Vous êtes-vous déjà demandé comment les professionnels de l’immobilier obtiennent autant de données ? Ou peut-être êtes-vous un passionné des données qui cherche à plonger dans le vaste monde de l’information sur les propriétés. Si c’est le cas, vous avez probablement entendu parler de Zillow, l’un des plus grands marchés immobiliers en ligne. Zillow dispose d’un trésor de données, des listes immobilières aux détails des agents. Mais comment obtenir ces données pour vos propres projets ? La réponse est le web scraping.
Le web scraping, c’est comme être un détective numérique. Vous utilisez des outils spéciaux pour collecter des informations sur les sites Web. Dans ce guide, nous allons explorer comment récupérer les informations Zillow. Nous verrons quelles données vous pouvez obtenir, pourquoi cela peut être délicat et comment surmonter ces défis. Nous examinerons également les outils et techniques populaires, y compris la façon de récupérer facilement les données des agents Zillow. Alors, commençons ce passionnant voyage de découverte des données !
Zillow Scraping des cibles et du contenu
Zillow est une mine d’or de données immobilières. Lorsque vous récupérez des informations Zillow, vous pouvez collecter de nombreux types de données. Ces données peuvent être très utiles pour l’analyse de marché, la recherche, ou même la construction de vos propres outils immobiliers. Voici quelques éléments clés que vous pouvez gratter :
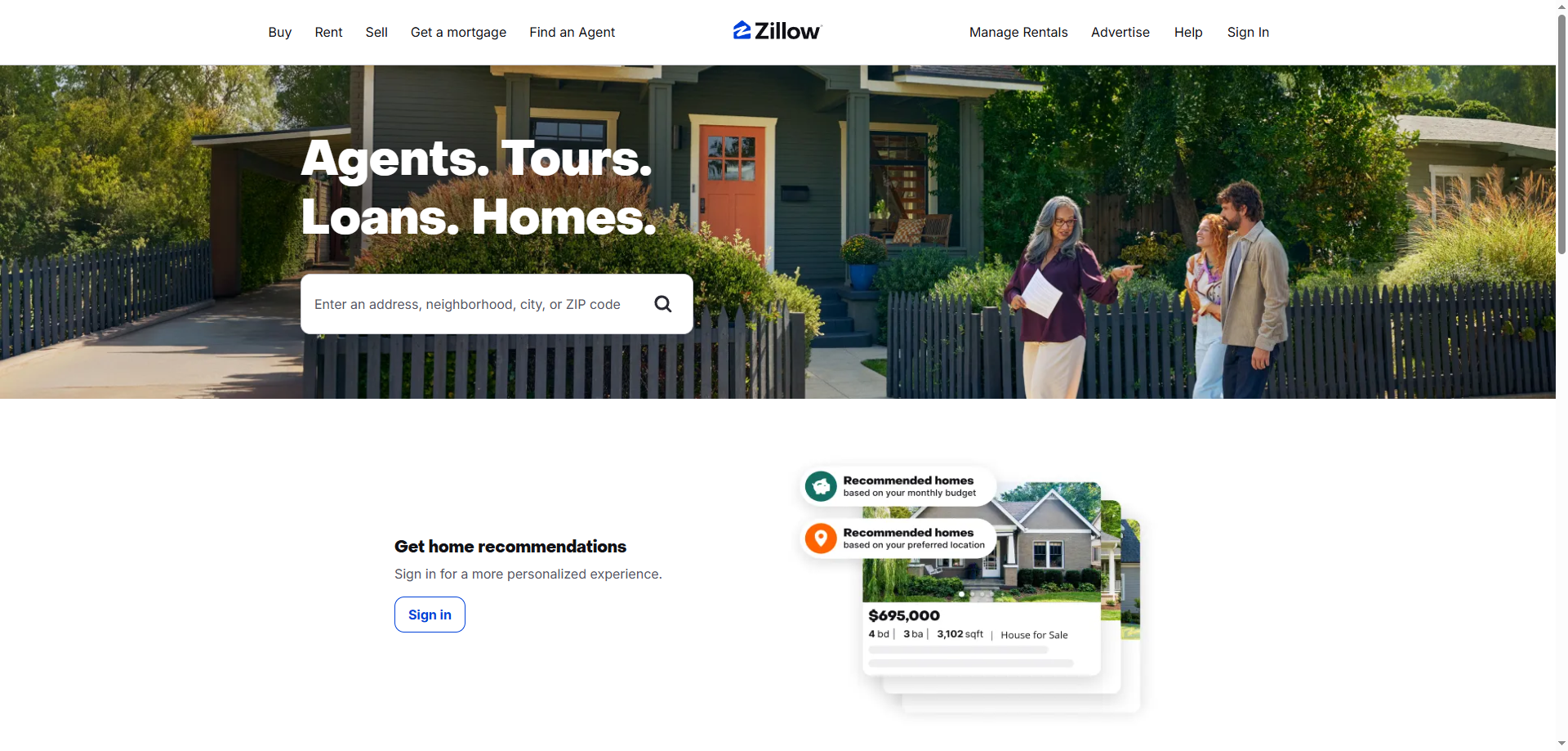
Annonces immobilières
C’est probablement la cible la plus courante. Les annonces immobilières contiennent de nombreuses informations précieuses sur les maisons à vendre ou à louer. Vous pouvez obtenir des détails tels que :
•Adresses : L’adresse complète de la propriété.
•Prix : Le prix demandé ou le prix de location actuel.
•Types de propriété : S’agit-il d’une maison, d’un appartement, d’un condo ou d’une maison de ville ?
•Chambres et salles de bains : Le nombre de chambres et de salles de bains.
•Superficie en pieds carrés : La taille de la propriété.
•Taille du terrain : La taille du terrain sur lequel se trouve la propriété.
•Descriptions de la propriété : Descriptions textuelles détaillées de la maison.
•Photos : Images de l’intérieur et de l’extérieur de la propriété.
•Zestimate : La valeur marchande estimée de Zillow pour une maison.
•Jours sur Zillow : depuis combien de temps la propriété est répertoriée sur Zillow.
Ces informations vous aident à comprendre les tendances du marché. Il vous aide également à comparer les propriétés. Vous pouvez voir à quel prix les maisons se vendent dans différentes régions. Vous pouvez également suivre la durée pendant laquelle les maisons restent sur le marché.
Données des agents immobiliers
Zillow répertorie également de nombreux agents immobiliers. Le grattage de ces données peut être utile pour la mise en réseau ou la génération de prospects. Vous pouvez souvent trouver :
•Noms de l’agent : Le nom complet de l’agent immobilier.
•Coordonnées : Numéros de téléphone et adresses e-mail (si accessibles au public).
•Informations sur le courtage : La société immobilière pour laquelle ils travaillent.
•Avis et évaluations des agents : Ce que les anciens clients disent de leur service.
•Annonces par agent : Les propriétés qu’un agent vend actuellement.
Le fait de savoir cela vous aide à entrer en contact avec les agents. Cela vous aide également à comprendre leur présence sur le marché. Si vous souhaitez récupérer facilement les données des agents Zillow, vous pouvez vous concentrer sur ces détails spécifiques.
Pourquoi Scrape Zillow est difficile
Maintenant, vous vous dites peut-être : « Ça a l’air génial ! Je vais juste commencer à gratter. Mais attendez une minute. Gratter Zillow n’est pas toujours facile. Zillow, comme de nombreux grands sites Web, a mis en place de solides mécanismes anti-grattage. Ce sont comme des agents de sécurité numériques. Ils tentent d’empêcher les programmes automatisés de collecter des données. Ils le font pour protéger leurs données et assurer une utilisation équitable de leur plateforme.
Alors, pourquoi est-il difficile de récupérer des informations sur Zillow ? Voici quelques défis courants :
•Blocage IP : Zillow peut détecter si de nombreuses requêtes proviennent de la même adresse IP dans un court laps de temps. S’ils voient cela, ils peuvent bloquer votre adresse IP. Cela signifie que vous ne pouvez plus accéder au site à partir de cette adresse IP.
•CAPTCHA : Vous pouvez rencontrer des CAPTCHA. Ce sont ces petites énigmes qui vous demandent de prouver que vous n’êtes pas un robot. Ils sont conçus pour arrêter les scripts automatisés.
•Contenu dynamique : Zillow utilise beaucoup de JavaScript pour charger le contenu. Cela signifie que lorsque vous chargez une page pour la première fois, toutes les données ne s’y trouvent pas. Il se charge lorsque vous faites défiler la page ou interagissez avec celle-ci. Les scrapers traditionnels qui ne téléchargent que le HTML brut peuvent manquer ces données.
•Structures HTML variables : La façon dont le site Web de Zillow est construit peut changer. Si la structure HTML change, votre code de grattage peut se casser. Vous devrez mettre à jour votre code pour qu’il corresponde à la nouvelle structure.
•Vérifications de l’agent utilisateur : Les sites Web vérifient souvent votre en-tête « User-Agent ». Cela leur indique le navigateur et le système d’exploitation que vous utilisez. Si votre scraper utilise un User-Agent générique ou suspect, il peut être bloqué.
•Limitation du débit : Zillow peut limiter le nombre de requêtes que vous pouvez effectuer au cours d’une certaine période. Si vous envoyez trop de demandes trop rapidement, ils vous bloqueront temporairement.
Ces mesures sont en place pour prévenir les abus. Ils veulent s’assurer que leur site Web fonctionne sans problème pour les utilisateurs humains. C’est pourquoi vous avez besoin de stratégies intelligentes pour récupérer les informations Zillow de manière efficace et éthique.
Pourquoi utiliser des proxys pour gratter Zillow
Compte tenu des solides défenses anti-grattage de Zillow, comment pouvez-vous encore obtenir les données dont vous avez besoin ? La réponse réside souvent dans l’utilisation de proxys. Les proxys agissent comme des intermédiaires entre votre ordinateur et le site Web que vous essayez de gratter. Lorsque vous utilisez un proxy, votre demande à Zillow ne provient pas directement de votre adresse IP. Au lieu de cela, il provient de l’adresse IP du proxy.
Ceci est très utile pour plusieurs raisons :
•Contourner les blocages d’IP : Si Zillow bloque une adresse IP, vous pouvez passer à une autre adresse IP proxy. Cela vous permet de continuer à gratter sans interruption. C’est comme avoir plusieurs déguisements différents.
•Distribuer les demandes : Vous pouvez envoyer des demandes via de nombreux proxys différents. Cela donne l’impression que de nombreux utilisateurs différents accèdent à Zillow. Cela vous permet d’éviter d’atteindre les limites de débit.
•Accéder au contenu géo-restreint : Parfois, certaines données ou fonctionnalités de Zillow peuvent n’être disponibles qu’à des endroits spécifiques. Les proxys vous permettent d’apparaître comme si vous naviguiez à partir de cet emplacement.
•Préservez l’anonymat : les proxys ajoutent une couche d’anonymat à vos activités de scraping. Cela peut être important pour la confidentialité et la sécurité.
L’utilisation de proxys est donc une stratégie clé pour réussir à récupérer des informations Zillow à grande échelle. Ils vous aident à éviter d’être détecté et à garantir un processus de collecte de données fluide.
Proxys résidentiels ou de datacenter
Lorsque vous décidez d’utiliser des proxys, vous apprendrez rapidement qu’il en existe différents types. Les deux principaux types sont les proxys résidentiels et les proxys de centre de données. Chacun a ses propres forces et faiblesses, notamment lorsqu’il s’agit de gratter un site comme Zillow.
Proxys de centre de données
Les proxys de centre de données sont des adresses IP provenant de serveurs cloud ou de centres de données. Ils sont souvent très rapides et bon marché. Ils sont bons pour les tâches qui nécessitent une vitesse élevée et beaucoup de bande passante. Cependant, ils ont un gros inconvénient : les sites web peuvent facilement les détecter. En effet, leurs adresses IP sont connues pour appartenir à des centres de données, et non à de véritables fournisseurs d’accès à Internet (FAI).
•Avantages : Rapide, abordable, bande passante élevée.
• Inconvénients : Facilement détecté par des systèmes anti-grattage sophistiqués, plus de chances d’être bloqué par Zillow.
Proxys résidentiels
Les proxys résidentiels sont des adresses IP qui appartiennent à de véritables utilisateurs résidentiels. Ils sont fournis par de véritables FAI. Cela signifie qu’ils ressemblent à des internautes réguliers des sites Web. Pour cette raison, ils sont beaucoup plus difficiles à détecter et à bloquer pour des sites Web comme Zillow.
•Avantages : Très difficile à détecter, moins de chances d’être bloqué, apparaît comme de vrais utilisateurs, bon pour le ciblage géographique.
• Inconvénients : Plus cher, peut être plus lent que les proxys de centre de données.
Pour gratter Zillow, les proxys résidentiels sont généralement le meilleur choix. Ils offrent un taux de réussite plus élevé car ils s’intègrent mieux au trafic utilisateur normal. Bien qu’ils coûtent plus cher, l’investissement est souvent rentable en termes de collecte de données réussie et de réduction du nombre de blocs. Cela est particulièrement vrai si vous souhaitez gratter facilement les agents Zillow ou les annonces immobilières sans interruptions constantes.
Comment gratter Zillow avec Python
Python est un langage très populaire pour le web scraping. Il dispose de nombreuses bibliothèques puissantes qui facilitent le travail. Lorsque vous souhaitez récupérer des informations Zillow à l’aide de Python, vous entendrez souvent parler d’outils comme BeautifulSoup et Scrapy. Voyons comment ceux-ci peuvent vous aider.
Utilisation de BeautifulSoup pour un grattage simple
BeautifulSoup est une bibliothèque Python permettant d’extraire des données de fichiers HTML et XML. Il est idéal pour les tâches simples de grattage. Il vous aide à naviguer, rechercher et modifier l’arborescence d’analyse. Considérez-le comme un outil qui vous aide à trouver des informations spécifiques sur une page Web.
Voici une idée très basique de la façon dont vous pourriez utiliser BeautifulSoup :
1. Faites une demande : Tout d’abord, vous devez obtenir le contenu HTML de la page Zillow. Pour cela, vous pouvez utiliser la bibliothèque requests en Python. Il envoie une requête au serveur Zillow et récupère le code HTML de la page.
2. Analysez le HTML : Une fois que vous avez le HTML, vous le transmettez à BeautifulSoup. BeautifulSoup le transforme ensuite en une structure arborescente. Cette structure permet de trouver facilement des éléments.
3. Trouver des données : Vous pouvez ensuite utiliser les méthodes de BeautifulSoup pour trouver des éléments spécifiques. Par exemple, vous pouvez rechercher tous les titres de propriété, les prix ou les adresses. Pour ce faire, vous devez examiner les balises et les classes HTML.
Exemple (Code conceptuel - Ne pas pour une exécution directe sur Zillow en raison de l’anti-scraping) :
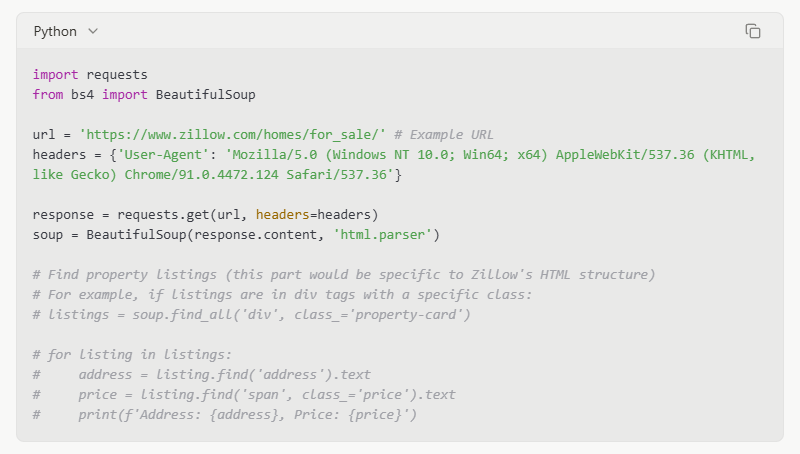
Remarque : Le code ci-dessus est un exemple simplifié. Le site Web de Zillow est complexe et utilise un contenu dynamique. Les requêtes directes et l’analyse simple avec BeautifulSoup peuvent ne pas obtenir toutes les données. Vous devrez gérer le rendu JavaScript et d’autres mesures anti-grattage.
Utilisation de Scrapy pour un grattage avancé
Pour les projets de grattage plus complexes et à grande échelle, Scrapy est un meilleur choix. Scrapy est un puissant framework Python pour l’exploration et le grattage du Web. Il gère de nombreuses choses automatiquement, comme faire des demandes, gérer les cookies et gérer les sessions. Il est conçu pour la vitesse et l’efficacité.
Scrapy fonctionne en définissant
'araignées'. Il s’agit de classes que vous écrivez pour définir comment explorer un site et extraire des données. Scrapy peut également gérer des requêtes simultanées, ce qui signifie qu’il peut extraire plusieurs pages à la fois. Cela le rend beaucoup plus rapide pour les grands projets.
Principales caractéristiques de Scrapy :
•Robustesse : Il peut gérer le HTML cassé et divers problèmes de réseau.
•Évolutivité : Conçu pour l’extraction de données à grande échelle.
•Middleware : Vous permet de personnaliser la façon dont les demandes sont envoyées et les réponses sont traitées. C’est ici que vous pouvez intégrer des proxys et gérer la rotation de l’agent utilisateur.
•Pipelines : Utilisé pour traiter les données extraites, par exemple en les nettoyant, en les validant et en les enregistrant dans une base de données ou un fichier.
Bien que Scrapy soit plus complexe à mettre en place que BeautifulSoup, il offre beaucoup plus de contrôle et de puissance pour les tâches de grattage sérieuses. Si vous envisagez de récupérer des informations sur Zillow régulièrement et à grande échelle, l’apprentissage de Scrapy est un investissement qui en vaut la peine.
Autres outils et considérations
Au-delà de BeautifulSoup et Scrapy, d’autres outils et techniques peuvent aider :
•Selenium/Playwright : Il s’agit d’outils d’automatisation de navigateur. Ils peuvent contrôler un véritable navigateur Web. Ceci est utile pour extraire du contenu dynamique qui se charge avec JavaScript. Ils peuvent cliquer sur des boutons, remplir des formulaires et faire défiler des pages, tout comme un utilisateur humain. Cependant, ils sont plus lents et utilisent plus de ressources.
•Navigateurs sans affichage : Il s’agit de navigateurs Web sans interface utilisateur graphique. Ils sont souvent utilisés avec Selenium ou Playwright pour automatiser les interactions du navigateur en arrière-plan.
•Grattage d’API : Parfois, les sites Web ont des API (interfaces de programmation d’applications) cachées qu’ils utilisent pour charger des données. Si vous parvenez à trouver et à comprendre ces API, vous pouvez souvent obtenir des données directement, ce qui est beaucoup plus rapide et plus fiable que le grattage HTML.
N’oubliez pas que lorsque vous utilisez l’un de ces outils pour récupérer des informations sur Zillow, vous devez toujours être conscient des conditions d’utilisation et des considérations juridiques de Zillow. Le grattage éthique est important.
Comme nous l’avons vu, les mesures anti-grattage de Zillow sont sophistiquées. Ils peuvent détecter les méthodes de grattage traditionnelles. C’est là que des outils avancés tels que le navigateur DICloak Antidetect entrent en jeu. Ce navigateur n’est pas simplement un navigateur Web ordinaire. Il est conçu pour vous aider à gérer plusieurs comptes en ligne avec un maximum d’anonymat. Pour ce faire, il rend votre empreinte digitale unique et difficile à détecter.
Considérez votre empreinte digitale comme un ensemble unique de caractéristiques que les sites Web peuvent utiliser pour vous identifier. Cela inclut votre type de navigateur, votre système d’exploitation, la résolution de votre écran et même la façon dont vous déplacez votre souris. DICloak Antidetect Browser vous aide à créer et à gérer de nombreuses empreintes digitales différentes et uniques. Cela rend beaucoup plus difficile pour Zillow de lier vos activités de grattage entre elles et de vous bloquer.
Mais DICloak offre encore plus. Il dispose d’une puissante fonction RPA (Robotic Process Automation) intégrée. La RPA vous permet d’automatiser les tâches répétitives. Vous pouvez enregistrer une série d’actions que vous effectuez dans le navigateur, comme accéder à une page, cliquer sur des éléments ou remplir des formulaires. Ensuite, vous pouvez lire ces actions automatiquement. C’est incroyablement utile pour gratter Zillow car :
•Imite le comportement humain : La RPA peut simuler des interactions de type humain. Cela rend vos activités de grattage plus naturelles pour les systèmes anti-bots de Zillow. Il peut gérer le défilement, les retards et les clics d’une manière qu’un simple script ne peut pas gérer.
•Gère le contenu dynamique : Étant donné que la RPA fonctionne en contrôlant un navigateur réel, elle peut facilement gérer le contenu dynamique chargé par JavaScript. Il attend que des éléments apparaissent avant d’interagir avec eux.
•Flux de travail personnalisables : Vous pouvez créer des flux de travail RPA personnalisés pour répondre à vos besoins spécifiques en matière de grattage. Par exemple, vous pouvez configurer un flux de travail pour visiter les listes de propriétés, extraire des points de données spécifiques, puis passer à l’annonce suivante. Cela peut vous aider à gratter facilement les données des agents Zillow ou les détails de la propriété avec précision.
Si vous êtes sérieux au sujet de l’extraction d’informations Zillow et que vous souhaitez une solution robuste capable de contourner les mécanismes anti-grattage avancés, le navigateur DICloak Antidetect avec ses capacités RPA change la donne. Il s’agit d’un moyen puissant et flexible d’automatiser la collecte de données. Si vous souhaitez utiliser DICloak Antidetect Browser pour personnaliser les processus RPA de récupération des informations Zillow, vous pouvez contacter leur service client pour adapter des fonctions de grattage RPA spécifiques à vos besoins.
Conclusion
Extraire des informations Zillow peut être un moyen puissant de recueillir des données immobilières précieuses. Cependant, il comporte ses défis. Zillow dispose de mesures anti-grattage strictes. Il s’agit notamment du blocage d’IP, des CAPTCHA et du contenu dynamique. Mais avec les bons outils et les bonnes stratégies, vous pouvez surmonter ces obstacles.
L’utilisation de proxys, en particulier de proxys résidentiels, est essentielle pour contourner les blocages d’IP et préserver l’anonymat. Les bibliothèques Python comme BeautifulSoup et Scrapy offrent des solutions robustes pour l’extraction de données. Pour un scraping plus avancé et plus fiable, en particulier lorsqu’il s’agit de systèmes anti-bots complexes, des outils tels que le navigateur DICloak Antidetect avec sa fonctionnalité RPA offrent un avantage significatif. Ils vous aident à imiter le comportement humain et à gérer efficacement le contenu dynamique.
N’oubliez pas de toujours gratter de manière responsable et éthique. Respectez les conditions d’utilisation de Zillow. Grâce aux connaissances et aux outils abordés dans ce guide, vous êtes bien équipé pour extraire des informations sur Zillow et libérer le vaste potentiel des données immobilières. Que vous souhaitiez gratter facilement les agents Zillow ou les annonces immobilières détaillées, le voyage commence ici.
 Outils gratuits
Outils gratuits Extension de cookie
Extension de cookie Générateur UA
Générateur UA Générateur d'adresse MAC
Générateur d'adresse MAC Générateur d'IP
Générateur d'IP Liste des adresses IP
Liste des adresses IP Générateur de code 2FA
Générateur de code 2FA Horloge mondiale
Horloge mondiale Vérification Anonyme
Vérification Anonyme WebRTC Leak Test
WebRTC Leak Test Générateur UUID
Générateur UUID Vérificateur de proxy
Vérificateur de proxy Vérificateur d'annonces FB
Vérificateur d'annonces FB Extraction de données web par IA
Extraction de données web par IA Outils SMM gratuits
Outils SMM gratuits Vérificateur d'ombre bannissement Twitter
Vérificateur d'ombre bannissement Twitter Générateur UTM
Générateur UTM Générateur de noms d'utilisateur
Générateur de noms d'utilisateur Generateur de hashtags IA
Generateur de hashtags IA Générateur de titre LinkedIn
Générateur de titre LinkedIn Redimensionneur d’images sociales
Redimensionneur d’images sociales




