: O número de quartos e banheiros.
•Metros Quadrados: O tamanho da propriedade.
•Tamanho do Lote: O tamanho do terreno onde a propriedade está situada.
•Descrições da Propriedade: Descrições textuais detalhadas da casa.
•Fotos: Imagens do interior e exterior da propriedade.
•Zestimate: O valor de mercado estimado pela Zillow para uma casa.
•Dias na Zillow: Quanto tempo a propriedade está listada na Zillow.
Essas informações ajudam você a entender as tendências do mercado. Também ajudam você a comparar propriedades. Você pode ver por quanto as casas estão sendo vendidas em diferentes áreas. Você também pode acompanhar quanto tempo as casas permanecem no mercado.
Dados de Agentes Imobiliários
A Zillow também lista muitos agentes imobiliários. Coletar esses dados pode ser útil para networking ou geração de leads. Você pode frequentemente encontrar:
•Nomes dos Agentes: O nome completo do agente imobiliário.
•Informações de Contato: Números de telefone e endereços de e-mail (se disponíveis publicamente).
•Informações da Corretora: A empresa imobiliária para a qual eles trabalham.
•Avaliações e Classificações dos Agentes: O que os clientes anteriores dizem sobre o serviço deles.
•Listagens por Agente: Quais propriedades um agente está vendendo atualmente.
Saber disso ajuda você a se conectar com os agentes. Também ajuda você a entender a presença deles no mercado. Se você quiser coletar dados de agentes da Zillow de forma fácil, pode se concentrar nesses detalhes específicos.
Por que Coletar Dados da Zillow é Difícil
Agora, você pode estar pensando: "Isso soa ótimo! Vou apenas começar a fazer scraping." Mas espere um minuto. Fazer scraping do Zillow nem sempre é fácil. O Zillow, como muitos grandes sites, possui fortes mecanismos anti-scraping. Eles são como guardas de segurança digitais. Eles tentam impedir que programas automatizados coletem dados. Eles fazem isso para proteger seus dados e garantir o uso justo de sua plataforma.
Então, por que é difícil fazer scraping das informações do Zillow? Aqui estão alguns desafios comuns:
•Bloqueio de IP: O Zillow pode detectar se muitos pedidos vêm do mesmo endereço IP em um curto período de tempo. Se eles perceberem isso, podem bloquear seu endereço IP. Isso significa que você não poderá mais acessar o site a partir desse IP.
•CAPTCHAs: Você pode encontrar CAPTCHAs. Esses são aqueles pequenos quebra-cabeças que pedem para você provar que não é um robô. Eles são projetados para impedir scripts automatizados.
•Conteúdo Dinâmico: O Zillow usa muito JavaScript para carregar conteúdo. Isso significa que, quando você carrega uma página pela primeira vez, nem todos os dados estão lá. Eles são carregados à medida que você rola ou interage com a página. Scrapers tradicionais que apenas baixam o HTML bruto podem perder esses dados.
•Estruturas HTML Variáveis: A forma como o site do Zillow é construído pode mudar. Se a estrutura HTML mudar, seu código de scraping pode quebrar. Você precisará atualizar seu código para corresponder à nova estrutura.
•Verificações de User-Agent: Os sites costumam verificar seu cabeçalho 'User-Agent'. Isso informa a eles qual navegador e sistema operacional você está usando. Se seu scraper usar um User-Agent genérico ou suspeito, ele pode ser bloqueado.
•Limitação de Taxa: O Zillow pode limitar quantas solicitações você pode fazer em um determinado período. Se você enviar muitas solicitações muito rapidamente, eles irão bloqueá-lo temporariamente.
Essas medidas estão em vigor para prevenir abusos. Eles querem garantir que seu site funcione sem problemas para usuários humanos. É por isso que você precisa de estratégias inteligentes para extrair informações do Zillow de forma eficaz e ética.
Por que Usar Proxies para Extrair Dados do Zillow
Dadas as fortes defesas anti-extracção do Zillow, como você ainda pode obter os dados de que precisa? A resposta muitas vezes está em usar proxies. Proxies atuam como intermediários entre seu computador e o site que você está tentando extrair. Quando você usa um proxy, sua solicitação ao Zillow não vem diretamente do seu endereço IP. Em vez disso, vem do endereço IP do proxy.
Isso é muito útil por várias razões:
•Contornar Bloqueios de IP: Se o Zillow bloquear um endereço IP, você pode mudar para outro IP de proxy. Isso permite que você continue a extrair dados sem interrupção. É como ter muitos disfarces diferentes.
•Distribuir Solicitações: Você pode enviar solicitações através de muitos proxies diferentes. Isso faz parecer que muitos usuários diferentes estão acessando o Zillow. Isso ajuda você a evitar atingir os limites de taxa.
•Acessar Conteúdo Geo-Restrito: Às vezes, certos dados ou recursos no Zillow podem estar disponíveis apenas em locais específicos. Proxies permitem que você pareça estar navegando a partir desse local.
•Manter Anonimato: Proxies adicionam uma camada de anonimato às suas atividades de extração. Isso pode ser importante para privacidade e segurança.
Portanto, usar proxies é uma estratégia chave para coletar informações do Zillow em grande escala com sucesso. Eles ajudam a evitar a detecção e garantem um processo de coleta de dados suave.
Proxies Residenciais vs. Proxies de Datacenter
Quando você decide usar proxies, rapidamente aprenderá que existem diferentes tipos. Os dois principais tipos são proxies residenciais e proxies de datacenter. Cada um tem suas próprias forças e fraquezas, especialmente quando se trata de coletar dados de um site como o Zillow.
Proxies de Datacenter
Proxies de datacenter são endereços IP que vêm de servidores em nuvem ou datacenters. Eles costumam ser muito rápidos e baratos. São bons para tarefas que precisam de alta velocidade e muita largura de banda. No entanto, eles têm uma grande desvantagem: os sites podem detectá-los facilmente. Isso ocorre porque seus endereços IP são conhecidos por pertencer a datacenters, e não a provedores de serviços de internet (ISPs) reais.
•Prós: Rápidos, acessíveis, alta largura de banda.
•Contras: Facilmente detectados por sistemas sofisticados de anti-scraping, maior chance de serem bloqueados pelo Zillow.
Proxies Residenciais
Proxies residenciais são endereços IP que pertencem a usuários residenciais reais. Eles são fornecidos por ISPs reais. Isso significa que eles parecem usuários normais da internet para os sites. Por causa disso, são muito mais difíceis de detectar e bloquear por sites como o Zillow.
•Prós: Muito difíceis de detectar, menor chance de serem bloqueados, aparecem como usuários reais, bons para geo-targeting.
•Contras: Mais caros, podem ser mais lentos do que proxies de datacenter.
Para fazer scraping do Zillow, proxies residenciais são geralmente a melhor escolha. Eles oferecem uma taxa de sucesso mais alta porque se misturam melhor com o tráfego normal de usuários. Embora custem mais, o investimento muitas vezes compensa em termos de coleta de dados bem-sucedida e menos bloqueios. Isso é especialmente verdadeiro se você quiser fazer scraping fácil de agentes do Zillow ou listagens de propriedades sem interrupções constantes.
Como Fazer Scraping do Zillow com Python
Python é uma linguagem muito popular para web scraping. Ela possui muitas bibliotecas poderosas que facilitam o trabalho. Quando você deseja fazer scraping de informações do Zillow usando Python, frequentemente ouvirá sobre ferramentas como BeautifulSoup e Scrapy. Vamos ver como essas podem ajudar você.
Usando BeautifulSoup para Scraping Simples
BeautifulSoup é uma biblioteca Python para extrair dados de arquivos HTML e XML. É ótima para tarefas de scraping simples. Ela ajuda você a navegar, pesquisar e modificar a árvore de análise. Pense nisso como uma ferramenta que ajuda você a encontrar peças específicas de informação em uma página da web.
Aqui está uma ideia muito básica de como você pode usar o BeautifulSoup:
1.Faça um Pedido: Primeiro, você precisa obter o conteúdo HTML da página do Zillow. Você pode usar a biblioteca requests em Python para isso. Ela envia um pedido ao servidor do Zillow e obtém o HTML da página.
2.Analyze o HTML: Uma vez que você tenha o HTML, você o passa para o BeautifulSoup. O BeautifulSoup então o transforma em uma estrutura semelhante a uma árvore. Essa estrutura facilita a localização de elementos.
3.Encontrar Dados: Você pode então usar os métodos do BeautifulSoup para encontrar elementos específicos. Por exemplo, você pode procurar todos os títulos de propriedades, preços ou endereços. Você faz isso observando as tags e classes HTML.
Exemplo (Código Conceitual - Não para execução direta no Zillow devido a medidas anti-scraping):
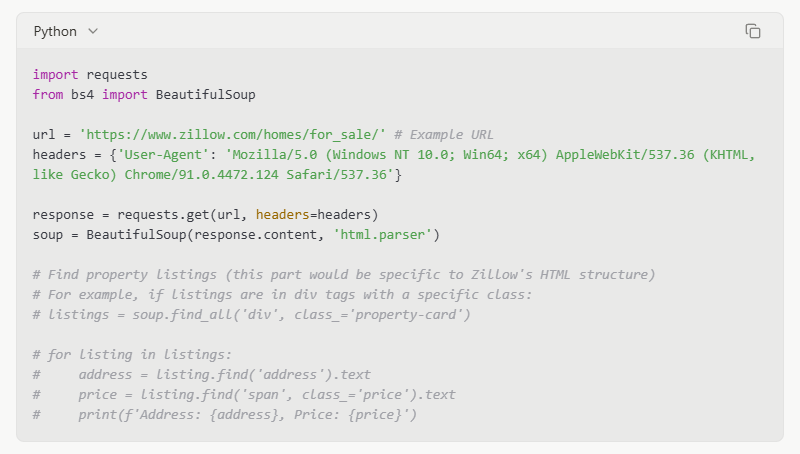
Nota: O código acima é um exemplo simplificado. O site do Zillow é complexo e utiliza conteúdo dinâmico. Solicitações diretas e análise simples com BeautifulSoup podem não obter todos os dados. Você precisaria lidar com a renderização de JavaScript e outras medidas anti-scraping.
Usando Scrapy para Scraping Avançado
Para projetos de scraping mais complexos e em grande escala, Scrapy é uma escolha melhor. Scrapy é um poderoso framework Python para rastreamento e scraping da web. Ele lida com muitas coisas automaticamente, como fazer solicitações, gerenciar cookies e administrar sessões. É construído para velocidade e eficiência.
Scrapy funciona definindo
'aranhas'. Estas são classes que você escreve para definir como rastrear um site e extrair dados. Scrapy também pode lidar com solicitações concorrentes, o que significa que pode raspar muitas páginas ao mesmo tempo. Isso o torna muito mais rápido para grandes projetos.
Principais características do Scrapy:
•Robustez: Pode lidar com HTML quebrado e vários problemas de rede.
•Escalabilidade: Projetado para extração de dados em grande escala.
•Middleware: Permite personalizar como as solicitações são enviadas e como as respostas são processadas. É aqui que você pode integrar proxies e gerenciar a rotação de user-agents.
•Pipelines: Usados para processar os dados extraídos, como limpá-los, validá-los e salvá-los em um banco de dados ou arquivo.
Embora o Scrapy seja mais complexo de configurar do que o BeautifulSoup, ele oferece muito mais controle e poder para tarefas de scraping sérias. Se você planeja extrair informações do Zillow regularmente e em grande escala, aprender Scrapy é um investimento que vale a pena.
Outras Ferramentas e Considerações
Além do BeautifulSoup e do Scrapy, outras ferramentas e técnicas podem ajudar:
•Selenium/Playwright: Estas são ferramentas de automação de navegador. Elas podem controlar um navegador da web real. Isso é útil para extrair conteúdo dinâmico que carrega com JavaScript. Elas podem clicar em botões, preencher formulários e rolar páginas, assim como um usuário humano. No entanto, são mais lentas e usam mais recursos.
•Navegadores Sem Cabeça: Estes são navegadores da web sem uma interface gráfica de usuário. Eles são frequentemente usados com Selenium ou Playwright para automatizar interações do navegador em segundo plano.
•API Scraping: Às vezes, os sites têm APIs ocultas (Interfaces de Programação de Aplicações) que usam para carregar dados. Se você conseguir encontrar e entender essas APIs, muitas vezes pode obter dados diretamente, o que é muito mais rápido e confiável do que extrair HTML.
Lembre-se, ao usar qualquer uma dessas ferramentas para extrair informações do Zillow, você deve sempre estar atento aos termos de serviço do Zillow e às considerações legais. O scraping ético é importante.
Como discutimos, as medidas anti-scraping do Zillow são sofisticadas. Elas podem detectar métodos tradicionais de scraping. É aqui que entram ferramentas avançadas como o DICloak Antidetect Browser. Este navegador não é apenas um navegador web comum. Ele foi projetado para ajudar você a gerenciar várias contas online com o máximo de anonimato. Ele faz isso tornando sua impressão digital única e difícil de detectar.
Pense na sua impressão digital digital como um conjunto único de características que os sites podem usar para identificá-lo. Isso inclui o tipo de navegador, sistema operacional, resolução de tela e até mesmo como você move o mouse. O DICloak Antidetect Browser ajuda você a criar e gerenciar muitas impressões digitais digitais diferentes e únicas. Isso torna muito mais difícil para o Zillow vincular suas atividades de scraping e bloqueá-lo.
Mas o DICloak oferece ainda mais. Ele possui um poderoso recurso de RPA (Automação de Processos Robóticos) embutido. O RPA permite que você automatize tarefas repetitivas. Você pode gravar uma série de ações que realiza no navegador, como navegar até uma página, clicar em elementos ou preencher formulários. Em seguida, você pode reproduzir essas ações automaticamente. Isso é incrivelmente útil para fazer scraping do Zillow porque:
•Imita o Comportamento Humano: RPA pode simular interações semelhantes às humanas. Isso faz com que suas atividades de scraping pareçam mais naturais para os sistemas anti-bot do Zillow. Ele pode lidar com rolagem, atrasos e cliques de uma maneira que um simples script não consegue.
•Lida com Conteúdo Dinâmico: Como o RPA funciona controlando um navegador real, ele pode facilmente lidar com conteúdo dinâmico carregado por JavaScript. Ele espera que os elementos apareçam antes de interagir com eles.
•Fluxos de Trabalho Personalizáveis: Você pode criar fluxos de trabalho RPA personalizados para atender às suas necessidades específicas de scraping. Por exemplo, você pode configurar um fluxo de trabalho para visitar listagens de propriedades, extrair pontos de dados específicos e, em seguida, passar para a próxima listagem. Isso pode ajudá-lo a coletar dados de agentes do Zillow ou detalhes de propriedades com precisão.
Se você está sério sobre coletar informações do Zillow e deseja uma solução robusta que possa contornar mecanismos avançados de anti-scraping, o DICloak Antidetect Browser com suas capacidades de RPA é um divisor de águas. Ele fornece uma maneira poderosa e flexível de automatizar sua coleta de dados. Se você estiver interessado em usar o DICloak Antidetect Browser para personalizar processos de RPA para coletar informações do Zillow, você pode entrar em contato com o serviço de atendimento ao cliente deles para adaptar funções específicas de scraping RPA às suas necessidades.
Conclusão
Coletar informações do Zillow pode ser uma maneira poderosa de reunir dados valiosos sobre imóveis. No entanto, isso vem com seus desafios. O Zillow possui fortes medidas de anti-scraping. Isso inclui bloqueio de IP, CAPTCHAs e conteúdo dinâmico. Mas com as ferramentas e estratégias certas, você pode superar esses obstáculos.
Usar proxies, especialmente proxies residenciais, é fundamental para contornar bloqueios de IP e manter a anonimidade. Bibliotecas Python como BeautifulSoup e Scrapy oferecem soluções robustas para extração de dados. Para uma raspagem mais avançada e confiável, especialmente ao lidar com sistemas complexos de anti-bot, ferramentas como o DICloak Antidetect Browser com sua funcionalidade RPA oferecem uma vantagem significativa. Elas ajudam você a imitar o comportamento humano e lidar com conteúdo dinâmico de forma eficaz.
Lembre-se, sempre raspagem de forma responsável e ética. Respeite os termos de serviço do Zillow. Com o conhecimento e as ferramentas discutidas neste guia, você está bem equipado para raspar informações do Zillow e desbloquear o vasto potencial dos dados imobiliários. Se você deseja raspar facilmente agentes do Zillow ou listagens detalhadas de propriedades, a jornada começa aqui.
 Ferramentas Gratuitas
Ferramentas Gratuitas Cookie Plugin
Cookie Plugin Gerador de UA
Gerador de UA Gerador de Endereço MAC
Gerador de Endereço MAC Gerador de Endereço IP
Gerador de Endereço IP Lista de Endereços IP
Lista de Endereços IP Gerador de Código 2FA
Gerador de Código 2FA Relógio Mundial
Relógio Mundial Verificação de Anonimato
Verificação de Anonimato WebRTC Leak Test
WebRTC Leak Test Gerador de UUID
Gerador de UUID Verificador de Proxy
Verificador de Proxy Verificador de Anúncios FB
Verificador de Anúncios FB Coleta Web com IA
Coleta Web com IA Ferramentas SMM Grátis
Ferramentas SMM Grátis Verificador de Shadowban do Twitter
Verificador de Shadowban do Twitter Verificador de Nomes do Instagram
Verificador de Nomes do Instagram Gerador UTM
Gerador UTM Gerador de nomes de usuário
Gerador de nomes de usuário Gerador de hashtags com IA
Gerador de hashtags com IA Gerador de títulos para LinkedIn
Gerador de títulos para LinkedIn Redimensionador de imagens sociais
Redimensionador de imagens sociais







