Le web scraping en 2026 concerne davantage la longévité du scraper que la simple fonctionnalité. Les sites web modernes utilisent des défenses avancées comme l’empreinte digitale par navigateur pour identifier et bloquer les scripts automatisés, rendant difficile le fonctionnement fiable des scrapers sur le long terme. Les navigateurs antidétection sont la solution essentielle à ce problème, permettant aux scrapers d’apparaître comme des visiteurs humains uniques. Cet article passera en revue les navigateurs antidétection les plus efficaces pour le web scraping, évaluera leurs forces et faiblesses, et fournira un guide clair pour choisir l’outil adapté à vos besoins spécifiques.
Pourquoi avoir besoin de navigateurs antidétection pour le web scraping
Un navigateur antidétection est un navigateur spécialisé conçu pour masquer ou contrôler l’empreinte digitale d’un utilisateur. Au lieu de révéler les signaux standards d’un outil automatisé, il présente un profil réaliste et cohérent qui imite un utilisateur réel sur un appareil unique. Les systèmes anti-bots modernes analysent des combinaisons de facteurs — y compris l’adresse IP, les cookies, l’agent utilisateur, la résolution d’écran, les polices, WebGL et le rendu Canvas — afin de détecter l’automatisation. Lorsque ces signaux sont incohérents, le système signale le trafic comme suspect.
C’est précisément cette incohérence qui fait souvent défaut avec les outils d’automatisation standards comme les navigateurs sans interface graphique. Ils ont tendance à révéler des empreintes digitales incomplètes ou inhabituelles que les systèmes de détection apprennent et bloquent rapidement. Cela force les scrapers à s’engager dans un cycle de résolution d’énigmes CAPTCHA et de rotation de proxies au lieu de collecter des données. Les navigateurs antidétection résolvent ce problème en isolant chaque session de scraping dans son propre profil, avec une empreinte digitale unique, des cookies, un stockage local et un proxy dédié. Cette approche fait paraître le trafic provenant d’un seul scraper provenant de nombreux utilisateurs réels différents.
Les limites des navigateurs antidétection
Soyons clairs : les navigateurs antidétection ne sont pas une solution miracle. Ils ne peuvent pas corriger une mauvaise logique de scraping, des taux de requêtes irréalistes ou une mauvaise gestion des proxys. La fonction principale de ces navigateurs est de supprimer une couche majeure de détection — l’empreinte digitale du navigateur. Cela donne à une stratégie de scraping bien conçue et gérée de manière responsable une chance de réussir là où elle échouerait autrement.
Critères clés pour évaluer les navigateurs Antidetect pour le web scraping
Tous les navigateurs anti-détection ne sont pas conçus avec le web scraping comme fonction principale. Pour choisir le bon outil, il est important de comprendre les critères clés d’évaluation du point de vue du scraping.
Qualité de l’usurpation d’empreintes digitales
L’usurpation d’empreintes digitales de haute qualité consiste à présenter un ensemble cohérent de signaux de navigateur. Les systèmes de détection peuvent facilement signaler des incohérences, comme un agent utilisateur Windows combiné au rendu de polices sur macOS. Les meilleurs outils automatisent la création d’empreintes digitales réalistes et cohérentes afin d’éviter des erreurs manuelles de configuration qui entraînent la détection.
Votre retien : Privilégiez les navigateurs qui automatisent la génération d’empreintes digitales cohérentes et réalistes plutôt que ceux nécessitant des ajustements manuels complexes.
Proxy et intégration réseau
L’usurpation d’empreintes digitales est inutile sans proxies de haute qualité. Un bon navigateur antidétection doit supporter sans interruption les types de proxy courants comme HTTP, HTTPS et SOCKS5. Il doit également offrir des fonctionnalités de gestion efficaces, comme la possibilité d’attribuer un proxy unique à chaque profil et de les faire tourner selon les besoins.
Votre retien : Le navigateur doit offrir une intégration robuste avec des proxies résidentiels, de centres de données ou mobiles et permettre une gestion facile par profil par véhicule.
Isolement du profil et des cookies
La fuite de session, où les cookies ou les données de stockage local d’un profil se rejoignent dans un autre, peut instantanément lier des identités séparées et les bloquer. Pour extraire les pages connectées ou exécuter des tâches simultanées, l’isolation totale entre profils est une fonctionnalité non négociable.
Votre retien : Chaque profil de navigateur doit disposer de ses propres cookies, stockage local et cache complètement séparés pour éviter la contamination croisée.
Automatisation et intégration API
Pour toute opération sérieuse de web scraping, l’automatisation est essentielle. Un navigateur antidétection adapté doit avoir un accès API robuste et être compatible avec des frameworks d’automatisation courants comme Puppeteer ou Selenium. Certains outils commercialisent l’automatisation comme une réflexion après coup, ce qui devient évident lors de leur intégration dans un flux de travail de scraping. Sans ces capacités, il est presque impossible d’étendre les opérations au-delà de quelques exécutions manuelles.
Votre retien : Une API locale ou cloud solide ainsi que la compatibilité avec les bibliothèques d’automatisation standard sont essentielles pour scaler les flux de travail de scraping.
Évolutivité et performances
Un navigateur peut bien fonctionner avec quelques profils mais avoir du mal à gérer des centaines. Les principaux facteurs de performance incluent l’utilisation des ressources (CPU et RAM), le temps de démarrage du profil et la stabilité globale sous une charge importante. Il est crucial d’évaluer les performances d’un navigateur à l’échelle que vous souhaitez exploiter.
Votre retien : Pour les projets à grande échelle, évaluez la consommation de ressources du navigateur, la fréquence des plantages et les performances sur de longues périodes.
Ergonomie et gestion des profils
Lors de la gestion de dizaines ou de centaines de profils, les fonctionnalités d’ergonomie deviennent essentielles pour l’efficacité. Une interface maladroite peut ralentir les flux de travail et entraîner des erreurs de configuration coûteuses. Cherchez des fonctionnalités comme la création de profils en bloc, des modèles, une attribution rapide de proxy et des indicateurs de statut clairs.
Votre retien : Une interface intuitive avec de solides outils de gestion de profil permet de gagner du temps et de réduire le risque d’erreurs.
Prix et modèle de licence
Les modèles tarifaires vont des frais par profil aux abonnements à plusieurs niveaux avec des ensembles de fonctionnalités variés. Pour le scraping professionnel, la valeur de la fiabilité et de l’automatisation dépasse souvent le prix mensuel le plus bas. L’essentiel est de choisir un modèle qui correspond à l’échelle et aux exigences techniques de votre projet.
Votre retien : Évaluez les prix en fonction de la valeur globale qu’il apporte à votre flux de travail, pas seulement des frais mensuels.
Comparaison des meilleurs navigateurs antidétection pour le web scraping en 2026
Qualité
| Usurpation d’empreintes | digitales dans le navigateur | Support Proxy | Automatisation/Capacités API | Prix/Niveau | Cas d’usage idéal |
| DICloak |
Isolation haute fidélité (Canvas, WebGL, WebRTC) |
HTTP / HTTPS / SOCKS5, gestion du groupe proxy |
RPA Automate, API locale |
Gratuit (5 profils). Payé à partir de ~8$/mois. |
Web scraping évolutif, partage de comptes, e-commerce et gestion des comptes sociaux. |
| Multiconnexion |
Contrôle manuel profond (Canvas, WebGL) |
Tunnel HTTP/SOCKS5/SSH |
API locale robuste (Selenium/Puppeteer) |
~99 €/mo. (Plan d’échelle). Pas de palier gratuit. |
Sécurité d’entreprise, grandes agences, gestion de comptes à forte valeur ajoutée. |
| Octo Browser |
Base de données d’empreintes digitales de dispositif réel |
HTTP/SOCKS5/SSH |
API rapide et légère |
~29 €/mois (Démarreur). Des réductions sur le volume sont disponibles. |
Tâches critiques en rapidité, paris/crypto, scraping à moyenne échelle. |
| AdsPower |
Risque de détection solide mais plus élevé |
API proxy intégrées par le fournisseur |
RPA + API locale de base |
~9 $/mois. (Base). Modèle flexible « Paiement par profil ». |
Non-codeurs, automatisation du e-commerce, marketing. |
| Dauphin {Anty} |
Empreintes digitales axées sur la plateforme |
Gestionnaire de proxy intégré |
Scripts basiques, API limitée |
Gratuit (10 profils). Départs payés ~10 $/mois. |
Marketing d’affiliation, scraping sur les réseaux sociaux, débutants. |
Aperçu des principaux navigateurs antidétection pour le web scraping en 2026
Voici les navigateurs antidétection performants pour le web scraping qui répondent à différents besoins et cas d’usage.
DICloak
DICloak est un navigateur antidétection robuste conçu pour offrir aux utilisateurs une solution fluide et évolutive pour le web scraping. Il se distingue sur le marché par ses infrastructures cloud, une isolation avancée des empreintes digitales et un support automatisé, ce qui le rend idéal pour les opérations de web scraping nécessitant indétectabilité, scalabilité et efficacité. Contrairement aux navigateurs traditionnels, DICloak permet aux utilisateurs de gérer plusieurs profils avec des empreintes digitales distinctes, garantissant ainsi que les activités de web scraping restent indétectables et ne déclenchent pas de mesures anti-bots courantes sur les sites web modernes.
La capacité de DICloak à gérer des travaux de scraping à grande échelle tout en maintenant la confidentialité des comptes et la stabilité du profil le distingue de ses concurrents. Sa configuration de proxy personnalisée et ses fonctionnalités de collaboration en équipe en font un outil puissant pour les utilisateurs ayant besoin d’un navigateur antidétection sécurisé, évolutif et facile à utiliser pour le scraping, notamment dans les secteurs du e-commerce, du marketing digital et des études de marché.
Avantages :
- L’infrastructure cloud de DICloak permet de faire évoluer les tâches de scraping sans solliciter les ressources locales.
- Il masque efficacement les empreintes digitales du navigateur, assurant un extraction indétectable.
- DICloak offre une gestion flexible des proxy pour éviter les blocs IP lors du scraping.
- Les RPA automatisent des tâches de scraping à fort volume entre profils.
- DICloak permet une collaboration d’équipe fluide grâce à une gestion multi-profils.
- Conçu pour être facile à utiliser, ce qui le rend accessible aussi bien aux débutants qu’aux experts.
Inconvénients :
- Ne prend en charge que les appareils de bureau (pas d’applications mobiles)
- Seul le navigateur Orbita basé sur Chromium
Cas d’usage idéaux :
- Projets professionnels de web scraping
- Les équipes de données et les développeurs exécutant des pipelines de scraping automatisés
- Raclage à moyenne à grande échelle où la stabilité compte
Multiconnexion
Le multilogin est une option puissante et ancienne pour des opérations de scraping à grande échelle. Il offre un contrôle profond et granulaire des paramètres d’empreintes digitales comme Canvas et WebGL et prend en charge à la fois les moteurs de navigation basés sur Chromium et Firefox. Sa force réside dans la gestion de milliers de profils avec une isolation robuste des sessions, ce qui en fait un choix de premier plan pour les projets de niveau entreprise. Cependant, sa puissance s’accompagne d’un prix plus élevé et d’une courbe d’apprentissage plus raide. Contrairement à DICloak, qui propose un navigateur cloud pour décharger la consommation de ressources, les opérations de Multilogin dépendent généralement des ressources locales du système, ce qui peut être un facteur important lors de l’exécution de centaines de profils.
Avantages :
- Masquage d’empreintes digitales très puissant avec contrôle granulaire
- Prend en charge plusieurs moteurs de navigation (Chromium, Firefox)
- Stabilité éprouvée pour le grattage à grande échelle
- Automatisation solide et support API
Inconvénients :
- Chère comparée à la plupart des concurrents
- Courbe d’apprentissage plus abrupte pour les nouveaux utilisateurs
- Utilisation plus importante des ressources locales à grande échelle
Cas d’usage idéaux :
- Opérations de scraping au niveau de l’entreprise
- Équipes qui collectent des cibles à haute sécurité ou à forte valeur
- Utilisateurs ayant besoin d’une personnalisation manuelle approfondie de l’empreinte digitale
Octo Browser
Octo Browser est un choix populaire pour les tâches de scraping de taille moyenne, occupant un juste milieu entre solutions d’entrée de gamme et solutions d’entreprise. Il offre une usurpation fiable des empreintes digitales sans submerger les utilisateurs avec des paramètres complexes. Octo Browser offre un accès API et prend en charge les flux de travail d’automatisation courants, offrant des performances stables avec une utilisation modérée des ressources sur du matériel standard.
Avantages :
- Bonne qualité d’empreintes digitales pour la plupart des scénarios de scraping
- Prix raisonnables comparés aux outils d’entreprise
- Interface propre et gestion simple des profils
- Adapté à l’automatisation avec des frameworks courants
Inconvénients :
- Fonctionnalités d’automatisation moins avancées que les outils de haut niveau
- Peut avoir du mal face aux systèmes de détection les plus agressifs
Cas d’usage idéaux :
- Freelances et petites équipes
- Projets de scraping et d’extraction de données de taille moyenne
- Utilisateurs qui veulent des fonctionnalités solides sans prix pour les entreprises
AdsPower
AdsPower est principalement connu pour la gestion multi-comptes, mais il est également utilisé pour le scraping, surtout lorsque l’organisation des profils est une priorité. Il dispose d’une interface conviviale et prend en charge les techniques standard de masquage par empreintes digitales. Sa principale limitation pour le scraping est sa profondeur d’automatisation, qui n’est pas aussi flexible que les outils conçus spécifiquement pour l’extraction de données. Cela le rend plus adapté aux tâches de scraping plus légères ou semi-automatisées, comme l’automatisation du commerce électronique (Amazon/eBay).
Avantages :
- Interface facile à utiliser avec une gestion des profils solide
- Support large des proxy et intégrations avec les fournisseurs
- Tarifs abordables avec forfaits flexibles
Inconvénients :
- Les fonctionnalités d’automatisation sont plus limitées pour le scraping à grande échelle
- L’usurpation d’empreintes digitales est solide mais pas leader dans le secteur
Cas d’usage idéaux :
- Projets de scraping de petites à moyennes dimensions
- Utilisateurs combinant le scraping avec des flux de travail multi-comptes
- Les équipes privilégient l’ergonomie plutôt que l’automatisation profonde
Dauphin{Anty}
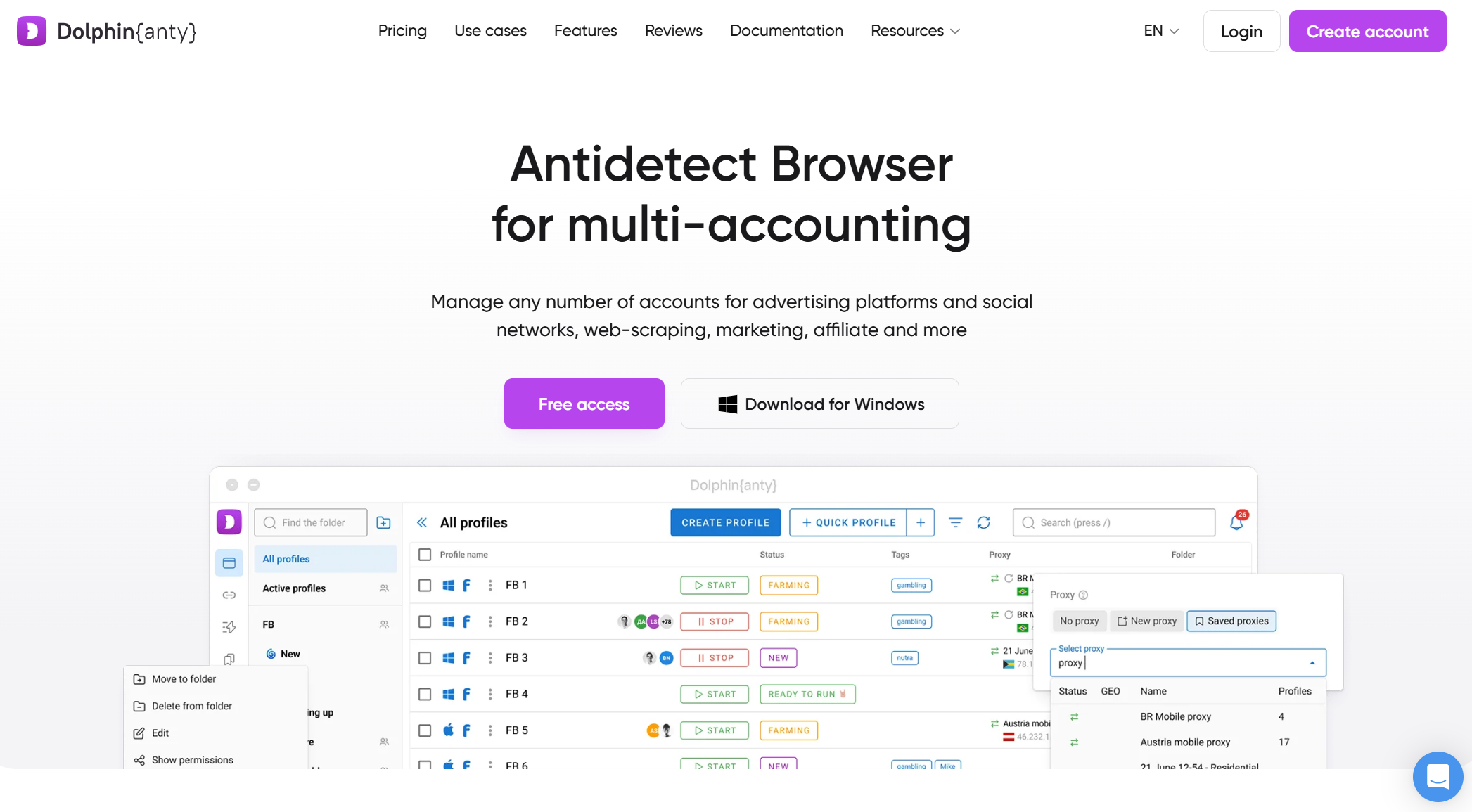
Dolphin{Anty} est un excellent choix pour les débutants ou les utilisateurs avec un budget serré. Il offre un généreux palier gratuit, un masquage basique des empreintes digitales et des performances légères, ce qui le rend accessible à l’expérimentation sur des machines moins puissantes. Cependant, son empreintes digitales est moins sophistiqué que les outils haut de gamme, et ses options d’automatisation sont limitées, ce qui le rend inadapté au scraping massif ou à grande échelle contre des systèmes de protection antibots avancés.
Avantages :
- Tarif gratuit généreux et entrée faible
- Configuration simple et performances légères
- Adapté à l’apprentissage et à l’expérimentation
Inconvénients :
- Capacités limitées d’automatisation et d’API
- Usurpation d’empreintes digitales moins faible comparée aux outils haut de gamme
- Pas idéal pour des cibles à haute sécurité
Cas d’usage idéaux :
- Débutants apprenant le web scraping
- Petits projets de scraping à faible risque
- Utilisateurs avec des restrictions budgétaires
Meilleures pratiques pour l’utilisation des navigateurs antidétection pour le web scraping
Un navigateur antidétection est le plus efficace lorsqu’il est utilisé dans le cadre d’une stratégie de scraping complète. Les bonnes pratiques suivantes sont essentielles pour obtenir des résultats fiables et durables.
- Associez-vous avec des proxys de haute qualité
Un navigateur antidétection masque votre appareil, mais un proxy est nécessaire pour masquer votre identité réseau. Chaque profil doit être associé à un proxy dédié et de haute qualité (résidentiel ou centre de données) afin d’éviter d’être signalé. Gérer soigneusement la rotation des IP par session est essentiel pour éviter de paraître artificiel.
- Utilisez des empreintes digitales uniques du navigateur
L’objectif principal d’un navigateur anti-détection est de garantir que chaque session paraît unique. Évitez de cloner des profils sans que le navigateur ne génère de nouvelles variations réalistes d’empreintes digitales. La réutilisation des mêmes éléments d’empreintes digitales sur différents profils crée un motif que les systèmes de détection peuvent facilement identifier.
- Cookies et sessions isolés
Assurez-vous que les cookies, le stockage local et les données mises en cache sont complètement séparés pour chaque profil. Cette isolation est cruciale pour empêcher les sites web de lier vos différentes identités de scraping, surtout lorsqu’on travaille avec des comptes connectés ou que plusieurs scrapers fonctionnent simultanément.
- Combiner avec des bibliothèques d’automatisation
Pour toute tâche au-delà de la navigation manuelle, intégrez votre navigateur antidétection avec des bibliothèques d’automatisation comme Puppeteer ou Selenium. Cela permet de gérer programmatiquement les profils, les proxys et la logique de scraping, ce qui augmente l’efficacité et réduit l’erreur humaine.
- Imiter un comportement humain
Même avec une empreinte digitale parfaite, un comportement de type bot peut vous faire bloquer. La logique de scraping doit être conçue pour paraître naturelle. Introduisez des délais aléatoires entre les clics, variez les mouvements de la souris, et évitez de naviguer sur un site web avec exactement le même chemin à chaque fois.
Pièges courants lors de l’utilisation des navigateurs antidétection pour le web scraping
Même les meilleurs réglages peuvent échouer si vous ne connaissez pas les pièges courants. Voici plusieurs problèmes à surveiller.
- Comportement inhabituel du réseau
Envoyer trop de requêtes en peu de temps, toucher à plusieurs reprises les mêmes points de terminaison, ou utiliser un timing prévisible peut déclencher des systèmes de détection, quelle que soit la qualité de votre empreinte. Cela entraîne souvent des CAPTCHAs ou des blocages temporaires.
- Navigateurs de faible qualité ou gratuits
Les navigateurs anti-détection gratuits ou très bon marché peuvent utiliser des modèles d’empreintes digitales recyclés ou limités. Avec le temps, les systèmes de détection apprennent à reconnaître ces empreintes digitales courantes, ce qui fait qu’une configuration qui fonctionnait auparavant commence à échouer.
- Dépendance excessive au seul navigateur
Considérer un navigateur antidétection comme une solution autonome est une erreur. Une empreinte impeccable est inutile si elle est diffusée depuis une IP signalée ou présente un comportement robotique. Une approche holistique qui intègre les meilleures pratiques de gestion par procuration et un timing humain est non négociable.
- Considérations éthiques et juridiques
La capacité technique ne prévaut pas sur les conditions d’utilisation d’un site web ni sur les lois locales. Avant de scraper, comprenez quelles données vous collectez, comment elles seront utilisées et si des règles ou réglementations légales de la plateforme s’appliquent.
Comment choisir les bons navigateurs antidétection pour le web scraping
Choisir le bon navigateur consiste à adapter un outil à votre flux de travail spécifique. Utilisez cette liste de contrôle pour guider votre décision.
- Commencez par votre balance
Un petit projet ponctuel a des besoins très différents d’un système de collecte de données continu et à grande échelle. Pour des tâches limitées ou des expériences initiales, un outil comme Dolphin{Anty} avec son généreux niveau gratuit est un point de départ pratique. Pour un scraping continu et à grande échelle où la stabilité et l’automatisation sont primordiales, vous devriez évaluer des options comme DICloak ou Multilogin.
- Réfléchissez à votre budget
Évaluez le coût en termes de fiabilité et de temps gagné, pas seulement en abonnement mensuel. Les blocages fréquents et les performances instables peuvent coûter bien plus en données perdues et en temps de développement qu’un outil plus coûteux mais fiable.
- Adaptez les fonctionnalités à votre flux de travail
Identifiez vos caractéristiques indispensables avant de commencer à chercher. Avez-vous besoin d’une API robuste, d’une exécution cloud ou de fonctionnalités de collaboration en équipe ? Choisissez un navigateur qui excelle dans ce dont vous avez besoin et évitez de payer pour des fonctionnalités que vous n’utiliserez pas.
- Évaluez votre profil technique
Les développeurs apprécieront les API robustes et les capacités d’automatisation pour une intégration fluide, tandis que les équipes privilégiant la facilité d’utilisation plutôt que l’automatisation profonde pourraient trouver d’autres solutions plus adaptées. De plus, prenez en compte la compatibilité des plateformes et demandez si l’émulation mobile est une exigence clé pour vos besoins en scraping.
- Regardez au-delà des fonctionnalités pour la stabilité et la réputation
Un bon navigateur antidétection doit être mis à jour régulièrement pour suivre les nouvelles méthodes de détection. Vérifiez les retours de la communauté, la qualité de la documentation et la fréquence des mises à jour pour évaluer la fiabilité à long terme d’un outil. La stabilité est souvent plus précieuse qu’une longue liste de fonctionnalités.
Conclusion : Recommandations finales pour les navigateurs antidétection pour le web scraping
Les navigateurs antidétection pour le web scraping sont devenus des outils essentiels pour toute opération sérieuse de web scraping en 2026. Parce que les sites web modernes utilisent des systèmes de détection en couches, les méthodes d’automatisation traditionnelles ne sont plus fiables. Il n’existe pas de navigateur unique « meilleur » pour tout le monde ; Le bon choix dépend entièrement de l’ampleur, du budget et des besoins techniques de votre projet. En définissant clairement votre cas d’usage, vous pouvez choisir un outil qui améliore la fiabilité et la longévité de vos opérations de scraping .
Quelques recommandations rapides :
- Pour débutants ou petits projets : DICloak ou Dolphin Anty offrent des points d’entrée accessibles grâce à leurs patiers gratuits efficaces.
- Flux de travail professionnels de scraping : DICloak offre un fort équilibre entre fiabilité, automatisation et évolutivité lorsqu’il est associé à des proxys de haute qualité.
- Extraction à grande échelle ou entreprise : Multilogin convient parfaitement aux environnements complexes nécessitant un contrôle profond et une stabilité des empreintes digitales, bien que cela ait un coût plus élevé.
Foire aux questions sur les navigateurs antidétection pour le web scraping
Quelle est la différence entre les navigateurs antidétection pour le web scraping et un navigateur headless standard ?
Un navigateur sans interface standard expose souvent des signaux d’empreintes digitales par défaut ou incomplets qui sont facilement détectés comme automatisations. Les navigateurs antidétection pour le web scraping sont spécifiquement conçus pour créer et gérer des empreintes digitales uniques et réalistes afin d’apparaître comme un utilisateur humain normal, garantissant ainsi que vos opérations de web scraping sont indétectables.
Puis-je utiliser un navigateur antidétection gratuit pour un projet sérieux de scraping ?
Bien qu’excellents pour l’apprentissage, la plupart des niveaux gratuits sont risqués pour des projets sérieux en raison des limitations de qualité et d’automatisation des empreintes digitales. Ils s’appuient souvent sur des modèles d’empreintes digitales recyclés, qui sont plus susceptibles d’être reconnus et bloqués avec le temps, comme mentionné dans les pièges courants des navigateurs antidétection pour le web scraping.
Dois-je toujours me soucier des CAPTCHA lorsque j’utilise des navigateurs antidétection pour le web scraping ?
Oui. Un navigateur antidétection pour le web scraping réduit considérablement le risque de rencontrer des CAPTCHA en masquant votre empreinte digitale, mais il ne peut pas les prévenir entièrement. Des comportements non naturels, tels que des taux de requêtes très élevés, peuvent tout de même déclencher des problèmes CAPTCHA, même lorsqu’on utilise des navigateurs antidétection pour le web scraping.
Est-il possible qu’un site web détecte des navigateurs antidétection pour le web scraping ?
Oui, c’est un jeu du chat et de la souris en cours. À mesure que les sites web développent de nouvelles techniques de détection, les navigateurs anti-détection pour les développeurs de web scraping doivent mettre à jour leurs logiciels pour les contrer. C’est pourquoi choisir un navigateur avec des mises à jour régulières et une solide réputation est crucial pour réussir à long terme dans le web scraping.
Combien de profils puis-je lancer simultanément avec des navigateurs antidétection pour le web scraping ?
Le nombre de profils que vous pouvez exécuter simultanément dépend du matériel de votre ordinateur (CPU et RAM) et de l’efficacité des navigateurs antidétection pour le web scraping eux-mêmes. Certains navigateurs sont plus légers que d’autres, il est donc important de tester les performances en fonction de votre configuration spécifique et des exigences de votre exploitation de web scraping.
 Outils gratuits
Outils gratuits Extension de cookie
Extension de cookie Générateur UA
Générateur UA Générateur d'adresse MAC
Générateur d'adresse MAC Générateur d'IP
Générateur d'IP Liste des adresses IP
Liste des adresses IP Générateur de code 2FA
Générateur de code 2FA Horloge mondiale
Horloge mondiale Vérification Anonyme
Vérification Anonyme WebRTC Leak Test
WebRTC Leak Test Générateur UUID
Générateur UUID Vérificateur de proxy
Vérificateur de proxy Vérificateur d'annonces FB
Vérificateur d'annonces FB Extraction de données web par IA
Extraction de données web par IA Outils SMM gratuits
Outils SMM gratuits Vérificateur d'ombre bannissement Twitter
Vérificateur d'ombre bannissement Twitter Générateur UTM
Générateur UTM Générateur de noms d'utilisateur
Générateur de noms d'utilisateur Generateur de hashtags IA
Generateur de hashtags IA Générateur de titre LinkedIn
Générateur de titre LinkedIn Redimensionneur d’images sociales
Redimensionneur d’images sociales







