El web scraping en 2026 se trata más de la longevidad del scraper que de la funcionalidad. Los sitios web modernos utilizan defensas avanzadas como la huella digital del navegador para identificar y bloquear scripts automatizados, dificultando que los scrapers funcionen de forma fiable a lo largo del tiempo. Los navegadores antidetect son la solución esencial a este problema, permitiendo que los scrapers aparezcan como visitantes humanos únicos. Este artículo revisará los navegadores antidetección más efectivos para el web scraping, evaluará sus puntos fuertes y débiles, y proporcionará una guía clara para elegir la herramienta adecuada para tus necesidades específicas.
Por qué necesitas navegadores antidetect para el web scraping
Un navegador antidetect es un navegador especializado diseñado para enmascarar o controlar la huella digital del usuario. En lugar de revelar las señales estándar de una herramienta automatizada, presenta un perfil realista y consistente que imita a un usuario real en un dispositivo único. Los sistemas antibot modernos analizan combinaciones de factores—incluyendo dirección IP, cookies, user-agent, resolución de pantalla, fuentes, WebGL y renderizado Canvas—para detectar automatización. Cuando estas señales son inconsistentes, el sistema señala el tráfico como sospechoso.
Esta inconsistencia es precisamente donde las herramientas estándar de automatización como los navegadores headless suelen fallar. Tienden a exponer huellas dactilares incompletas o inusuales que los sistemas de detección aprenden y bloquean rápidamente. Esto obliga a los raspadores a entrar en un ciclo de resolver acertijos CAPTCHA y rotar proxies en lugar de recopilar datos. Los navegadores antidetect solucionan esto aislando cada sesión de scraping en su propio perfil, con una huella digital única, cookies, almacenamiento local y un proxy dedicado. Este enfoque hace que el tráfico de un solo scraper parezca provenir de muchos usuarios reales diferentes.
Los límites de los navegadores antidetect
Seamos claros: los navegadores antidetección no son una solución mágica. No pueden arreglar una lógica de scraping deficiente, tasas de peticiones poco realistas ni mala gestión de proxys. La función principal de estos navegadores es eliminar una capa principal de detección: la huella digital del navegador. Esto da a una estrategia de scraping bien diseñada y gestionada de forma responsable la oportunidad de tener éxito donde de otro modo fracasaría.
Criterios clave para evaluar navegadores antidetect para web scraping
No todos los navegadores antidetect están diseñados con el web scraping como propósito principal. Para elegir la herramienta adecuada, es importante entender los criterios clave de evaluación desde una perspectiva de scraping.
Calidad de suplantación de huellas dactilares
La suplantación de huellas digitales de alta calidad consiste en presentar un conjunto consistente de señales del navegador. Los sistemas de detección pueden detectar fácilmente inconsistencias, como un agente de usuario de Windows combinado con el renderizado de fuentes en macOS. Las mejores herramientas automatizan la creación de huellas dactilares realistas y consistentes para evitar errores manuales de configuración que conducen a la detección.
Tu conclusión: Prioriza los navegadores que automatizan la generación de huellas dactilares consistentes y realistas por encima de aquellos que requieren ajustes manuales complejos.
Proxy e integración de red
La suplantación de huellas dactilares es inútil sin proxies de alta calidad. Un buen navegador antidetect debe soportar sin problemas tipos comunes de proxy como HTTP, HTTPS y SOCKS5. También debe proporcionar funciones de gestión eficientes, como la capacidad de asignar un proxy único a cada perfil y rotarlos según sea necesario.
Tu conclusión: El navegador debe ofrecer una integración robusta con proxies residenciales, de centros de datos o móviles y permitir una gestión sencilla por perfil.
Perfil y aislamiento de cookies
La fuga de sesión, donde las cookies o los datos de almacenamiento local de un perfil se mezclan con otro, puede vincular instantáneamente identidades separadas y hacer que se bloqueen. Para extraer páginas iniciadas sesión o ejecutar trabajos concurrentes, el aislamiento total entre perfiles es una característica no negociable.
Tu conclusión: Cada perfil de navegador debe tener sus propias cookies, almacenamiento local y caché completamente separados para evitar la contaminación cruzada.
Automatización e integración de API
Para cualquier operación seria de web scraping, la automatización es esencial. Un navegador antidetect adecuado debe tener acceso robusto a la API y ser compatible con frameworks de automatización comunes como Puppeteer o Selenium. Algunas herramientas comercializan la automatización como una idea secundaria, lo cual se hace evidente al integrarlas en un flujo de trabajo de scraping. Sin estas capacidades, escalar las operaciones más allá de unas pocas partidas manuales es casi imposible.
Tu conclusión: Una API local o en la nube sólida y compatibilidad con librerías estándar de automatización son fundamentales para escalar flujos de trabajo de scraping.
Escalabilidad y rendimiento
Un navegador puede funcionar bien con unos pocos perfiles, pero tener dificultades al gestionar cientos. Los factores clave de rendimiento incluyen el uso de recursos (CPU y RAM), el tiempo de arranque del perfil y la estabilidad general bajo una carga elevada. Es fundamental evaluar cómo funciona un navegador a la escala que pretendes operar.
Tu conclusión: Para proyectos a gran escala, evalúa el consumo de recursos del navegador, la frecuencia de fallos y el rendimiento durante periodos prolongados.
Usabilidad y gestión de perfiles
Al gestionar decenas o cientos de perfiles, las características de usabilidad se vuelven críticas para la eficiencia. Una interfaz torpe puede ralentizar los flujos de trabajo y provocar costosos errores de configuración. Busca funciones como creación masiva de perfiles, plantillas, asignación rápida de proxy e indicadores de estado claros.
Tu conclusión: Una interfaz intuitiva con potentes herramientas de gestión de perfiles ahorra tiempo y reduce el riesgo de errores.
Modelo de precio y licencias
Los modelos de precios van desde cargos por perfil hasta suscripciones escalonadas con diferentes conjuntos de características. Para el scraping profesional, el valor de la fiabilidad y la automatización suele superar el precio mensual más bajo. La clave es elegir un modelo que se ajuste a la escala y a los requisitos técnicos de tu proyecto.
Tu conclusión: Evalúa los precios en función del valor global que aporta a tu flujo de trabajo, no solo de la cuota mensual.
Comparando los principales navegadores antidetección para el web scraping en 2026
: .
| Suplantación de huellas | digitales en navegador | Soporte de calidad de proxy | , capacidades de automatización/API, | precio/nivel | , caso de uso ideal |
| DICloak |
Aislamiento de alta fidelidad (Canvas, WebGL, WebRTC) |
HTTP / HTTPS / SOCKS5, Gestión de grupos proxy |
RPA Automate, Local API |
Gratis (5 perfiles). Pagado desde ~$8/mes. |
Web scraping escalable, compartición de cuentas, comercio electrónico y gestión de cuentas sociales. |
| Multilogin |
Control manual profundo (Canvas, WebGL) |
Túneles HTTP/SOCKS5/SSH |
API local robusta (Selenium/Puppeteer) |
~99 €/mes. (Plano de escala). No hay nivel gratuito. |
Seguridad empresarial, grandes agencias, gestión de cuentas de alto valor. |
| Navegador Octo |
Base de datos de huellas dactilares de dispositivos reales |
HTTP/SOCKS5/SSH |
API rápida y ligera |
~29 €/mes (Inicial). Descuentos por volumen disponibles. |
Tareas críticas en velocidad, apuestas/cripto, scraping de escala media. |
| AdsPower |
Riesgo de detección sólido pero mayor |
APIs proxy integradas por proveedores |
RPA + API local básica |
~$9/mes (Base). Modelo flexible de "Pago por perfil". |
No programadores, automatización de comercio electrónico, marketing. |
| Delfín {Anty} |
Huellas dactilares centradas en plataformas |
Gestor de proxy integrado |
Scripting básico, API limitada |
Gratis (10 perfiles). Comienzas pagadas ~$10/mes. |
Marketing de afiliados, scraping en redes sociales, principiantes. |
Resumen de los principales navegadores antidetect para web scraping en 2026
Aquí tienes los navegadores antidetect capaces para web scraping que cubren diferentes necesidades y casos de uso.
DICloak
DICloak es un navegador antidetección robusto diseñado para ofrecer a los usuarios una solución fluida y escalable para el web scraping. Destaca en el mercado por ofrecer infraestructura en la nube, aislamiento avanzado de huellas dactilares y soporte de automatización, lo que lo hace ideal para operaciones de web scraping que requieren indetectabilidad, escalabilidad y eficiencia. A diferencia de los navegadores tradicionales, DICloak permite a los usuarios gestionar múltiples perfiles con huellas dactilares distintas, asegurando que las actividades de web scraping permanezcan indetectables y no activen medidas antibot habituales en sitios web modernos.
La capacidad de DICloak para gestionar trabajos de scraping a gran escala manteniendo la privacidad de la cuenta y la estabilidad del perfil lo diferencia de la competencia. Su configuración personalizada de proxy y las funciones de colaboración en equipo la convierten en una herramienta poderosa para usuarios que necesitan un navegador antidetección seguro, escalable y fácil de usar para el extracto, especialmente en los sectores del comercio electrónico, el marketing digital y la investigación de mercado.
Ventajas:
- La infraestructura cloud de DICloak escala tareas de extracción sin sobrecargar los recursos locales.
- Enmascara eficazmente las huellas dactilares del navegador, asegurando un scraping indetectable.
- DICloak ofrece una gestión flexible de proxy para evitar bloqueos IP durante el scraping.
- La RPA automatiza tareas de scraping de alto volumen entre perfiles.
- DICloak permite una colaboración fluida en equipo con una gestión multiperfil.
- Diseñado para facilitar su uso, haciéndolo accesible tanto para principiantes como para expertos.
Contras:
- Solo soporta dispositivos de sobremesa (sin aplicaciones móviles)
- Solo el navegador Orbita basado en Chromium
Casos de uso ideales:
- Proyectos profesionales de web scraping
- Equipos de datos y desarrolladores que ejecutan pipelines automatizados de scraping
- Raspado a escala media a grande donde la estabilidad importa
Multilogin
Multilogin es una opción poderosa y de larga duración para operaciones de scraping a gran escala. Ofrece un control profundo y detallado sobre parámetros de huellas digitales como Canvas y WebGL, y soporta tanto motores de navegador basados en Chromium como en Firefox. Su fortaleza radica en manejar miles de perfiles con un aislamiento robusto de sesiones, lo que la convierte en una opción destacada para proyectos a nivel empresarial. Sin embargo, su potencia viene acompañada de un precio más alto y una curva de aprendizaje más pronunciada. A diferencia de DICloak, que ofrece un navegador en la nube para descargar el consumo de recursos, las operaciones de Multilogin suelen depender de recursos locales del sistema, lo que puede ser un factor importante al ejecutar cientos de perfiles.
Ventajas:
- Enmascaramiento de huellas muy fuerte con control granular
- Soporta múltiples motores de navegador (Chromium, Firefox)
- Estabilidad probada para raspado a gran escala
- Automatización sólida y soporte para API
Contras:
- Caro en comparación con la mayoría de los competidores
- Curva de aprendizaje más pronunciada para nuevos usuarios
- Uso local de recursos más intenso a gran escala
Casos de uso ideales:
- Operaciones de scraping a nivel empresarial
- Equipos que extraen objetivos de alta seguridad o alto valor
- Usuarios que necesitan una personalización manual profunda de huellas dactilares
Navegador Octo
Octo Browser es una opción popular para tareas de scraping de escala media, situándose en un punto intermedio entre soluciones de nivel básico y empresarial. Proporciona una suplantación fiable de huellas dactilares sin saturar a los usuarios con configuraciones complejas. Octo Browser ofrece acceso a la API y soporta flujos de trabajo comunes de automatización, ofreciendo un rendimiento estable con un uso moderado de recursos en hardware estándar.
Ventajas:
- Buena calidad de huellas dactilares para la mayoría de los escenarios de raspado
- Precios razonables en comparación con las herramientas empresariales
- Interfaz limpia y gestión sencilla de perfiles
- Adecuado para automatización con frameworks comunes
Contras:
- Funciones de automatización menos avanzadas que las herramientas de primer nivel
- Puede tener dificultades contra los sistemas de detección más agresivos
Casos de uso ideales:
- Freelancers y equipos pequeños
- Proyectos de extracción y extracción de datos de escala media
- Usuarios que buscan funciones sólidas sin precios empresariales
AdsPower
AdsPower es principalmente conocido por la gestión de múltiples cuentas, pero también se utiliza para scraping, especialmente cuando la organización de perfiles es una prioridad. Cuenta con una interfaz fácil de usar y soporta técnicas estándar de enmascaramiento de huellas dactilares. Su principal limitación para el scraping es su profundidad de automatización, que no es tan flexible como las herramientas diseñadas específicamente para la extracción de datos. Esto lo hace más adecuado para tareas de scraping más ligeras o semi-automatizadas, como la automatización del comercio electrónico (Amazon/eBay).
Ventajas:
- Interfaz fácil de usar con una gestión sólida de perfiles
- Soporte amplio de proxy e integraciones con proveedores
- Precios asequibles con planes flexibles
Contras:
- Las funciones de automatización son más limitadas para el scraping a gran escala
- La suplantación de huellas digitales es sólida pero no líder en la industria
Casos de uso ideales:
- Proyectos de raspado pequeños a medianos
- Usuarios que combinan el scraping con flujos de trabajo multicuenta
- Equipos que priorizan la usabilidad sobre la automatización profunda
Delfín{Anty}
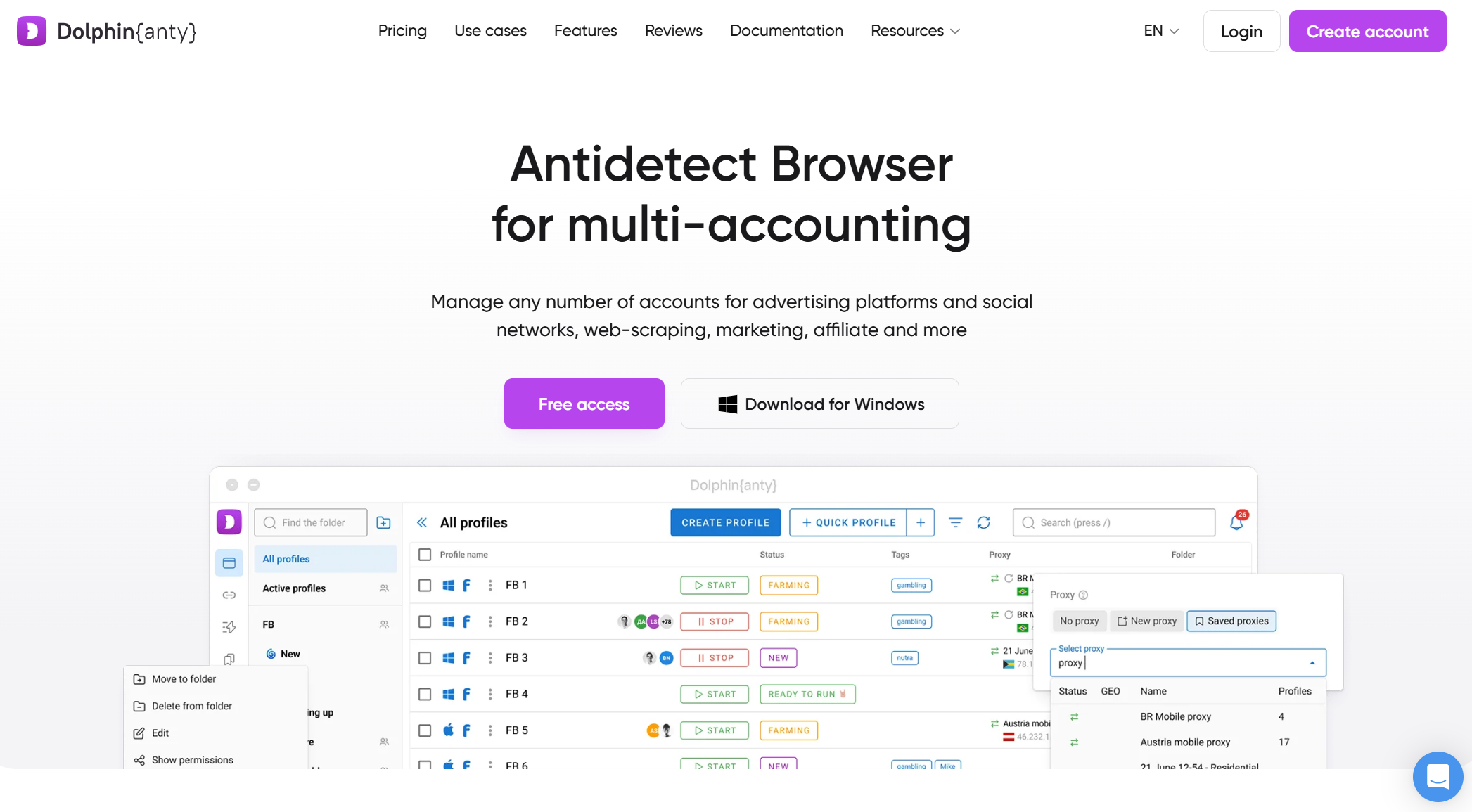
Dolphin{Anty} es una excelente opción para principiantes o usuarios con presupuesto ajustado. Ofrece una amplia capa gratuita, enmascaramiento básico de huellas dactilares y un rendimiento ligero, lo que lo hace accesible para experimentar con máquinas menos potentes. Sin embargo, su huella digital es menos sofisticada que la de las herramientas premium, y sus opciones de automatización son limitadas, lo que la hace inadecuada para el raspado pesado o a gran escala contra sistemas avanzados de protección contra bots.
Ventajas:
- Generoso nivel gratuito y bajo coste de entrada
- Configuración sencilla y rendimiento ligero
- Adecuado para el aprendizaje y la experimentación
Contras:
- Capacidades limitadas de automatización y API
- Suplantación de huellas dactilares más débil en comparación con las herramientas premium
- No es ideal para objetivos de alta seguridad
Casos de uso ideales:
- Principiantes aprendiendo web scraping
- Proyectos de scraping pequeños y de bajo riesgo
- Usuarios con presupuesto limitado
Mejores prácticas para el uso de navegadores antidetect para el scraping web
Un navegador antidetección es más eficaz cuando se utiliza como parte de una estrategia integral de scraping. Las siguientes mejores prácticas son esenciales para lograr resultados fiables y duraderos.
- Emparejarse con proxies de alta calidad
Un navegador antidetección enmascara tu dispositivo, pero se necesita un proxy para ocultar tu identidad de red. Cada perfil debe emparejarse con un proxy dedicado y de alta calidad (residencial o de centro de datos) para evitar ser señalado. Gestionar cuidadosamente la rotación de IP por sesión es fundamental para evitar parecer antinatural.
- Utiliza huellas digitales únicas del navegador
El objetivo principal de un navegador antidetección es asegurar que cada sesión parezca única. Evita clonar perfiles sin permitir que el navegador genere nuevas variaciones realistas de huellas dactilares. Reutilizar los mismos elementos de huellas dactilares en diferentes perfiles crea un patrón que los sistemas de detección pueden identificar fácilmente.
- Aislar Galletas y Sesiones
Asegúrate de que las cookies, el almacenamiento local y los datos almacenados en caché estén completamente separados para cada perfil. Este aislamiento es crucial para evitar que los sitios web vinculen tus diferentes identidades de scraping, especialmente cuando se trabaja con cuentas iniciadas sesión o al ejecutar varios scrapers simultáneamente.
- Combinarse con bibliotecas de automatización
Para cualquier tarea que no sea la navegación manual, integra tu navegador antidetect con librerías de automatización como Puppeteer o Selenium. Esto permite gestionar programáticamente perfiles, proxies y lógica de scraping, lo que aumenta la eficiencia y reduce el error humano.
- Imitar comportamiento humano
Incluso con una huella perfecta, el comportamiento tipo bot puede hacer que te bloqueen. La lógica de raspado debe estar diseñada para parecer natural. Introduce retrasos aleatorios entre clics, varía los patrones de movimiento del ratón y evita navegar por una web con exactamente el mismo camino cada vez.
Errores comunes al usar navegadores antidetect para extraer web
Incluso los mejores ajustes pueden fallar si no conoces los errores comunes. Aquí tienes varios problemas a los que debes prestar atención.
- Comportamiento inusual de la red
Enviar demasiadas solicitudes en poco tiempo, tocar repetidamente los mismos puntos finales o usar un tiempo predecible puede activar sistemas de detección, independientemente de la calidad de tu huella dactilar. Esto suele dar lugar a CAPTCHAs o bloqueos temporales.
- Navegadores de baja calidad o gratuitos
Los navegadores anti-detección gratuitos o muy baratos pueden usar plantillas de huellas dactilares recicladas o limitadas. Con el tiempo, los sistemas de detección aprenden a reconocer estas huellas dactilares comunes, lo que provoca que una configuración que antes funcionaba empiece a fallar.
- Dependencia excesiva solo del navegador
Tratar un navegador antidetección como una solución independiente es un error. Una huella dactilar impecable es inútil si se emite desde una IP marcada o muestra comportamiento robótico. Un enfoque holístico que integre las mejores prácticas de gestión de proxy y un momento similar al humano es innegociable.
- Consideraciones éticas y legales
La capacidad técnica no prevalece sobre los términos de servicio de un sitio web ni las leyes locales. Antes de extraer información, entiende qué datos estás recopilando, cómo se utilizarán y si aplican normas o normativas legales de la plataforma.
Cómo elegir los navegadores antidetección adecuados para el web scraping
Elegir el navegador adecuado consiste en adaptar una herramienta a tu flujo de trabajo específico. Utiliza esta lista de comprobación para guiar tu decisión.
Un proyecto pequeño y puntual tiene necesidades muy diferentes a un sistema continuo y de recogida de datos a gran escala. Para tareas limitadas o experimentos iniciales, una herramienta como Dolphin{Anty} con su generoso nivel gratuito es un punto de partida práctico. Para el scraping continuo y a gran escala donde la estabilidad y la automatización son fundamentales, deberías evaluar opciones como DICloak o Multilogin.
Evalúa el coste en términos de fiabilidad y tiempo ahorrado, no solo la cuota mensual de suscripción. Los bloques frecuentes y el rendimiento inestable pueden costar mucho más en pérdida de datos y tiempo de desarrollo que una herramienta más cara pero fiable.
- Adapta las características a tu flujo de trabajo
Identifica tus características imprescindibles antes de empezar a buscar. ¿Necesitas una API robusta, ejecución en la nube o funciones de colaboración en equipo? Elige un navegador que destaque en lo que necesitas y evita pagar por funciones que no vas a usar.
Los desarrolladores valorarán la robusta API y las capacidades de automatización para una integración fluida, mientras que los equipos que priorizan la facilidad de uso frente a la automatización profunda pueden encontrar otras soluciones más acomodadas. Además, considera la compatibilidad de plataformas y si la emulación móvil es un requisito clave para tus necesidades de scraping.
- Mira más allá de las características hacia la estabilidad y la reputación
Un buen navegador antidetección debe actualizarse regularmente para estar al día con los nuevos métodos de detección. Consulta la opinión de la comunidad, la calidad de la documentación y la frecuencia de actualizaciones para evaluar la fiabilidad a largo plazo de una herramienta. La estabilidad suele ser más valiosa que una larga lista de características.
Conclusión: Recomendaciones finales para navegadores antidetect para web scraping
Los navegadores antidetect para web scraping se han convertido en herramientas esenciales para cualquier operación seria de web scraping en 2026. Debido a que los sitios web modernos utilizan sistemas de detección por capas, los métodos tradicionales de automatización ya no son fiables. No existe un navegador único "mejor" para todos; La elección correcta depende totalmente de la escala, el presupuesto y las necesidades técnicas de tu proyecto. Definiendo claramente tu caso de uso, puedes seleccionar una herramienta que mejore la fiabilidad y longevidad de tus operaciones de scraping .
Recomendaciones rápidas:
- Principiantes o proyectos pequeños: DICloak o Dolphin Anty ofrecen puntos de entrada accesibles con sus efectivos niveles gratuitos.
- Flujos de trabajo profesionales de scraping: DICloak ofrece un sólido equilibrio entre fiabilidad, automatización y escalabilidad cuando se combina con proxies de alta calidad.
- Scraping a gran escala o empresarial: Multilogin es ideal para entornos complejos que requieren un control profundo de huellas digitales y estabilidad, aunque tiene un coste mayor.
Preguntas frecuentes sobre navegadores antidetección para extracción web
¿Cuál es la diferencia entre los navegadores antidetect para web scraping y un navegador sin interfaz gráfica estándar?
Un navegador sin interfaz gráfica estándar a menudo expone señales de huellas dactilares predeterminadas o incompletas que se detectan fácilmente como automatización. Los navegadores antidetección para web scraping están diseñados específicamente para crear y gestionar huellas únicas y realistas que parecen un usuario humano normal, asegurando que tus operaciones de web scraping sean indetectables.
¿Puedo usar un navegador antidetect gratuito para un proyecto serio de scraping?
Aunque son excelentes para aprender, la mayoría de los niveles gratuitos son arriesgados para proyectos serios debido a las limitaciones en la calidad de las huellas dactilares y la automatización. A menudo dependen de plantillas de huellas dactilares recicladas, que tienen más probabilidades de ser reconocidas y bloqueadas con el tiempo, como se menciona en los errores comunes de los navegadores antidetección para el web scraping.
¿Sigo teniendo que preocuparme por los CAPTCHAs cuando uso navegadores antidetect para web scraping?
Sí. Un navegador antidetect para web scraping reduce significativamente la probabilidad de encontrar CAPTCHAs al enmascarar tu huella digital, pero no puede prevenirlos por completo. Comportamientos antinaturales, como tasas de peticiones muy altas, pueden seguir provocando desafíos con CAPTCHA, incluso cuando se utilizan navegadores antidetect para webscraping.
¿Es posible que una web detecte navegadores antidetect para el web scraping?
Sí, es un juego continuo del gato y el ratón. A medida que los sitios web desarrollan nuevas técnicas de detección, los navegadores antidetección para desarrolladores de web scraping deben actualizar su software para contrarrestarlas. Por eso, elegir un navegador con actualizaciones regulares y una sólida reputación es crucial para el éxito a largo plazo en el web scraping.
¿Cuántos perfiles puedo ejecutar a la vez con navegadores antidetect para extraer web?
El número de perfiles que puedes ejecutar simultáneamente depende del hardware de tu ordenador (CPU y RAM) y de la eficiencia de recursos de los navegadores antidetect para el web scraping en sí mismos. Algunos navegadores son más ligeros que otros, por lo que es importante probar el rendimiento según tu configuración específica y las exigencias de tu operación de web scraping .
 Herramientas gratuitas
Herramientas gratuitas Complemento de cookies
Complemento de cookies Generador UA
Generador UA Generador de direcciones MAC
Generador de direcciones MAC Generador de IP
Generador de IP Lista de direcciones IP
Lista de direcciones IP Generador de código 2FA
Generador de código 2FA Reloj Mundial
Reloj Mundial Cheque Anónimo
Cheque Anónimo WebRTC Leak Test
WebRTC Leak Test Generador UUID
Generador UUID Verificador de Proxy
Verificador de Proxy Verificador de anuncios de Facebook
Verificador de anuncios de Facebook Raspado web con IA
Raspado web con IA Herramientas SMM Gratis
Herramientas SMM Gratis Verificador de Sombreado de Twitter
Verificador de Sombreado de Twitter Generador UTM
Generador UTM Generador de usernames
Generador de usernames Generador de hashtags con IA
Generador de hashtags con IA Generador de titulares para LinkedIn
Generador de titulares para LinkedIn Redimensionador de imágenes sociales
Redimensionador de imágenes sociales







