Bạn đã bao giờ tự hỏi làm thế nào các chuyên gia bất động sản có được nhiều dữ liệu như vậy chưa? Hoặc có thể bạn là một người đam mê dữ liệu đang muốn khám phá thế giới rộng lớn của thông tin bất động sản. Nếu vậy, bạn có thể đã nghe nói về Zillow, một trong những chợ bất động sản trực tuyến lớn nhất. Zillow có một kho tàng dữ liệu, từ danh sách bất động sản đến thông tin của các đại lý. Nhưng làm thế nào để bạn có được dữ liệu này cho các dự án của riêng mình? Câu trả lời là thu thập dữ liệu từ web.
Thu thập dữ liệu từ web giống như việc trở thành một thám tử kỹ thuật số. Bạn sử dụng các công cụ đặc biệt để thu thập thông tin từ các trang web. Trong hướng dẫn này, chúng ta sẽ khám phá cách thu thập thông tin từ Zillow. Chúng ta sẽ đề cập đến những loại dữ liệu bạn có thể lấy được, tại sao điều đó có thể khó khăn, và cách vượt qua những thách thức đó. Chúng ta cũng sẽ xem xét các công cụ và kỹ thuật phổ biến, bao gồm cách dễ dàng thu thập dữ liệu của các đại lý Zillow. Vậy, hãy bắt đầu hành trình thú vị này trong việc khám phá dữ liệu!
Zillow Mục tiêu và Nội dung Thu thập Dữ liệu
Zillow là một mỏ vàng của dữ liệu bất động sản. Khi bạn thu thập thông tin từ Zillow, bạn có thể thu thập nhiều loại dữ liệu khác nhau. Dữ liệu này có thể rất hữu ích cho phân tích thị trường, nghiên cứu, hoặc thậm chí xây dựng các công cụ bất động sản của riêng bạn. Dưới đây là một số điều quan trọng mà bạn có thể thu thập:
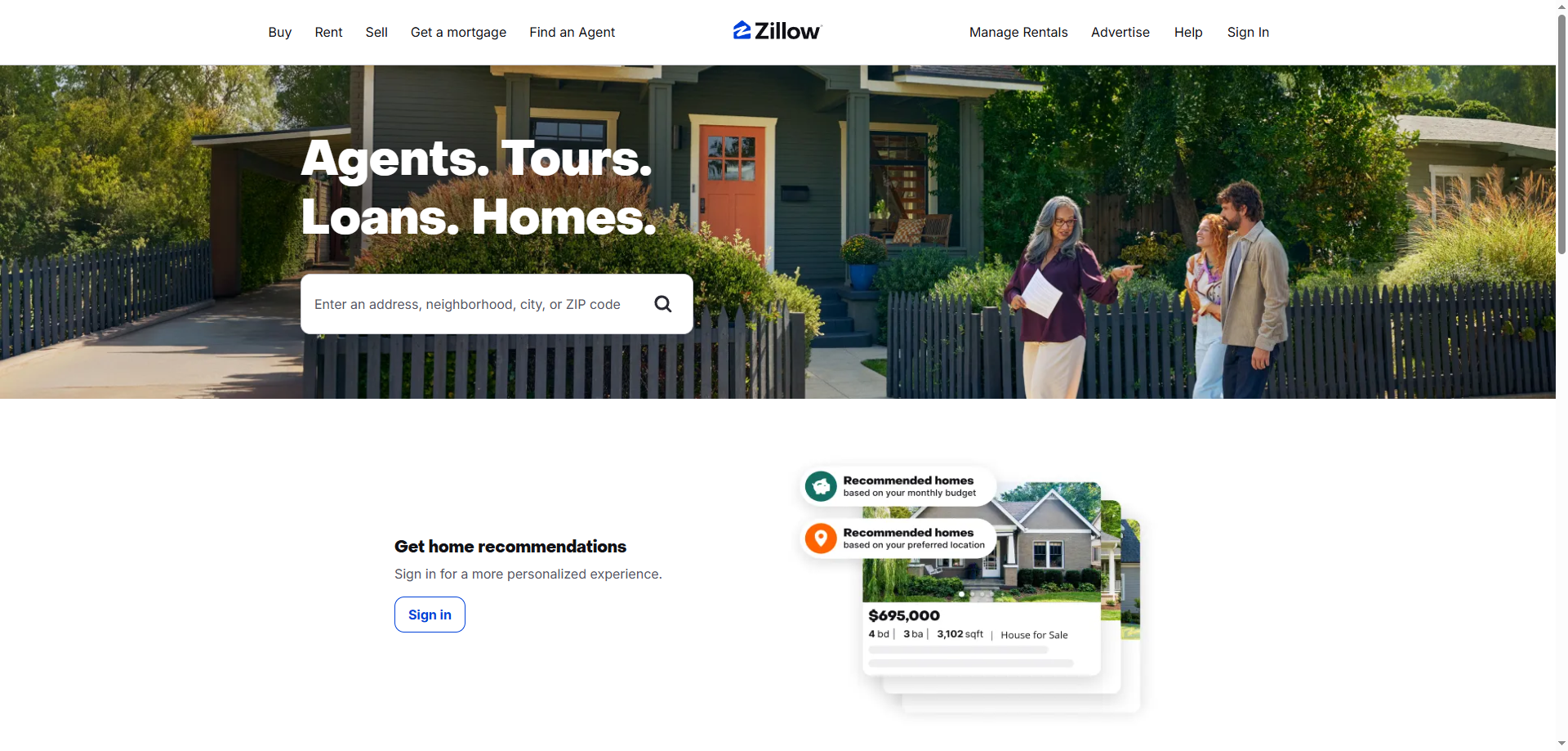
Danh sách Bất động sản
Đây có lẽ là mục tiêu phổ biến nhất. Danh sách bất động sản bao gồm nhiều thông tin quý giá về các ngôi nhà đang bán hoặc cho thuê. Bạn có thể lấy được các chi tiết như:
• Địa chỉ: Địa chỉ đầy đủ của bất động sản.
•Giá cả: Giá yêu cầu hiện tại hoặc giá cho thuê.
•Loại tài sản: Nó là một ngôi nhà, một căn hộ, một chung cư hay một nhà phố?
•Phòng ngủ và Phòng tắm: Số lượng phòng ngủ và phòng tắm.
•Diện tích: Kích thước của tài sản.
•Kích thước lô đất: Kích thước của mảnh đất mà tài sản tọa lạc.
•Mô tả tài sản: Các mô tả chi tiết về ngôi nhà.
•Hình ảnh: Hình ảnh của nội thất và ngoại thất của tài sản.
•Zestimate: Giá trị thị trường ước tính của một ngôi nhà từ Zillow.
•Số ngày trên Zillow: Thời gian tài sản đã được niêm yết trên Zillow.
Thông tin này giúp bạn hiểu các xu hướng thị trường. Nó cũng giúp bạn so sánh các tài sản. Bạn có thể thấy các ngôi nhà đang được bán với giá bao nhiêu ở các khu vực khác nhau. Bạn cũng có thể theo dõi thời gian các ngôi nhà ở lại trên thị trường.
Dữ liệu Đại lý Bất động sản
Zillow cũng liệt kê nhiều đại lý bất động sản. Việc thu thập dữ liệu này có thể hữu ích cho việc kết nối mạng hoặc tạo ra khách hàng tiềm năng. Bạn thường có thể tìm thấy:
•Tên đại lý: Tên đầy đủ của đại lý bất động sản.
•Thông tin liên hệ: Số điện thoại và địa chỉ email (nếu có sẵn công khai).
•Thông tin công ty môi giới: Công ty bất động sản mà họ làm việc.
•Đánh giá và Nhận xét của đại lý: Những gì khách hàng trước đây nói về dịch vụ của họ.
•Danh sách của đại lý: Những tài sản mà một đại lý hiện đang bán.
Biết được điều này giúp bạn kết nối với các đại lý. Nó cũng giúp bạn hiểu sự hiện diện của họ trên thị trường. Nếu bạn muốn dễ dàng thu thập dữ liệu đại lý Zillow, bạn có thể tập trung vào những chi tiết cụ thể này.
Tại sao việc thu thập dữ liệu từ Zillow lại khó khăn
Bây giờ, bạn có thể đang nghĩ, "Nghe có vẻ tuyệt vời! Tôi sẽ bắt đầu thu thập dữ liệu ngay." Nhưng hãy dừng lại một chút. Việc thu thập dữ liệu từ Zillow không phải lúc nào cũng dễ dàng. Zillow, giống như nhiều trang web lớn khác, có các cơ chế chống thu thập dữ liệu mạnh mẽ. Chúng giống như những người bảo vệ an ninh kỹ thuật số. Họ cố gắng ngăn chặn các chương trình tự động thu thập dữ liệu. Họ làm điều này để bảo vệ dữ liệu của mình và đảm bảo việc sử dụng công bằng nền tảng của họ.
Vậy, tại sao việc thu thập thông tin từ Zillow lại khó khăn? Dưới đây là một số thách thức phổ biến:
• Chặn IP: Zillow có thể phát hiện nếu nhiều yêu cầu đến từ cùng một địa chỉ IP trong một khoảng thời gian ngắn. Nếu họ thấy điều này, họ có thể chặn địa chỉ IP của bạn. Điều này có nghĩa là bạn không thể truy cập trang web từ địa chỉ IP đó nữa.
• CAPTCHAs: Bạn có thể gặp phải CAPTCHAs. Đây là những câu đố nhỏ yêu cầu bạn chứng minh rằng bạn không phải là robot. Chúng được thiết kế để ngăn chặn các kịch bản tự động.
• Nội dung động: Zillow sử dụng rất nhiều JavaScript để tải nội dung. Điều này có nghĩa là khi bạn lần đầu tiên tải một trang, không phải tất cả dữ liệu đều có sẵn. Nó sẽ tải khi bạn cuộn hoặc tương tác với trang. Các công cụ thu thập dữ liệu truyền thống chỉ tải xuống HTML thô có thể bỏ lỡ dữ liệu này.
• Cấu trúc HTML thay đổi: Cách mà trang web của Zillow được xây dựng có thể thay đổi. Nếu cấu trúc HTML thay đổi, mã thu thập dữ liệu của bạn có thể bị hỏng. Bạn sẽ cần cập nhật mã của mình để phù hợp với cấu trúc mới.
• Kiểm tra User-Agent: Các trang web thường kiểm tra tiêu đề 'User-Agent' của bạn. Điều này cho họ biết bạn đang sử dụng trình duyệt và hệ điều hành nào. Nếu công cụ thu thập dữ liệu của bạn sử dụng một User-Agent chung chung hoặc đáng ngờ, nó có thể bị chặn.
•Giới hạn Tốc độ: Zillow có thể giới hạn số lượng yêu cầu mà bạn có thể thực hiện trong một khoảng thời gian nhất định. Nếu bạn gửi quá nhiều yêu cầu quá nhanh, họ sẽ tạm thời chặn bạn.
Các biện pháp này được áp dụng để ngăn chặn lạm dụng. Họ muốn đảm bảo rằng trang web của họ hoạt động trơn tru cho người dùng. Đó là lý do tại sao bạn cần những chiến lược thông minh để thu thập thông tin từ Zillow một cách hiệu quả và có đạo đức.
Tại sao sử dụng proxy để thu thập dữ liệu từ Zillow
Với các biện pháp phòng chống thu thập dữ liệu mạnh mẽ của Zillow, làm thế nào bạn vẫn có thể lấy được dữ liệu bạn cần? Câu trả lời thường nằm ở việc sử dụng proxy. Proxy hoạt động như những người trung gian giữa máy tính của bạn và trang web mà bạn đang cố gắng thu thập dữ liệu. Khi bạn sử dụng một proxy, yêu cầu của bạn đến Zillow không đến trực tiếp từ địa chỉ IP của bạn. Thay vào đó, nó đến từ địa chỉ IP của proxy.
Điều này rất hữu ích vì một số lý do:
•Vượt qua Khối IP: Nếu Zillow chặn một địa chỉ IP, bạn có thể chuyển sang một địa chỉ IP proxy khác. Điều này cho phép bạn tiếp tục thu thập dữ liệu mà không bị gián đoạn. Nó giống như việc có nhiều hình dạng khác nhau.
•Phân phối Yêu cầu: Bạn có thể gửi yêu cầu thông qua nhiều proxy khác nhau. Điều này khiến nó trông như thể nhiều người dùng khác nhau đang truy cập vào Zillow. Điều này giúp bạn tránh việc chạm vào giới hạn tốc độ.
•Truy cập Nội dung Bị Giới hạn Địa lý: Đôi khi, một số dữ liệu hoặc tính năng trên Zillow có thể chỉ có sẵn ở những vị trí cụ thể. Proxy cho phép bạn xuất hiện như thể bạn đang duyệt từ vị trí đó.
•Duy trì Anonymity: Proxy thêm một lớp ẩn danh cho các hoạt động thu thập dữ liệu của bạn. Điều này có thể quan trọng cho quyền riêng tư và an ninh.
Vì vậy, việc sử dụng proxy là một chiến lược quan trọng để thu thập thông tin từ Zillow một cách hiệu quả. Chúng giúp bạn tránh bị phát hiện và đảm bảo quá trình thu thập dữ liệu diễn ra suôn sẻ.
Proxy Dân Cư vs. Proxy Trung Tâm Dữ Liệu
Khi bạn quyết định sử dụng proxy, bạn sẽ nhanh chóng nhận ra có nhiều loại khác nhau. Hai loại chính là proxy dân cư và proxy trung tâm dữ liệu. Mỗi loại có những điểm mạnh và điểm yếu riêng, đặc biệt khi thu thập dữ liệu từ một trang web như Zillow.
Proxy Trung Tâm Dữ Liệu
Proxy trung tâm dữ liệu là các địa chỉ IP đến từ các máy chủ đám mây hoặc trung tâm dữ liệu. Chúng thường rất nhanh và rẻ. Chúng phù hợp cho các tác vụ cần tốc độ cao và băng thông lớn. Tuy nhiên, chúng có một nhược điểm lớn: các trang web có thể dễ dàng phát hiện chúng. Điều này là do các địa chỉ IP của chúng được biết đến là thuộc về các trung tâm dữ liệu, không phải là các nhà cung cấp dịch vụ internet (ISP) thực sự.
•Ưu điểm: Nhanh, giá cả phải chăng, băng thông cao.
•Nhược điểm: Dễ bị phát hiện bởi các hệ thống chống thu thập dữ liệu tinh vi, có nguy cơ cao bị chặn bởi Zillow.
Proxy Dân Cư
Proxy dân cư là các địa chỉ IP thuộc về những người dùng dân cư thực sự. Chúng được cung cấp bởi các ISP thực tế. Điều này có nghĩa là chúng trông giống như những người dùng internet thông thường đối với các trang web. Chính vì vậy, chúng khó bị các trang web như Zillow phát hiện và chặn hơn.
•Ưu điểm: Rất khó bị phát hiện, nguy cơ bị chặn thấp hơn, xuất hiện như những người dùng thực, tốt cho việc nhắm mục tiêu theo địa lý.
•Nhược điểm: Đắt hơn, có thể chậm hơn so với proxy trung tâm dữ liệu.
Để thu thập dữ liệu từ Zillow, proxy dân cư thường là lựa chọn tốt hơn. Chúng cung cấp tỷ lệ thành công cao hơn vì chúng hòa nhập tốt hơn với lưu lượng người dùng bình thường. Mặc dù chúng có giá cao hơn, nhưng khoản đầu tư này thường mang lại lợi ích về việc thu thập dữ liệu thành công và ít bị chặn hơn. Điều này đặc biệt đúng nếu bạn muốn thu thập thông tin về các đại lý Zillow hoặc danh sách bất động sản một cách dễ dàng mà không bị gián đoạn liên tục.
Cách thu thập dữ liệu từ Zillow bằng Python
Python là một ngôn ngữ rất phổ biến cho việc thu thập dữ liệu trên web. Nó có nhiều thư viện mạnh mẽ giúp công việc trở nên dễ dàng hơn. Khi bạn muốn thu thập thông tin từ Zillow bằng Python, bạn sẽ thường nghe về các công cụ như BeautifulSoup và Scrapy. Hãy cùng xem cách những công cụ này có thể giúp bạn.
Sử dụng BeautifulSoup cho việc thu thập dữ liệu đơn giản
BeautifulSoup là một thư viện Python để trích xuất dữ liệu từ các tệp HTML và XML. Nó rất tuyệt cho các tác vụ thu thập dữ liệu đơn giản. Nó giúp bạn điều hướng, tìm kiếm và sửa đổi cây phân tích. Hãy nghĩ về nó như một công cụ giúp bạn tìm các thông tin cụ thể trên một trang web.
Dưới đây là một ý tưởng rất cơ bản về cách bạn có thể sử dụng BeautifulSoup:
1. Gửi yêu cầu: Đầu tiên, bạn cần lấy nội dung HTML của trang Zillow. Bạn có thể sử dụng thư viện requests trong Python cho việc này. Nó gửi một yêu cầu đến máy chủ Zillow và nhận được HTML của trang.
2. Phân tích HTML: Khi bạn có HTML, bạn chuyển nó cho BeautifulSoup. BeautifulSoup sau đó biến nó thành một cấu trúc giống như cây. Cấu trúc này giúp dễ dàng tìm các phần tử.
3.Tìm Dữ Liệu: Bạn có thể sử dụng các phương thức của BeautifulSoup để tìm các phần tử cụ thể. Ví dụ, bạn có thể tìm tất cả các tiêu đề bất động sản, giá cả hoặc địa chỉ. Bạn làm điều này bằng cách xem xét các thẻ HTML và lớp.
Ví dụ (Mã Khái Niệm - Không để thực thi trực tiếp trên Zillow do chống thu thập dữ liệu):
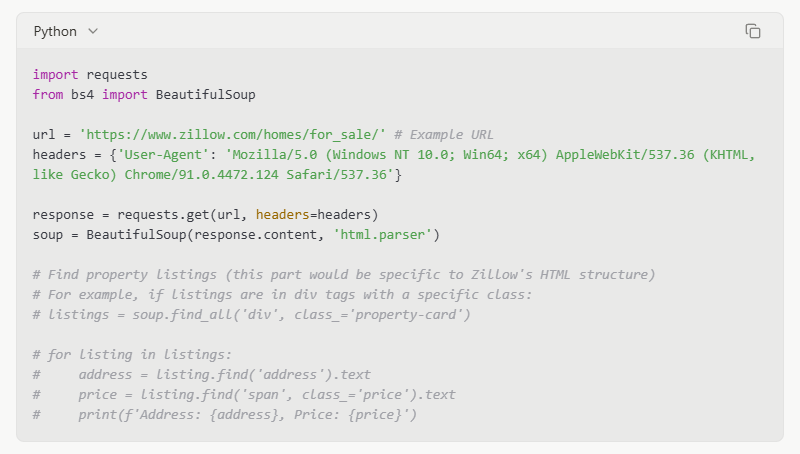
Ghi chú: Mã ở trên là một ví dụ đơn giản. Trang web của Zillow rất phức tạp và sử dụng nội dung động. Các yêu cầu trực tiếp và phân tích đơn giản với BeautifulSoup có thể không lấy được tất cả dữ liệu. Bạn sẽ cần xử lý việc kết xuất JavaScript và các biện pháp chống thu thập dữ liệu khác.
Sử Dụng Scrapy cho Thu Thập Dữ Liệu Nâng Cao
Đối với các dự án thu thập dữ liệu phức tạp và quy mô lớn hơn, Scrapy là lựa chọn tốt hơn. Scrapy là một framework Python mạnh mẽ cho việc thu thập và thu thập dữ liệu từ web. Nó tự động xử lý nhiều thứ, như thực hiện các yêu cầu, xử lý cookie và quản lý phiên. Nó được xây dựng để nhanh chóng và hiệu quả.
Scrapy hoạt động bằng cách định nghĩa
'nhện'. Đây là các lớp mà bạn viết để xác định cách thu thập một trang web và trích xuất dữ liệu. Scrapy cũng có thể xử lý các yêu cầu đồng thời, có nghĩa là nó có thể thu thập nhiều trang cùng một lúc. Điều này làm cho nó nhanh hơn rất nhiều cho các dự án lớn.
Các tính năng chính của Scrapy:
•Độ bền: Nó có thể xử lý HTML bị hỏng và các vấn đề mạng khác nhau.
•Khả năng mở rộng: Được thiết kế cho việc trích xuất dữ liệu quy mô lớn.
•Middleware: Cho phép bạn tùy chỉnh cách gửi yêu cầu và xử lý phản hồi. Đây là nơi bạn có thể tích hợp các proxy và xử lý việc xoay vòng user-agent.
•Pipelines: Được sử dụng để xử lý dữ liệu đã thu thập, chẳng hạn như làm sạch, xác thực và lưu vào cơ sở dữ liệu hoặc tệp.
Mặc dù Scrapy phức tạp hơn để thiết lập so với BeautifulSoup, nhưng nó cung cấp nhiều quyền kiểm soát và sức mạnh hơn cho các nhiệm vụ thu thập dữ liệu nghiêm túc. Nếu bạn dự định thu thập thông tin từ Zillow thường xuyên và ở quy mô lớn, việc học Scrapy là một khoản đầu tư xứng đáng.
Các Công Cụ và Xem Xét Khác
Ngoài BeautifulSoup và Scrapy, còn có các công cụ và kỹ thuật khác có thể giúp:
•Selenium/Playwright: Đây là các công cụ tự động hóa trình duyệt. Chúng có thể điều khiển một trình duyệt web thực. Điều này hữu ích cho việc thu thập nội dung động tải bằng JavaScript. Chúng có thể nhấp vào các nút, điền vào các biểu mẫu và cuộn trang, giống như một người dùng thực. Tuy nhiên, chúng chậm hơn và sử dụng nhiều tài nguyên hơn.
•Trình Duyệt Không Giao Diện Đồ Họa: Đây là các trình duyệt web không có giao diện người dùng đồ họa. Chúng thường được sử dụng với Selenium hoặc Playwright để tự động hóa các tương tác của trình duyệt trong nền.
•API Scraping: Đôi khi, các trang web có các API ẩn (Giao diện Lập trình Ứng dụng) mà họ sử dụng để tải dữ liệu. Nếu bạn có thể tìm và hiểu những API này, bạn thường có thể lấy dữ liệu trực tiếp, điều này nhanh hơn và đáng tin cậy hơn nhiều so với việc thu thập HTML.
Hãy nhớ rằng, khi sử dụng bất kỳ công cụ nào trong số này để thu thập thông tin từ Zillow, bạn phải luôn chú ý đến các điều khoản dịch vụ và các vấn đề pháp lý của Zillow. Việc thu thập dữ liệu một cách có đạo đức là rất quan trọng.
Như chúng ta đã thảo luận, các biện pháp chống thu thập dữ liệu của Zillow rất tinh vi. Chúng có thể phát hiện các phương pháp thu thập dữ liệu truyền thống. Đây là lúc các công cụ tiên tiến như DICloak Antidetect Browser phát huy tác dụng. Trình duyệt này không chỉ là một trình duyệt web thông thường. Nó được thiết kế để giúp bạn quản lý nhiều tài khoản trực tuyến với mức độ ẩn danh tối đa. Nó làm điều này bằng cách làm cho dấu vân tay kỹ thuật số của bạn trở nên độc đáo và khó phát hiện.
Hãy nghĩ về dấu vân tay kỹ thuật số của bạn như một tập hợp các đặc điểm độc đáo mà các trang web có thể sử dụng để xác định bạn. Điều này bao gồm loại trình duyệt của bạn, hệ điều hành, độ phân giải màn hình, và thậm chí cách bạn di chuyển chuột. DICloak Antidetect Browser giúp bạn tạo và quản lý nhiều dấu vân tay kỹ thuật số khác nhau, độc đáo. Điều này làm cho việc liên kết các hoạt động thu thập dữ liệu của bạn với nhau và chặn bạn trở nên khó khăn hơn cho Zillow.
Nhưng DICloak còn cung cấp nhiều hơn thế. Nó có một tính năng RPA (Tự động hóa quy trình bằng robot) mạnh mẽ được tích hợp sẵn. RPA cho phép bạn tự động hóa các tác vụ lặp đi lặp lại. Bạn có thể ghi lại một chuỗi hành động mà bạn thực hiện trong trình duyệt, như điều hướng đến một trang, nhấp vào các phần tử, hoặc điền vào các biểu mẫu. Sau đó, bạn có thể phát lại những hành động này một cách tự động. Điều này cực kỳ hữu ích cho việc thu thập dữ liệu từ Zillow vì:
•Mô phỏng Hành vi Con người: RPA có thể mô phỏng các tương tác giống như con người. Điều này làm cho các hoạt động thu thập dữ liệu của bạn trông tự nhiên hơn đối với các hệ thống chống bot của Zillow. Nó có thể xử lý cuộn trang, độ trễ và nhấp chuột theo cách mà một kịch bản đơn giản không thể.
•Xử lý Nội dung Động: Vì RPA hoạt động bằng cách điều khiển một trình duyệt thực, nó có thể dễ dàng xử lý nội dung động được tải bởi JavaScript. Nó chờ các phần tử xuất hiện trước khi tương tác với chúng.
•Luồng Công việc Tùy chỉnh: Bạn có thể tạo các luồng công việc RPA tùy chỉnh để phù hợp với nhu cầu thu thập dữ liệu cụ thể của bạn. Ví dụ, bạn có thể thiết lập một luồng công việc để truy cập các danh sách bất động sản, trích xuất các điểm dữ liệu cụ thể, và sau đó chuyển sang danh sách tiếp theo. Điều này có thể giúp bạn dễ dàng thu thập dữ liệu của các đại lý Zillow hoặc chi tiết bất động sản một cách chính xác.
Nếu bạn nghiêm túc về việc thu thập thông tin từ Zillow và muốn một giải pháp mạnh mẽ có thể vượt qua các cơ chế chống thu thập dữ liệu tiên tiến, Trình duyệt DICloak Antidetect với khả năng RPA của nó là một bước ngoặt. Nó cung cấp một cách mạnh mẽ và linh hoạt để tự động hóa việc thu thập dữ liệu của bạn. Nếu bạn quan tâm đến việc sử dụng Trình duyệt DICloak Antidetect để tùy chỉnh các quy trình RPA cho việc thu thập thông tin từ Zillow, bạn có thể liên hệ với dịch vụ khách hàng của họ để điều chỉnh các chức năng thu thập dữ liệu RPA cụ thể cho nhu cầu của bạn.
Kết luận
Thu thập thông tin từ Zillow có thể là một cách mạnh mẽ để thu thập dữ liệu bất động sản quý giá. Tuy nhiên, nó đi kèm với những thách thức. Zillow có các biện pháp chống thu thập dữ liệu mạnh mẽ. Những biện pháp này bao gồm chặn IP, CAPTCHAs và nội dung động. Nhưng với các công cụ và chiến lược phù hợp, bạn có thể vượt qua những rào cản này.
Sử dụng proxy, đặc biệt là proxy dân cư, là chìa khóa để vượt qua các khối IP và duy trì sự ẩn danh. Các thư viện Python như BeautifulSoup và Scrapy cung cấp các giải pháp mạnh mẽ cho việc trích xuất dữ liệu. Đối với việc thu thập dữ liệu nâng cao và đáng tin cậy hơn, đặc biệt khi xử lý các hệ thống chống bot phức tạp, các công cụ như DICloak Antidetect Browser với chức năng RPA của nó cung cấp một lợi thế đáng kể. Chúng giúp bạn bắt chước hành vi của con người và xử lý nội dung động một cách hiệu quả.
Hãy nhớ, luôn thu thập dữ liệu một cách có trách nhiệm và đạo đức. Tôn trọng các điều khoản dịch vụ của Zillow. Với kiến thức và công cụ được thảo luận trong hướng dẫn này, bạn đã được trang bị tốt để thu thập thông tin từ Zillow và mở khóa tiềm năng rộng lớn của dữ liệu bất động sản. Dù bạn muốn thu thập dễ dàng thông tin từ các đại lý Zillow hay danh sách bất động sản chi tiết, hành trình bắt đầu từ đây.
 Công cụ miễn phí
Công cụ miễn phí Cookie Cắm -in
Cookie Cắm -in Trình tạo UA
Trình tạo UA Trình tạo địa chỉ MAC
Trình tạo địa chỉ MAC Trình tạo địa chỉ IP
Trình tạo địa chỉ IP Danh Sách Địa Chỉ IP
Danh Sách Địa Chỉ IP Trình tạo mã 2FA
Trình tạo mã 2FA Đồng Hồ Thế Giới
Đồng Hồ Thế Giới Kiểm tra ẩn danh
Kiểm tra ẩn danh WebRTC Leak Test
WebRTC Leak Test Trình tạo UUID
Trình tạo UUID Trình kiểm tra Proxy
Trình kiểm tra Proxy Kiểm tra FB Ads
Kiểm tra FB Ads Quét web bằng AI
Quét web bằng AI Công Cụ SMM Miễn Phí
Công Cụ SMM Miễn Phí Công Kiểm Tra Shadowban Twitter
Công Kiểm Tra Shadowban Twitter Công cụ Kiểm tra Tên Instagram
Công cụ Kiểm tra Tên Instagram Trình tạo UTM
Trình tạo UTM Trình tạo username
Trình tạo username Trinh tao hashtag AI
Trinh tao hashtag AI Trình tạo tiêu đề LinkedIn
Trình tạo tiêu đề LinkedIn Đổi kích thước ảnh mạng xã hội
Đổi kích thước ảnh mạng xã hội







