O web scraping em 2026 é mais sobre a longevidade do scraper do que apenas sobre funcionalidade. Os sites modernos utilizam defesas avançadas como a impressão digital do navegador para identificar e bloquear scripts automatizados, dificultando o funcionamento fiável dos scrapers ao longo do tempo. Os navegadores antideteção são a solução essencial para este problema, permitindo que os scrapers apareçam como visitantes humanos únicos. Este artigo irá analisar os navegadores antideteção mais eficazes para web scraping, avaliar os seus pontos fortes e fracos, e fornecer um guia claro para escolher a ferramenta certa para as suas necessidades específicas.
Porque Precisa de Navegadores Antidetect para Web Scraping
Um navegador antideteção é um navegador especializado concebido para mascarar ou controlar a impressão digital do utilizador. Em vez de revelar os sinais padrão de uma ferramenta automatizada, apresenta um perfil realista e consistente que imita um utilizador real num dispositivo único. Os sistemas anti-bot modernos analisam combinações de fatores — incluindo endereço IP, cookies, user-agent, resolução do ecrã, fontes, WebGL e renderização Canvas — para detetar automação. Quando estes sinais são inconsistentes, o sistema sinaliza o tráfego como suspeito.
Esta inconsistência é precisamente onde as ferramentas padrão de automação, como os navegadores headless, muitas vezes falham. Tendem a expor impressões digitais incompletas ou invulgares que os sistemas de deteção rapidamente aprendem e bloqueiam. Isto força os raspadores a entrarem num ciclo de resolução de puzzles CAPTCHA e rotação de proxies em vez de recolher dados. Os navegadores antideteção resolvem isto isolando cada sessão de scraping num seu próprio perfil, completo com uma impressão digital única, cookies, armazenamento local e um proxy dedicado. Esta abordagem faz com que o tráfego de um único scraper pareça provinente de muitos utilizadores reais diferentes.
Os Limites dos Navegadores Antideteção
Sejamos claros: os navegadores antideteção não são uma solução mágica. Não conseguem corrigir má lógica de scraping, taxas de pedidos irrealistas ou má gestão de proxys. A principal função destes navegadores é remover uma camada principal de deteção — a impressão digital do navegador. Isto dá a uma estratégia de scraping bem desenhada e gerida de forma responsável a hipótese de ter sucesso onde de outra forma falharia.
Critérios-Chave para Avaliar Navegadores Antidetect para Web Scraping
Nem todos os navegadores antideteção foram concebidos tendo o web scraping como principal propósito. Para escolher a ferramenta certa, é importante compreender os principais critérios de avaliação a partir de uma perspetiva de scraping.
Qualidade de Falsificação de Impressões Digitais
A falsificação de impressões digitais de alta qualidade consiste em apresentar um conjunto consistente de sinais de navegador. Os sistemas de deteção podem facilmente assinalar inconsistências, como um agente de utilizador do Windows combinado com renderização de fontes no macOS. As melhores ferramentas automatizam a criação de impressões digitais realistas e consistentes para evitar erros manuais de configuração que conduzam à deteção.
A sua conclusão: Priorize navegadores que automatizem a geração de impressões digitais consistentes e realistas em detrimento daqueles que exigem ajustes manuais complexos.
Proxy e Integração de Rede
A falsificação de impressões digitais é inútil sem proxies de alta qualidade. Um bom navegador antideteção deve suportar de forma fluida tipos proxy comuns como HTTP, HTTPS e SOCKS5. Deve também fornecer funcionalidades de gestão eficiente, como a capacidade de atribuir um proxy único a cada perfil e rodá-los conforme necessário.
A sua conclusão: O navegador deve oferecer uma integração robusta com proxies residenciais, de centros de dados ou móveis e permitir uma gestão fácil por perfil.
Isolamento de Perfil e Cookies
A fuga de sessões, onde cookies ou dados de armazenamento local de um perfil se misturam com outro, pode ligar instantaneamente identidades separadas e bloqueá-las. Para raspar páginas logadas ou executar trabalhos simultâneos, o isolamento total entre perfis é uma funcionalidade inegociável.
A sua conclusão: Cada perfil de navegador deve ter os seus próprios cookies, armazenamento local e cache completamente separados para evitar contaminação cruzada.
Automação e Integração de APIs
Para qualquer operação séria de web scraping, a automação é essencial. Um navegador antideteção adequado deve ter acesso robusto à API e ser compatível com frameworks de automação comuns como o Puppeteer ou o Selenium. Algumas ferramentas comercializam a automação como um pensamento tardio, o que se torna evidente ao integrá-las num fluxo de trabalho de scraping. Sem estas capacidades, escalar operações para além de algumas execuções manuais é quase impossível.
A sua conclusão: Uma API local ou cloud forte e compatibilidade com bibliotecas de automação padrão são críticas para escalar fluxos de trabalho de scraping.
Escalabilidade e Desempenho
Um navegador pode funcionar bem com alguns perfis, mas tem dificuldades ao gerir centenas. Os principais fatores de desempenho incluem o uso de recursos (CPU e RAM), o tempo de arranque do perfil e a estabilidade geral sob carga pesada. É fundamental avaliar como um navegador se comporta na escala que pretende operar.
A sua conclusão: Para projetos de grande escala, avalie o consumo de recursos do navegador, a frequência de falhas e o desempenho ao longo de períodos prolongados.
Usabilidade e Gestão de Perfis
Ao gerir dezenas ou centenas de perfis, as funcionalidades de usabilidade tornam-se críticas para a eficiência. Uma interface desajeitada pode atrasar os fluxos de trabalho e levar a erros de configuração dispendiosos. Procure funcionalidades como criação de perfis em bloco, modelos, atribuição rápida de proxy e indicadores de estado claros.
A sua conclusão: Uma interface intuitiva com ferramentas robustas de gestão de perfis poupa tempo e reduz o risco de erros.
Modelo de Preço e Licenciamento
Os modelos de preços variam desde custos por perfil até subscrições em níveis com conjuntos de funcionalidades variados. Para o scraping profissional, o valor da fiabilidade e automação muitas vezes supera o preço mensal mais baixo. A chave é escolher um modelo que corresponda à escala e aos requisitos técnicos do seu projeto.
A sua conclusão: Avalie os preços com base no valor global que isso traz ao seu fluxo de trabalho, não apenas na taxa mensal.
Comparando os Principais Navegadores Antideteção para Web Scraping em 2026
| Falsificação |
de Impressão Digital do Navegador Suporte |
a Proxy |
de Qualidade Automação/Capacidades de API |
Preço/Nível |
Caso de Uso Ideal |
| DICloak |
Isolamento de alta fidelidade (Canvas, WebGL, WebRTC) |
HTTP / HTTPS / SOCKS5, Gestão de grupos Proxy |
RPA Automate, Local API |
Grátis (5 perfis). Pago a partir de ~$8/mês. |
Web Scraping escalável, partilha de contas, comércio eletrónico e gestão de contas sociais. |
| Multilogin |
Controlo manual profundo (Canvas, WebGL) |
Tunelamento HTTP/SOCKS5/SSH |
API local robusta (Selenium/Puppeteer) |
~€99/mês (Plano de Escala). Não há nível gratuito. |
Segurança Empresarial, Grandes Agências, Gestão de Contas de Alto Valor. |
| Octo Browser |
Base de dados de impressões digitais de dispositivos reais |
HTTP/SOCKS5/SSH |
API rápida e leve |
~29€/mês (Entrada). Descontos por volume disponíveis. |
Tarefas críticas de velocidade, apostas/criptomoedas, scraping de média escala. |
| AdsPower |
Risco de deteção sólido mas mais elevado |
APIs proxy integradas pelo fornecedor |
RPA + API Local básica |
~$9/mês (Base). Modelo flexível de "Pagamento por perfil". |
Não-Programadores, Automação de Comércio Eletrónico, Marketing. |
| Dolphin {Anty} |
Impressões digitais focadas em plataformas |
Gestor de proxy incorporado |
Scripts básicos, API limitada |
Grátis (10 Perfis). Começas pagos ~$10/mês. |
Marketing de Afiliados, Raspagem nas Redes Sociais, Iniciantes. |
Visão geral dos principais navegadores antideteção para web scraping em 2026
Aqui estão os navegadores antideteção capazes para web scraping que servem diferentes necessidades e casos de uso.
DICloak
O DICloak é um navegador antideteção robusto, concebido para fornecer aos utilizadores uma solução integrada e escalável para o web scraping. Destaca-se no mercado por oferecer infraestrutura baseada na cloud, isolamento avançado de impressões digitais e suporte de automação, tornando-o ideal para operações de web scraping que exigem indetetabilidade, escalabilidade e eficiência. Ao contrário dos navegadores tradicionais, o DICloak permite aos utilizadores gerir múltiplos perfis com impressões digitais distintas, garantindo que as atividades de web scraping permaneçam despercebidas e não acionem medidas anti-bot comuns em sites modernos.
A capacidade do DICloak para gerir trabalhos de scraping em grande escala, mantendo a privacidade da conta e a estabilidade do perfil, distingue-o dos concorrentes. A sua configuração personalizada de proxy e funcionalidades de colaboração em equipa tornam-na uma ferramenta poderosa para utilizadores que necessitam de um navegador antideteção seguro, escalável e fácil de usar para scraping, especialmente nos setores de comércio eletrónico, marketing digital e estudos de mercado.
Prós:
- A infraestrutura cloud da DICloak escala tarefas de scraping sem sobrecarregar os recursos locais.
- Ele mascara efetivamente as impressões digitais do navegador, garantindo um raspagem indetetável.
- O DICloak oferece gestão flexível de proxy para evitar blocos IP durante o scraping.
- A RPA automatiza tarefas de scraping de grande volume entre perfis.
- O DICloak permite uma colaboração de equipa fluida com gestão multi-perfil.
- Concebido para facilitar a utilização, tornando-o acessível tanto para iniciantes como para especialistas.
Contras:
- Suporta apenas dispositivos de secretária (sem aplicações móveis)
- Apenas o navegador Orbita baseado em Chromium
Casos de uso ideais:
- Projetos profissionais de web scraping
- Equipas de dados e programadores que executam pipelines automáticos de raspagem
- Raspagem de média a grande escala onde a estabilidade é importante
Multilogin
O multilogin é uma opção poderosa e de longa data para operações de scraping em grande escala. Oferece um controlo profundo e granular sobre parâmetros de impressão digital como Canvas e WebGL e suporta motores de navegador baseados em Chromium e Firefox. A sua força reside na gestão de milhares de perfis com isolamento robusto de sessões, tornando-o uma escolha de topo para projetos a nível empresarial. No entanto, o seu poder vem acompanhado de um preço mais elevado e de uma curva de aprendizagem mais íngreme. Ao contrário do DICloak, que oferece um navegador baseado na cloud para descarregar o consumo de recursos, as operações do Multilogin dependem tipicamente de recursos locais do sistema, o que pode ser um fator significativo ao executar centenas de perfis.
Prós:
- Mascaramento de impressão digital muito forte com controlo granular
- Suporta múltiplos motores de navegador (Chromium, Firefox)
- Estabilidade comprovada para raspagem em grande escala
- Automação sólida e suporte de API
Contras:
- Caro comparado com a maioria dos concorrentes
- Curva de aprendizagem mais íngreme para novos utilizadores
- Uso local mais intenso de recursos em larga escala
Casos de uso ideais:
- Operações de raspagem ao nível empresarial
- Equipas a raspar alvos de alta segurança ou de alto valor
- Utilizadores que necessitam de personalização manual profunda das impressões digitais
Octo Browser
O Octo Browser é uma escolha popular para tarefas de scraping de média dimensão, posicionando-se num meio-termo entre soluções de entrada e empresariais. Proporciona falsificação fiável de impressões digitais sem sobrecarregar os utilizadores com definições complexas. O Octo Browser oferece acesso à API e suporta fluxos de trabalho comuns de automação, proporcionando desempenho estável com uso moderado de recursos em hardware padrão.
Prós:
- Boa qualidade de impressão digital para a maioria dos cenários de raspagem
- Preços razoáveis comparados com ferramentas empresariais
- Interface limpa e gestão simples de perfis
- Adequado para automação com frameworks comuns
Contras:
- Funcionalidades de automação menos avançadas do que as ferramentas de topo
- Pode ter dificuldades contra os sistemas de deteção mais agressivos
Casos de uso ideais:
- Freelancers e equipas pequenas
- Projetos de raspagem e extração de dados de média escala
- Utilizadores que querem funcionalidades sólidas sem preços empresariais
AdsPower
O AdsPower é principalmente conhecido pela gestão de múltiplas contas, mas também é utilizado para scraping, especialmente quando a organização de perfis é uma prioridade. Tem uma interface amigável e suporta técnicas padrão de mascaramento por impressão digital. A sua principal limitação para o scraping é a profundidade de automação, que não é tão flexível como ferramentas concebidas especificamente para extração de dados. Isto torna-o mais adequado para tarefas de scraping mais leves ou semi-automatizadas, como a automação do comércio eletrónico (Amazon/eBay).
Prós:
- Interface fácil de usar com forte gestão de perfis
- Suporte amplo de proxy e integrações com fornecedores
- Preços acessíveis com planos flexíveis
Contras:
- As funcionalidades de automação são mais limitadas para scraping em grande escala
- A falsificação de impressões digitais é sólida, mas não é líder na indústria
Casos de uso ideais:
- Projetos de raspagem pequenos a médios
- Utilizadores que combinam scraping com fluxos de trabalho multi-conta
- Equipas que priorizam a usabilidade em detrimento da automação profunda
Dolphin{Anty}
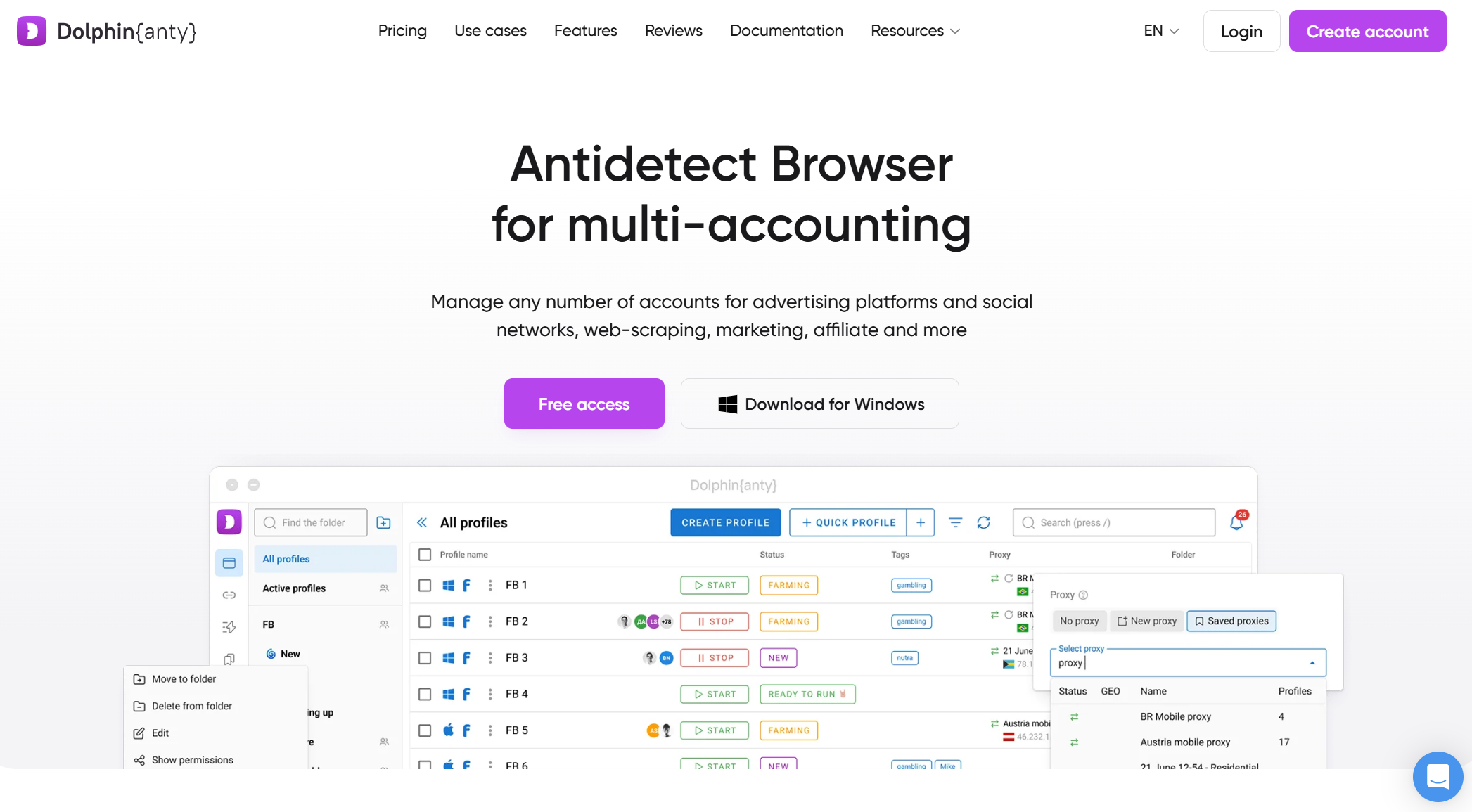
Dolphin{Anty} é uma excelente escolha para iniciantes ou utilizadores com orçamento apertado. Oferece um nível gratuito generoso, mascaramento básico de impressões digitais e desempenho leve, tornando-o acessível para experimentação em máquinas menos potentes. No entanto, a sua impressão digital é menos sofisticada do que as ferramentas premium, e as suas opções de automação são limitadas, tornando-a inadequada para raspagem pesada ou em grande escala contra sistemas avançados de proteção contra bots.
Prós:
- Nível gratuito generoso e custo de entrada baixo
- Configuração simples e desempenho leve
- Adequado para aprendizagem e experimentação
Contras:
- Automação limitada e capacidades de API
- Falsificação de impressão digital mais fraca em comparação com ferramentas premium
- Não é ideal para alvos de alta segurança
Casos de uso ideais:
- Iniciantes a aprender web scraping
- Pequenos projetos de raspagem de baixo risco
- Utilizadores com orçamento limitado
Melhores Práticas para Utilização de Navegadores Antideteção para Web Scraping
Um navegador antideteção é mais eficaz quando utilizado como parte de uma estratégia abrangente de scraping. As seguintes boas práticas são essenciais para alcançar resultados fiáveis e duradouros.
- Emparelhar com Proxies de Alta Qualidade
Um navegador antideteto mascara o seu dispositivo, mas é necessário um proxy para mascarar a identidade da sua rede. Cada perfil deve ser emparelhado com um proxy dedicado e de alta qualidade (residencial ou centro de dados) para evitar ser sinalizado. Gerir cuidadosamente a rotação de IP por sessão é fundamental para evitar parecer antinatural.
- Use impressões digitais únicas do navegador
O principal objetivo de um navegador antideteção é garantir que cada sessão pareça única. Evite clonar perfis sem permitir que o navegador gere novas variações realistas das impressões digitais. Reutilizar os mesmos elementos de impressão digital em diferentes perfis cria um padrão que os sistemas de deteção conseguem identificar facilmente.
Garanta que os cookies, o armazenamento local e os dados em cache são completamente separados para cada perfil. Este isolamento é crucial para evitar que os sites associem as suas diferentes identidades de scraping, especialmente ao trabalhar com contas iniciadas ou a executar múltiplos scrapers em simultâneo.
- Combinar com Bibliotecas de Automação
Para qualquer tarefa para além da navegação manual, integra o teu navegador antidetect com bibliotecas de automação como o Puppeteer ou o Selenium. Isto permite gerir programaticamente perfis, proxies e lógica de scraping, o que aumenta a eficiência e reduz o erro humano.
- Imitar Comportamento Semelhante ao Humano
Mesmo com uma impressão digital perfeita, comportamentos semelhantes a bots podem fazer com que seja bloqueado. A lógica de raspagem deve ser desenhada para parecer natural. Introduza atrasos aleatórios entre cliques, varie os padrões de movimento do rato e evite navegar por um site com exatamente o mesmo caminho todas as vezes.
Armadilhas Comuns ao Utilizar Navegadores Antideteção para Raspagem Web
Mesmo os melhores setups podem falhar se não estiveres ciente das armadilhas comuns. Aqui estão vários problemas a ter em atenção.
- Comportamento invulgar da rede
Enviar demasiados pedidos num curto período, atingir repetidamente os mesmos endpoints ou usar temporizações previsíveis pode desencadear sistemas de deteção, independentemente da qualidade das suas impressões digitais. Isto resulta frequentemente em CAPTCHAs ou bloqueios temporários.
- Navegadores de baixa qualidade ou gratuitos
Navegadores anti-deteção gratuitos ou muito baratos podem usar modelos de impressões digitais reciclados ou limitados. Com o tempo, os sistemas de deteção aprendem a reconhecer estas impressões digitais comuns, fazendo com que uma configuração que antes funcionava comece a falhar.
- Dependência Excessiva Apenas do Navegador
Tratar um navegador antideteção como uma solução autónoma é um erro. Uma impressão digital imaculada é inútil se for transmitida a partir de um IP sinalizado ou se apresentar comportamento robótico. Uma abordagem holística que integre as melhores práticas de gestão por procuração e um timing semelhante ao humano é inegociável.
- Considerações Éticas e Legais
A capacidade técnica não prevalece sobre os termos de serviço do site nem as leis locais. Antes de extrair, compreenda que dados está a recolher, como serão usados e se se aplicam regras ou regulamentos legais da plataforma.
Como Escolher os Navegadores Antideteção Certos para Web Scraping
Escolher o navegador certo é sobre adaptar uma ferramenta ao seu fluxo de trabalho específico. Use esta lista de verificação para orientar a sua decisão.
Um projeto pequeno e pontual tem necessidades muito diferentes de um sistema contínuo e de recolha de dados em grande escala. Para tarefas limitadas ou experiências iniciais, uma ferramenta como o Dolphin{Anty} com o seu generoso nível gratuito é um ponto de partida prático. Para scraping contínuo e em grande escala, onde a estabilidade e a automação são fundamentais, deves avaliar opções como DICloak ou Multilogin.
- Considere o Seu Orçamento
Avalie o custo em termos de fiabilidade e tempo poupado, não apenas a taxa mensal de subscrição. Blocos frequentes e desempenho instável podem custar muito mais em dados perdidos e tempo de desenvolvimento do que uma ferramenta mais cara mas fiável.
- Adapte as Funcionalidades ao Seu Fluxo de Trabalho
Identifique as suas características essenciais antes de começar a procurar. Precisa de uma API robusta, de execução na cloud ou de funcionalidades de colaboração em equipa? Escolha um navegador que se destaque no que precisa e evite pagar por funcionalidades que não vai usar.
- Avalie o Seu Perfil Técnico
Os programadores irão apreciar as robustas capacidades de API e automação para uma integração fluida, enquanto as equipas que priorizam a facilidade de utilização em detrimento da automação profunda poderão achar outras soluções mais adequadas. Além disso, considere a compatibilidade da plataforma e se a emulação móvel é um requisito fundamental para as suas necessidades de scraping.
- Olhe para além das funcionalidades, em direção à estabilidade e reputação
Um bom navegador antideteção deve ser atualizado regularmente para acompanhar os novos métodos de deteção. Verifique o feedback da comunidade, a qualidade da documentação e a frequência das atualizações para avaliar a fiabilidade a longo prazo de uma ferramenta. A estabilidade é frequentemente mais valiosa do que uma longa lista de funcionalidades.
Conclusão: Recomendações Finais para Navegadores Antideteção para Web Scraping
Os navegadores antideteção para web scraping tornaram-se ferramentas essenciais para qualquer operação séria de web scraping em 2026. Como os sites modernos utilizam sistemas de deteção em camadas, os métodos tradicionais de automação deixaram de ser fiáveis. Não existe um único navegador "melhor" para todos; A escolha certa depende inteiramente da escala, orçamento e necessidades técnicas do seu projeto. Ao definir claramente o seu caso de uso, pode selecionar uma ferramenta que melhore a fiabilidade e longevidade das suas operações de scraping .
Recomendações rápidas:
- Iniciantes ou pequenos projetos: DICloak ou Dolphin Anty oferecem pontos de entrada acessíveis com os seus eficazes níveis gratuitos.
- Fluxos de trabalho profissionais de scraping: O DICloak oferece um forte equilíbrio entre fiabilidade, automação e escalabilidade quando combinado com proxies de alta qualidade.
- Scraping em grande escala ou empresarial: O multilogin é adequado para ambientes complexos que exigem controlo profundo de impressões digitais e estabilidade, embora tenha um custo mais elevado.
Perguntas Frequentes sobre Navegadores Antidetect para Web Scraping
Qual é a diferença entre navegadores antidetect para web scraping e um navegador headless padrão?
Um navegador headless padrão frequentemente expõe sinais de impressão digital padrão ou incompletos que são facilmente detetados como automação. Os navegadores antideteção para web scraping são especificamente concebidos para criar e gerir impressões digitais únicas e realistas para parecer um utilizador humano normal, garantindo que as suas operações de web scraping sejam indetetáveis.
Posso usar um navegador antideteção gratuito para um projeto sério de scraping?
Embora excelente para aprendizagem, a maioria dos níveis gratuitos é arriscada para projetos sérios devido às limitações na qualidade das impressões digitais e automação. Muitas vezes dependem de modelos reciclados de impressões digitais, que têm maior probabilidade de serem reconhecidos e bloqueados ao longo do tempo, como mencionado nas armadilhas comuns dos navegadores antideteção para web scraping.
Ainda preciso de me preocupar com CAPTCHAs ao usar navegadores antidetect para web scraping?
Sim. Um navegador antideteção para web scraping reduz significativamente a probabilidade de encontrar CAPTCHAs ao mascarar a sua impressão digital, mas não pode preveni-los totalmente. Comportamentos não naturais, como taxas de pedido muito elevadas, podem ainda assim desencadear desafios CAPTCHA, mesmo ao usar navegadores antideteção para web scraping.
É possível um site detetar navegadores antideteção para web scraping?
Sim, é um jogo contínuo de gato e rato. À medida que os websites desenvolvem novas técnicas de deteção, os navegadores antideteção para desenvolvedores de web scraping têm de atualizar o seu software para os contrariar. É por isso que escolher um navegador com atualizações regulares e uma forte reputação é crucial para o sucesso a longo prazo no web scraping.
Quantos perfis posso correr ao mesmo tempo com navegadores antideteção para web scraping?
O número de perfis que pode executar simultaneamente depende do hardware do seu computador (CPU e RAM) e da eficiência de recursos dos navegadores antideteção para o web scraping em si. Alguns navegadores são mais leves do que outros, por isso é importante testar o desempenho com base na sua configuração específica e nas exigências da sua operação de web scraping .
 Ferramentas Gratuitas
Ferramentas Gratuitas Cookie Plugin
Cookie Plugin Gerador de UA
Gerador de UA Gerador de Endereço MAC
Gerador de Endereço MAC Gerador de Endereço IP
Gerador de Endereço IP Lista de Endereços IP
Lista de Endereços IP Gerador de Código 2FA
Gerador de Código 2FA Relógio Mundial
Relógio Mundial Verificação de Anonimato
Verificação de Anonimato WebRTC Leak Test
WebRTC Leak Test Gerador de UUID
Gerador de UUID Verificador de Proxy
Verificador de Proxy Verificador de Anúncios FB
Verificador de Anúncios FB Coleta Web com IA
Coleta Web com IA Ferramentas SMM Grátis
Ferramentas SMM Grátis Verificador de Shadowban do Twitter
Verificador de Shadowban do Twitter Verificador de Nomes do Instagram
Verificador de Nomes do Instagram Gerador UTM
Gerador UTM Gerador de nomes de usuário
Gerador de nomes de usuário Gerador de hashtags com IA
Gerador de hashtags com IA Gerador de títulos para LinkedIn
Gerador de títulos para LinkedIn Redimensionador de imagens sociais
Redimensionador de imagens sociais







