So, you’ve probably heard about web scraping before, right? It’s one of those things that sounds a bit techy at first, but trust me, it’s not as complicated as it seems! In simple terms, web scraping is all about pulling information from websites and using it for whatever you need. Whether it’s data for research, grabbing product info for your store, or even collecting news articles, web scraping tools make it happen.
But here’s the thing: learning how to extract web content can be super helpful. Whether you're trying to gather data for your business or just curious about how it works, getting the hang of it is worth your time. And don't worry — in this article, we’re going to walk you through everything you need to know, step by step. We’ll talk about web content scraping tools, how to use them, and even touch on the legal stuff (because yes, that’s important too!). Plus, we’ll dive into some common issues you might run into and how to fix them.
No need to stress — we’re going to keep it simple, clear, and easy to follow. So, let’s get started!
What is Web Content Scraping?
Let’s start with the basics. Web content scraping is simply the process of automatically extracting information from websites. Think of it as a smart tool that can browse a website for you, grab the data you need, and organize it into a useful format. This could be anything from text to images to links — all the important bits that are found on web pages.
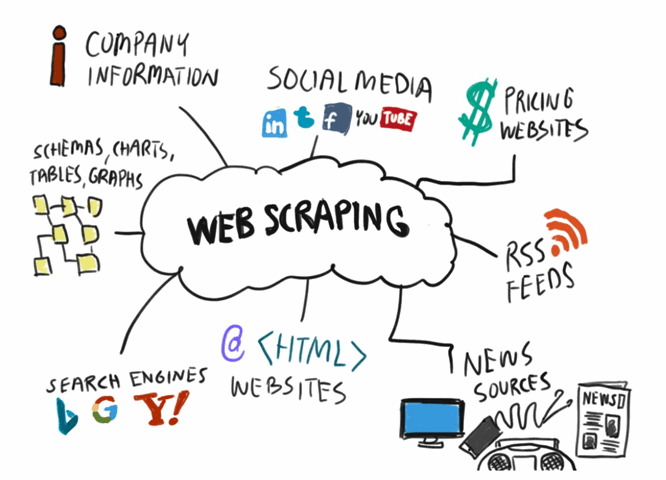
Here’s an example to make it clearer: imagine you’re gathering product details from several online stores. Instead of opening each site one by one and copying and pasting the information, a web scraping tool can do this automatically. It’s like sending a robot to go collect the info for you!
Web scraping tools work by mimicking how humans browse the web. They "crawl" a website, find the data you’re interested in, and pull it out without needing your direct input. This means that large amounts of data can be scraped quickly and efficiently, saving a ton of time compared to doing it manually.
How Does Web Scraping Work?
Web scraping works through a few key steps:
- Sending a Request: The tool first sends a request to the website you want to scrape. It’s like when you open a webpage in your browser.
- Crawling the Website: After the page loads, the scraper "crawls" through it, looking at all the elements like text, images, tables, and links.
- Extracting the Data: The tool then extracts the specific data you need. For instance, it could gather product names, prices, and descriptions from an e-commerce site.
- Cleaning and Storing the Data: Finally, the extracted data is organized into a clean format, like a CSV or Excel file, so you can easily analyze or use it.
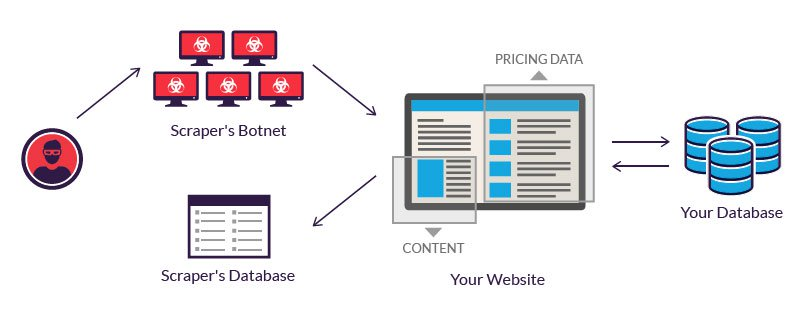
Types of Web Scraping
There are a few different ways you can scrape web content, depending on the complexity of the website and the data you need:
- Static Scraping: This is the simplest form of web scraping, where the content of the page doesn’t change. For example, if you’re scraping a list of books from an online bookstore, and the page doesn’t change much, static scraping would work well.
- Dynamic Scraping: Some websites, like social media platforms or news sites, have content that changes frequently (like new posts or live updates). In these cases, dynamic scraping is needed. Tools like Selenium or Puppeteer are often used to interact with dynamic content, since they can handle complex interactions like clicking buttons or scrolling through pages. However, managing these tools can be complex. To simplify this, web scraping APIs like HasData handle the browser automation and proxy management for you, preventing your scraper from being blocked.
- API Scraping: Some websites offer APIs (Application Programming Interfaces) that let you request data in a more structured way. Scraping via an API is often easier and more efficient than traditional scraping, but not all websites provide APIs. With an easy API setup, you can start collecting data immediately and streamline your workflow without extra configuration.
It’s like having your own personal assistant that goes online and brings back exactly what you need, in the blink of an eye!
Why Do People Use Web Content Scraping?
Web content scraping is used in many industries because it offers a fast, efficient, and automated way to gather large amounts of data. The ability to extract useful information from websites without having to do it manually is a game-changer for businesses and individuals alike. Here are some industries where web scraping is widely used:

1.E-Commerce Businesses
In the e-commerce world, competition is fierce. One of the most important aspects of staying competitive is keeping track of your competitors' prices. Instead of checking multiple online stores every day to see if prices have changed, e-commerce businesses use web scraping to monitor competitors’ prices automatically. This allows them to adjust their own prices in real time, staying competitive without having to manually track changes.
2.Journalists and Content Creators
Journalists and bloggers also use web scraping to gather news stories, articles, and other relevant content for their research. Whether they need the latest headlines from various news sources or want to track trending topics, web scraping tools can quickly collect and organize the data needed for their articles or reports.
3.Marketers and SEO Professionals
Web scraping is essential for digital marketers and SEO professionals. With the right scraping tools, they can gather data on competitors’ keywords, backlinks, rankings, and content strategies. By scraping top-ranking pages, they can understand what kind of content and keywords are driving traffic in their niche. This allows them to fine-tune their own marketing strategies, improve SEO, and create more targeted campaigns.
4.Researchers
Researchers, especially those in fields like economics, social sciences, and data science, rely heavily on data. Web scraping allows them to quickly collect large sets of data from public websites for their studies. Whether it’s pulling data from government websites, scraping academic articles, or collecting survey responses from various online sources, scraping tools make the data collection process more efficient and organized.
Common Use Cases for Web Content Scraping
Here are some common scenarios where web scraping really shines:
- Price Comparison: You can scrape prices from various online stores to compare and make informed buying decisions.
- Lead Generation: Businesses scrape contact info from directories or social media sites to generate leads for marketing campaigns.
- Market Research: Companies collect data on customer reviews, product ratings, and trends to better understand their target market.
- Job Listings: Job boards can scrape career sites to aggregate job listings, saving users the hassle of visiting each site individually.

Why is Web Scraping So Popular?
The answer lies in efficiency and automation. Scraping tools save time by quickly gathering data from multiple websites. Rather than spending hours (or even days) collecting data manually, web scraping automates the process, gathering huge volumes of data in just minutes.
And the best part? These tools can run 24/7, meaning they never stop working. This is especially useful for businesses that need fresh, up-to-date data for pricing, inventory, or market trends. By scraping data automatically, businesses don’t need to worry about missing any important changes.
How to Extract Web Content
Alright, now let’s get into the fun part — how to extract web content! Don't worry, I’ll walk you through it step by step, and I promise it’s not as complicated as it sounds.
So, how do you actually grab data from a website? Well, there are a few simple ways to do it, depending on how much data you need and what kind of website you're working with. But before we dive in, let’s talk about the tools you’ll need — because trust me, you’re not doing this by hand!
1.Choose the Right Tool
First things first: You need a good web content scraping tool. These tools will do most of the hard work for you. Some easy-to-use ones for beginners include:
- ParseHub: Great for people just starting out. You can click on the data you want to scrape.
- Octoparse: Another beginner-friendly option that offers a point-and-click interface.
- Scrapy: A more advanced option for those looking for extra control over the process.
Tip: If you’re just starting out, try ParseHub or Octoparse. They’re simple and perfect for small projects!
2.Set Up the Tool
Once you’ve picked your tool, it’s time to set it up. Most scraping tools will ask you to enter the URL (the website’s web address) of the page you want to scrape. Let’s say you want to grab product prices from an online store — you’d enter the store’s URL here.
After that, the tool will load the page and let you click on the specific parts of the page you want to scrape. For example, if you want to grab product names and prices, you just click on those areas, and the tool will know exactly where to look.
It’s a little like using a highlight marker to mark important parts of a book — except the tool does the actual work of copying and organizing it all for you.
3.Extract the Data
Now that you’ve set up the scraper, you can start extracting the data. Just click a button, and the tool will go through the website, grab all the info you need, and save it into a file for you. It’s that easy!
For example, if you're scraping product data, the tool will pull things like the product name, price, description, and even images, depending on what you’ve selected. It’ll all be saved into a neat spreadsheet (or any format you choose), and then you can analyze or use it however you like.
Tip: If you’re scraping multiple pieces of information (like price and description), you can click on each part, and the tool will know to grab them all.
4.Clean Up the Data
Sometimes, the data you scrape might need a little cleaning up. It’s like when you’ve just cooked a big meal — sometimes you need to tidy up the kitchen afterward. Web scraping tools usually do a pretty good job of organizing the data, but you might end up with some extra spaces, unnecessary characters, or other bits that aren’t helpful.
No big deal! You can easily clean this up in a tool like Excel or Google Sheets. You can remove duplicates, fix formatting issues, or even sort the data to make it easier to read.
5.Schedule Regular Scrapes (Optional)
If you need updated data regularly, you can set your scraping tool to run at scheduled times — daily, weekly, or however often you need it. For example:
- You might want to track prices on a competitor’s website every day.
- Or, if you’re scraping job listings, you could set it to run once a week to pull in the latest openings.
Tip: Scheduling regular scrapes can save you time in the long run. You don’t have to redo the process each time!
A Quick Tip: Be Mindful of Website Rules
One last thing — before you start scraping, it’s a good idea to check if the website allows it. Some websites block scrapers or ask that you don’t scrape their data. Always take a quick look at their robots.txt file (that’s a file that tells web crawlers what they can and can’t scrape). It’s just good practice to be respectful of these rules.
And that’s it! Now you know how to extract web content using a simple scraping tool. Whether you’re gathering product data, tracking prices, or collecting news articles, scraping is an easy way to automate the process and save yourself tons of time.
Remember, you don’t need to be a tech wizard to get started. Just choose a good web content scraping tool, follow a few steps, and you’ll be scraping like a pro in no time!
Legal Considerations: Is Web Scraping Legal?
So, you’re excited about web scraping, right? You’ve got your tool ready, and you’re thinking, “This is awesome, I’m going to scrape all this cool data!” But wait, before you dive in, let's chat about something important: Is web scraping legal?
The short answer is it depends. Web scraping itself isn't necessarily illegal, but it can get tricky depending on a few things. It all comes down to what you're scraping, how you're scraping it, and where you're scraping it from.

Some websites are totally cool with web scraping. They even have APIs (Application Programming Interfaces) that let you grab their data legally. But other websites have strict rules about scraping, and scraping their data could land you in hot water. You see, websites have Terms of Service (TOS) — a set of rules that explain what you can and can't do on their site. Many of them say, "Hey, don’t scrape our data."
What’s Okay to Scrape?
So, what can you scrape legally? Well, here are some general rules to keep in mind:
- Publicly Available Data: If the data is publicly visible on the website (like product prices, news articles, or blog posts), scraping it is generally okay. But, this is where it gets a bit tricky because just because something is visible doesn’t mean it’s free to grab.
- Respect Robots.txt: Ever heard of robots.txt? It’s a file that websites use to tell search engines and web scrapers which parts of the site they can or can’t scrape. Before you start scraping, always check if the website has this file and what it says. If it says “no scraping,” it’s better to stay away from that site.
When It Gets Tricky
Let’s talk about when things get a little more complicated:
- Commercial Use: If you're scraping for business purposes — like getting data to make money (e.g., selling data or using it to improve your business) — then things get a little more legal gray area. In those cases, you might run into more legal challenges, especially if you’re scraping data from a website that explicitly forbids it in their TOS.
- Copyright Issues: Just because data is available online doesn’t mean it’s free to use. For example, you might find images, articles, or product descriptions on a site that are copyrighted. If you scrape that content and use it without permission, you could be in trouble for copyright infringement.
- Data Protection Laws: If you're scraping personal information, you really need to be careful. Laws like the GDPR (General Data Protection Regulation) in Europe protect people's privacy, and scraping personal data (like email addresses or phone numbers) without consent could violate these laws. Always make sure you're not collecting sensitive personal information unless you have permission.
But Don’t Panic — Here’s How to Stay Safe
So, what can you do to make sure you’re playing by the rules? Here are some quick tips to stay safe:
- Always Check the Site’s Terms of Service: This is the first thing you should do before scraping a site. If it says "no scraping," respect that.
- Use Public Data: Stick to data that is clearly available to the public, like product prices or publicly posted articles. Don’t go scraping private data or anything that’s behind a login.
- Don’t Overwhelm Servers: Don’t bombard websites with too many scraping requests too quickly. That could slow down the website or cause it to crash, and that could get you into trouble.
- If in Doubt, Ask: If you're unsure about whether you can scrape a certain site or not, it's a good idea to reach out and ask. Many websites are fine with scraping if it’s done respectfully.
Web scraping is mostly legal, but it all depends on how and where you do it. As long as you're respectful of websites’ rules and don’t scrape things you're not supposed to, you're likely in the clear. Just make sure you’re following ethical practices and checking the legal guidelines to avoid any headaches down the road.
DICloak: The Tool You Need for Secure Web Scraping
When it comes to web scraping, especially in a world full of anti-scraping measures, DICloak Antidetect Browser stands out as a top choice for many professionals.
Whether you’re managing multiple social media accounts, running affiliate marketing campaigns, or gathering e-commerce data, DICloak offers powerful tools to make your web scraping efforts seamless, efficient, and secure.
- Flexible Proxy Configuration: Proxies are a key part of effective web scraping. DICloak lets you integrate proxies easily, with support for major protocols like HTTP/HTTPS and SOCKS5.
- Scale Your Operations Easily: If you’re looking to scale your web scraping operations, DICloak makes it simple. With bulk tools that allow you to create, import, and launch multiple browser profiles with a single click.
- RPA Automation for Web Scraping: DICloak goes beyond just masking your fingerprint and managing proxies. Its built-in Robotic Process Automation (RPA) feature automates repetitive tasks, saving you time. This makes large-scale web scraping much more efficient by automating the most time-consuming tasks.
- Cross-Platform Compatibility: DICloak supports all major operating systems, including Windows, Mac, iOS, Android, and Linux, making it easy to use on any platform. Whether you’re working from a desktop or mobile device, DICloak ensures that your web scraping needs are met.
How DICloak Helps in Web Scraping
In addition to managing multiple accounts and providing security, DICloak is designed to help you scrape data from websites without raising any red flags. It ensures that your digital fingerprint is well-hidden, making your scraping efforts more efficient and secure.
Whether you’re scraping for market research, competitor pricing, or social media management, DICloak’s features make it easier to extract web content without getting blocked or banned. The combination of custom fingerprints, proxy management, and automation tools ensures that your scraping operations are streamlined and effective.
FAQs
What data can I scrape from websites?
You can scrape any publicly available data, such as product prices, contact info, reviews, news articles, and more. However, avoid scraping private data or content protected by copyright.
Do I need technical skills to start web scraping?
You don’t need to be a tech expert. Many web scraping tools are designed for beginners and offer easy-to-use interfaces. However, basic knowledge of programming can help if you want more control.
Can web scraping be used for SEO?
Yes, web scraping can be very useful for SEO. It helps collect keyword data, analyze competitors, gather backlinks, and find content gaps — all of which can help improve your website’s performance.
Are there any risks with web scraping?
Yes, scraping too much data too quickly can get your IP blocked or even result in legal issues. Always respect the website's robots.txt and avoid scraping sensitive or protected data.
How can I store the scraped data?
Scraped data can be stored in a variety of formats, such as CSV, Excel, or directly in a database, depending on your needs and the tools you’re using.
Final Thoughts
Web scraping might sound technical, but it’s actually simple once you get the hang of it. It’s a powerful tool to automatically pull data from websites, saving you time and effort. Whether it’s for business, research, or personal projects, web scraping makes collecting data easy.
Now that you know how to extract web content, you're ready to dive in. We covered the basics, including tools, processes, and some legal tips. Don't worry if you’re not a tech expert — just pick a good tool and follow the steps!
 Web Proxy Tools
Web Proxy Tools Free Tools
Free Tools Cookie Plugin
Cookie Plugin UA Generator
UA Generator MAC Address Generator
MAC Address Generator IP Generator
IP Generator IP Address List
IP Address List 2FA Code Generator
2FA Code Generator World Clock
World Clock Anonymous Check
Anonymous Check WebRTC Leak Test
WebRTC Leak Test UUID Generator
UUID Generator Free Web Proxy Site
Free Web Proxy Site Proxy Checker
Proxy Checker FB Ad Checker
FB Ad Checker AI Web Scraping
AI Web Scraping Free SMM Tools
Free SMM Tools Twitter Shadowban Checker
Twitter Shadowban Checker Instagram Name Checker
Instagram Name Checker UTM Generator
UTM Generator Username Generator
Username Generator AI Hashtag Generator
AI Hashtag Generator







