Haben Sie sich jemals gefragt, wie Immobilienprofis an so viele Daten kommen? Oder vielleicht sind Sie ein Datenenthusiast, der in die riesige Welt der Immobilieninformationen eintauchen möchte. Wenn ja, haben Sie wahrscheinlich schon von Zillow gehört, einem der größten Online-Immobilienmarktplätze. Zillow verfügt über einen Schatz an Daten, von Immobilienangeboten bis hin zu Maklerdetails. Aber wie kommen Sie an diese Daten für Ihre eigenen Projekte? Die Antwort ist Web Scraping.
Web Scraping ist wie ein digitaler Detektiv zu sein. Sie verwenden spezielle Tools, um Informationen von Websites zu sammeln. In diesem Leitfaden untersuchen wir, wie Sie Zillow-Informationen kratzen können. Wir behandeln, welche Daten Sie erhalten können, warum es schwierig sein kann und wie Sie diese Herausforderungen meistern können. Wir werden uns auch beliebte Tools und Techniken ansehen, einschließlich der einfachen Scraping-Daten von Zillow-Agenten. Beginnen wir also mit dieser aufregenden Reise der Datenentdeckung!
Zillow Scraping von Zielen und Inhalten
Zillow ist eine Goldgrube für Immobiliendaten. Wenn Sie Zillow-Informationen kratzen, können Sie viele Arten von Daten sammeln. Diese Daten können sehr nützlich für Marktanalysen, Recherchen oder sogar den Aufbau eigener Immobilientools sein. Hier sind einige wichtige Dinge, die Sie kratzen können:
Immobilienangebote
Dies ist wahrscheinlich das häufigste Ziel. Immobilienangebote enthalten viele wertvolle Informationen über zum Verkauf oder zur Vermietung stehende Häuser. Sie können Details erhalten wie:
•Adressen: Die vollständige Adresse der Immobilie.
•Preise: Der aktuelle Angebotspreis oder Mietpreis.
•Immobilientypen: Handelt es sich um ein Haus, eine Wohnung, eine Eigentumswohnung oder ein Stadthaus?
•Schlafzimmer und Badezimmer: Die Anzahl der Schlafzimmer und Badezimmer.
•Quadratmeterzahl: Die Größe des Grundstücks.
•Grundstücksgröße: Die Größe des Grundstücks, auf dem sich die Immobilie befindet.
•Immobilienbeschreibungen: Detaillierte Textbeschreibungen des Hauses.
•Fotos: Bilder von innen und außen der Immobilie.
•Zestimate: Der geschätzte Marktwert von Zillow für ein Eigenheim.
•Tage auf Zillow: Wie lange die Immobilie schon auf Zillow gelistet ist.
Diese Informationen helfen Ihnen, Markttrends zu verstehen. Es hilft Ihnen auch, Immobilien zu vergleichen. Sie können sehen, für welche Preise Häuser in verschiedenen Gebieten verkauft werden. Sie können auch verfolgen, wie lange Häuser auf dem Markt bleiben.
Daten von Immobilienmaklern
Zillow listet auch viele Immobilienmakler auf. Das Scraping dieser Daten kann für das Networking oder die Lead-Generierung nützlich sein. Sie können oft finden:
•Agentennamen: Der vollständige Name des Immobilienmaklers.
•Kontaktinformationen: Telefonnummern und E-Mail-Adressen (falls öffentlich verfügbar).
•Maklerinformationen: Das Immobilienunternehmen, für das sie arbeiten.
•Agentenbewertungen und -bewertungen: Was frühere Kunden über ihren Service sagen.
•Angebote nach Makler: Welche Immobilien ein Makler derzeit verkauft.
Wenn Sie dies wissen, können Sie sich mit Agenten verbinden. Es hilft Ihnen auch, ihre Marktpräsenz zu verstehen. Wenn Sie die Daten von Zillow-Agenten einfach kratzen möchten, können Sie sich auf diese spezifischen Details konzentrieren.
Warum Scrape Zillow schwierig ist
Jetzt denkst du vielleicht: "Das klingt großartig! Ich fange einfach an zu kratzen." Aber Moment mal. Das Schaben von Zillow ist nicht immer einfach. Zillow verfügt, wie viele große Websites, über starke Anti-Scraping-Mechanismen. Diese sind wie digitale Sicherheitskräfte. Sie versuchen, automatisierte Programme daran zu hindern, Daten zu sammeln. Sie tun dies, um ihre Daten zu schützen und eine faire Nutzung ihrer Plattform zu gewährleisten.
Warum ist es also schwierig, Zillow-Informationen zu scrapen? Hier sind einige häufige Herausforderungen:
•IP-Blockierung: Zillow kann in kurzer Zeit erkennen, ob viele Anfragen von derselben IP-Adresse kommen. Wenn sie dies sehen, blockieren sie möglicherweise Ihre IP-Adresse. Das bedeutet, dass Sie von dieser IP aus nicht mehr auf die Website zugreifen können.
•CAPTCHAs: Es kann vorkommen, dass CAPTCHAs auftreten. Das sind diese kleinen Rätsel, bei denen du beweisen musst, dass du kein Roboter bist. Sie wurden entwickelt, um automatisierte Skripte zu stoppen.
•Dynamischer Inhalt: Zillow verwendet viel JavaScript, um Inhalte zu laden. Das bedeutet, dass beim ersten Laden einer Seite nicht alle Daten vorhanden sind. Es wird geladen, wenn Sie scrollen oder mit der Seite interagieren. Herkömmliche Scraper, die nur den rohen HTML-Code herunterladen, könnten diese Daten übersehen.
•Unterschiedliche HTML-Strukturen: Die Art und Weise, wie die Website von Zillow erstellt wird, kann sich ändern. Wenn sich die HTML-Struktur ändert, kann Ihr Scraping-Code beschädigt werden. Sie müssen Ihren Code aktualisieren, damit er der neuen Struktur entspricht.
•User-Agent-Prüfungen: Websites überprüfen häufig Ihren 'User-Agent'-Header. Dadurch erfahren sie, welchen Browser und welches Betriebssystem Sie verwenden. Wenn Ihr Scraper einen generischen oder verdächtigen User-Agent verwendet, kann er blockiert werden.
•Ratenbegrenzung: Zillow kann die Anzahl der Anfragen begrenzen, die Sie in einem bestimmten Zeitraum stellen können. Wenn Sie zu schnell zu viele Anfragen senden, werden Sie vorübergehend blockiert.
Diese Maßnahmen sollen Missbrauch verhindern. Sie möchten sicherstellen, dass ihre Website für menschliche Benutzer reibungslos funktioniert. Aus diesem Grund benötigen Sie intelligente Strategien, um Zillow-Informationen effektiv und ethisch zu scrapen.
Warum Proxys verwenden, um Zillow zu scrapen?
Wie können Sie angesichts der starken Anti-Scraping-Abwehr von Zillow immer noch an die Daten gelangen, die Sie benötigen? Die Antwort liegt oft in der Verwendung von Proxys. Proxys fungieren als Mittelsmänner zwischen Ihrem Computer und der Website, die Sie zu scrapen versuchen. Wenn Sie einen Proxy verwenden, kommt Ihre Anfrage an Zillow nicht direkt von Ihrer IP-Adresse. Stattdessen kommt es von der IP-Adresse des Proxys.
Dies ist aus mehreren Gründen sehr hilfreich:
•IP-Sperren umgehen: Wenn Zillow eine IP-Adresse blockiert, können Sie zu einer anderen Proxy-IP wechseln. Auf diese Weise können Sie ohne Unterbrechung mit dem Scraping fortfahren. Es ist, als hätte man viele verschiedene Verkleidungen.
•Anfragen verteilen: Sie können Anfragen über viele verschiedene Proxys senden. Dies lässt es so aussehen, als würden viele verschiedene Benutzer auf Zillow zugreifen. Dies hilft Ihnen, das Erreichen von Ratenlimits zu vermeiden.
•Zugriff auf geografisch eingeschränkte Inhalte: Manchmal sind bestimmte Daten oder Funktionen von Zillow nur an bestimmten Standorten verfügbar. Proxys ermöglichen es Ihnen, so auszusehen, als würden Sie von diesem Ort aus surfen.
•Wahrung der Anonymität: Proxys fügen Ihren Scraping-Aktivitäten eine Ebene der Anonymität hinzu. Dies kann für den Datenschutz und die Sicherheit wichtig sein.
Die Verwendung von Proxys ist also eine Schlüsselstrategie, um Zillow-Informationen erfolgreich in großem Umfang zu scrapen. Sie helfen Ihnen, eine Erkennung zu vermeiden und einen reibungslosen Datenerfassungsprozess zu gewährleisten.
Proxys für Privathaushalte und Rechenzentren
Wenn Sie sich für die Verwendung von Proxys entscheiden, werden Sie schnell feststellen, dass es verschiedene Arten gibt. Die beiden Haupttypen sind Proxys für Privathaushalte und Proxys für Rechenzentren. Jede hat ihre eigenen Stärken und Schwächen, insbesondere wenn es darum geht, eine Website wie Zillow zu scrapen.
Rechenzentrums-Proxys
Rechenzentrumsproxys sind IP-Adressen, die von Cloud-Servern oder Rechenzentren stammen. Sie sind oft sehr schnell und günstig. Sie eignen sich gut für Aufgaben, die eine hohe Geschwindigkeit und viel Bandbreite erfordern. Sie haben jedoch einen großen Nachteil: Websites können sie leicht erkennen. Dies liegt daran, dass ihre IP-Adressen bekanntermaßen zu Rechenzentren und nicht zu echten Internet Service Providern (ISPs) gehören.
•Vorteile: Schnell, erschwinglich, hohe Bandbreite.
•Nachteile: Leicht erkennbar durch ausgeklügelte Anti-Scraping-Systeme, höhere Wahrscheinlichkeit, von Zillow blockiert zu werden.
Proxys für Privathaushalte
Residential Proxys sind IP-Adressen, die echten privaten Benutzern gehören. Sie werden von tatsächlichen ISPs bereitgestellt. Das bedeutet, dass sie wie normale Internetnutzer auf Websites aussehen. Aus diesem Grund sind sie für Websites wie Zillow viel schwieriger zu erkennen und zu blockieren.
•Vorteile: Sehr schwer zu erkennen, geringere Wahrscheinlichkeit, blockiert zu werden, erscheinen als echte Benutzer, gut für Geo-Targeting.
•Nachteile: Teurer, kann langsamer sein als Rechenzentrums-Proxys.
Für das Scraping von Zillow sind Proxys für Privathaushalte in der Regel die bessere Wahl. Sie bieten eine höhere Erfolgsquote, da sie sich besser in den normalen Benutzerverkehr einfügen. Sie kosten zwar mehr, aber die Investition zahlt sich oft in Form einer erfolgreichen Datenerfassung und weniger Blöcken aus. Dies gilt insbesondere, wenn Sie Zillow-Agenten oder Immobilienangebote ohne ständige Unterbrechungen einfach kratzen möchten.
Wie man Zillow mit Python kratzt
Python ist eine sehr beliebte Sprache für Web Scraping. Es verfügt über viele leistungsstarke Bibliotheken, die die Arbeit erleichtern. Wenn Sie Zillow-Informationen mit Python scrapen möchten, hören Sie oft von Tools wie BeautifulSoup und Scrapy. Schauen wir uns an, wie diese Ihnen helfen können.
Verwendung von BeautifulSoup zum einfachen Schaben
BeautifulSoup ist eine Python-Bibliothek zum Abrufen von Daten aus HTML- und XML-Dateien. Es eignet sich hervorragend für einfache Scraping-Aufgaben. Es hilft Ihnen beim Navigieren, Suchen und Ändern der Analysestruktur. Betrachten Sie es als ein Tool, das Ihnen hilft, bestimmte Informationen auf einer Webseite zu finden.
Hier ist eine sehr grundlegende Idee, wie Sie BeautifulSoup verwenden könnten:
1. Stellen Sie eine Anfrage: Zuerst müssen Sie den HTML-Inhalt der Zillow-Seite abrufen. Hierfür können Sie die Anforderungsbibliothek in Python verwenden. Es sendet eine Anfrage an den Zillow-Server und ruft den HTML-Code der Seite ab.
2. Parsen Sie den HTML-Code: Sobald Sie den HTML-Code haben, übergeben Sie ihn an BeautifulSoup. BeautifulSoup verwandelt es dann in eine baumartige Struktur. Diese Struktur erleichtert das Auffinden von Elementen.
3. Daten finden: Sie können dann die Methoden von BeautifulSoup verwenden, um bestimmte Elemente zu finden. Sie können z. B. nach allen Immobilientiteln, Preisen oder Adressen suchen. Dazu sehen Sie sich die HTML-Tags und -Klassen an.
Beispiel (Konzeptioneller Code - Aufgrund von Anti-Scraping nicht für die direkte Ausführung auf Zillow geeignet):
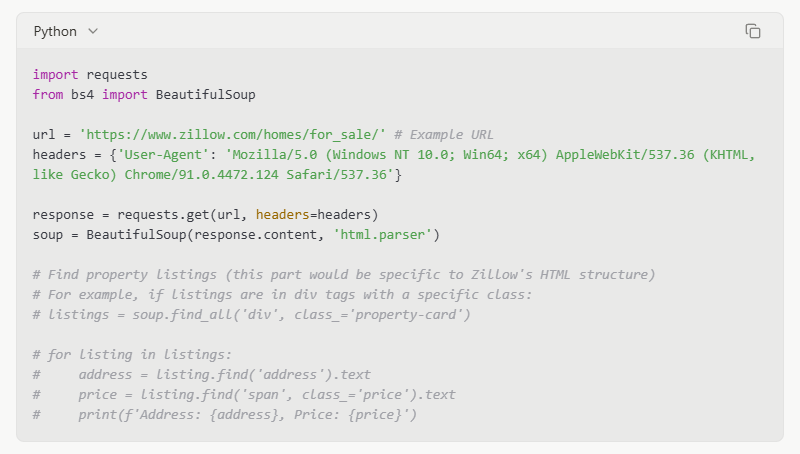
Hinweis: Der obige Code ist ein vereinfachtes Beispiel. Die Website von Zillow ist komplex und verwendet dynamische Inhalte. Direkte Anforderungen und einfaches Parsen mit BeautifulSoup erhalten möglicherweise nicht alle Daten. Sie müssten JavaScript-Rendering und andere Anti-Scraping-Maßnahmen verarbeiten.
Verwendung von Scrapy für fortgeschrittenes Scraping
Für komplexere und groß angelegte Scraping-Projekte ist Scrapy die bessere Wahl. Scrapy ist ein leistungsstarkes Python-Framework für Web-Crawling und Scraping. Es verarbeitet viele Dinge automatisch, wie z. B. das Stellen von Anfragen, den Umgang mit Cookies und das Verwalten von Sitzungen. Es ist auf Geschwindigkeit und Effizienz ausgelegt.
Scrapy funktioniert, indem es definiert
"Spinnen". Dabei handelt es sich um Klassen, die Sie schreiben, um zu definieren, wie eine Website durchforstet und Daten extrahiert werden. Scrapy kann auch gleichzeitige Anfragen verarbeiten, was bedeutet, dass es viele Seiten auf einmal scrapen kann. Das macht es bei großen Projekten viel schneller.
Hauptmerkmale von Scrapy:
•Robustheit: Es kann fehlerhaftes HTML und verschiedene Netzwerkprobleme bewältigen.
•Skalierbarkeit: Konzipiert für die Extraktion von Daten in großem Umfang.
•Middleware: Hier können Sie anpassen, wie Anfragen gesendet und Antworten verarbeitet werden. Hier können Sie Proxys integrieren und die Rotation von User-Agent handhaben.
•Pipelines: Wird verwendet, um die gescrapten Daten zu verarbeiten, z. B. um sie zu säubern, zu validieren und in einer Datenbank oder Datei zu speichern.
Scrapy ist zwar komplexer einzurichten als BeautifulSoup, bietet aber viel mehr Kontrolle und Leistung für ernsthafte Scraping-Aufgaben. Wenn Sie vorhaben, Zillow-Informationen regelmäßig und in großem Umfang zu scrapen, ist das Erlernen von Scrapy eine lohnende Investition.
Weitere Tools und Überlegungen
Neben BeautifulSoup und Scrapy können auch andere Tools und Techniken helfen:
•Selenium/Playwright: Hierbei handelt es sich um Browser-Automatisierungstools. Sie können einen echten Webbrowser steuern. Dies ist nützlich für das Scraping dynamischer Inhalte, die mit JavaScript geladen werden. Sie können auf Schaltflächen klicken, Formulare ausfüllen und Seiten scrollen, genau wie ein menschlicher Benutzer. Sie sind jedoch langsamer und verbrauchen mehr Ressourcen.
•Headless-Browser: Hierbei handelt es sich um Webbrowser ohne grafische Benutzeroberfläche. Sie werden oft mit Selenium oder Playwright verwendet, um Browserinteraktionen im Hintergrund zu automatisieren.
•API-Scraping: Manchmal haben Websites versteckte APIs (Application Programming Interfaces), die sie zum Laden von Daten verwenden. Wenn Sie diese APIs finden und verstehen können, können Sie Daten oft direkt abrufen, was viel schneller und zuverlässiger ist als das Scraping von HTML.
Denken Sie daran, dass Sie bei der Verwendung eines dieser Tools zum Scrapen von Zillow-Informationen immer die Nutzungsbedingungen und rechtlichen Überlegungen von Zillow beachten müssen. Ethisches Scraping ist wichtig.
Wie wir bereits besprochen haben, sind die Anti-Scraping-Maßnahmen von Zillow ausgeklügelt. Sie können herkömmliche Scraping-Methoden erkennen. Hier kommen fortschrittliche Tools wie der DICloak Antidetect Browser ins Spiel. Dieser Browser ist nicht nur ein normaler Webbrowser. Es wurde entwickelt, um Ihnen zu helfen, mehrere Online-Konten mit maximaler Anonymität zu verwalten. Dies geschieht, indem es Ihren digitalen Fingerabdruck einzigartig und schwer zu erkennen macht.
Stellen Sie sich Ihren digitalen Fingerabdruck als eine einzigartige Reihe von Merkmalen vor, die Websites verwenden können, um Sie zu identifizieren. Dazu gehören der Browsertyp, das Betriebssystem, die Bildschirmauflösung und sogar die Art und Weise, wie Sie Ihre Maus bewegen. DICloak Antidetect Browser hilft Ihnen, viele verschiedene, einzigartige digitale Fingerabdrücke zu erstellen und zu verwalten. Dies macht es für Zillow viel schwieriger, Ihre Scraping-Aktivitäten miteinander zu verknüpfen und Sie zu blockieren.
Doch DICloak bietet noch mehr. Es verfügt über eine leistungsstarke integrierte RPA-Funktion (Robotic Process Automation). RPA ermöglicht es Ihnen, sich wiederholende Aufgaben zu automatisieren. Sie können eine Reihe von Aktionen aufzeichnen, die Sie im Browser ausführen, z. B. das Navigieren zu einer Seite, das Klicken auf Elemente oder das Ausfüllen von Formularen. Anschließend können Sie diese Aktionen automatisch wiedergeben. Dies ist unglaublich nützlich für das Scrapen von Zillow, weil:
•Ahmt menschliches Verhalten nach: RPA kann menschenähnliche Interaktionen simulieren. Dadurch sehen Ihre Scraping-Aktivitäten für die Anti-Bot-Systeme von Zillow natürlicher aus. Es kann mit Scrollen, Verzögerungen und Klicks auf eine Weise umgehen, wie es ein einfaches Skript nicht kann.
•Verarbeitet dynamische Inhalte: Da RPA einen echten Browser steuert, kann es problemlos mit dynamischen Inhalten umgehen, die von JavaScript geladen werden. Es wartet, bis Elemente erscheinen, bevor es mit ihnen interagiert.
•Anpassbare Workflows: Sie können benutzerdefinierte RPA-Workflows erstellen, die Ihren spezifischen Scraping-Anforderungen entsprechen. Sie können z. B. einen Workflow einrichten, um Immobilienangebote zu besuchen, bestimmte Datenpunkte zu extrahieren und dann zum nächsten Eintrag zu wechseln. Dies kann Ihnen helfen, Zillow-Agentendaten oder Immobiliendetails einfach und präzise zu scrapen.
Wenn Sie es ernst meinen, Zillow-Informationen zu scrapen und eine robuste Lösung suchen, die fortschrittliche Anti-Scraping-Mechanismen umgehen kann, ist der DICloak Antidetect Browser mit seinen RPA-Funktionen ein Game-Changer. Es bietet eine leistungsstarke und flexible Möglichkeit, Ihre Datenerfassung zu automatisieren. Wenn Sie daran interessiert sind, den DICloak Antidetect Browser zu verwenden, um RPA-Prozesse für das Scraping von Zillow-Informationen anzupassen, können Sie sich an den Kundendienst wenden, um spezifische RPA-Scraping-Funktionen für Ihre Bedürfnisse anzupassen.
Schlussfolgerung
Das Scraping von Zillow-Informationen kann eine leistungsstarke Möglichkeit sein, wertvolle Immobiliendaten zu sammeln. Es bringt jedoch auch seine Herausforderungen mit sich. Zillow hat starke Anti-Scraping-Maßnahmen. Dazu gehören IP-Blockierung, CAPTCHAs und dynamische Inhalte. Aber mit den richtigen Tools und Strategien können Sie diese Hürden überwinden.
Die Verwendung von Proxys, insbesondere von Proxys für Privathaushalte, ist der Schlüssel zur Umgehung von IP-Sperren und zur Wahrung der Anonymität. Python-Bibliotheken wie BeautifulSoup und Scrapy bieten robuste Lösungen für die Datenextraktion. Für ein weitergehendes und zuverlässigeres Scraping, insbesondere wenn es sich um komplexe Anti-Bot-Systeme handelt, bieten Tools wie der DICloak Antidetect Browser mit seiner RPA-Funktionalität einen deutlichen Vorteil. Sie helfen Ihnen, menschliches Verhalten nachzuahmen und dynamische Inhalte effektiv zu handhaben.
Denken Sie daran, immer verantwortungsbewusst und ethisch zu kratzen. Respektieren Sie die Nutzungsbedingungen von Zillow. Mit dem Wissen und den Tools, die in diesem Leitfaden besprochen werden, sind Sie gut gerüstet, um Zillow-Informationen zu sammeln und das enorme Potenzial von Immobiliendaten zu erschließen. Egal, ob Sie einfach Zillow-Agenten oder detaillierte Immobilienangebote finden möchten, die Reise beginnt hier.
 Kostenlose Werkzeuge
Kostenlose Werkzeuge Cookie-Erweiterung
Cookie-Erweiterung UA Generator
UA Generator MAC-Adressen-Generator
MAC-Adressen-Generator IP-Generator
IP-Generator IP-Adressliste
IP-Adressliste 2FA-Code-Generator
2FA-Code-Generator Weltuhr
Weltuhr Anonymer Check
Anonymer Check WebRTC Leak Test
WebRTC Leak Test UUID-Generator
UUID-Generator Proxy-Checker
Proxy-Checker FB Anzeigenprüfer
FB Anzeigenprüfer KI-Web-Scraping
KI-Web-Scraping Kostenlose SMM-Tools
Kostenlose SMM-Tools Twitter Shadowban-Checker
Twitter Shadowban-Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator LinkedIn Headline Generator
LinkedIn Headline Generator Bildgrößen-Tool für Social Media
Bildgrößen-Tool für Social Media






