Quét web là một công cụ mạnh mẽ để thu thập dữ liệu từ các trang web. Tuy nhiên, nhiều trang web sử dụng các dịch vụ bảo mật như Cloudflare để bảo vệ nội dung của họ. Vì vậy, làm thế nào để bạn bỏ qua Cloudflare khi cố gắng cạo dữ liệu? Cloudflare có thể chặn các nỗ lực quét bằng cách phát hiện hoạt động đáng ngờ. Điều này tạo ra một thách thức lớn cho bất kỳ ai muốn thu thập dữ liệu từ các trang web này. Để vượt qua Cloudflare, bạn cần các phương pháp hiệu quả cho phép bạn truy cập dữ liệu bạn muốn mà không bị chặn. Tại sao bỏ qua Cloudflare lại quan trọng để quét web thành công? Nếu không bỏ qua nó, nỗ lực cạo của bạn có thể bị dừng lại, lãng phí thời gian và tài nguyên. Chìa khóa để thu thập dữ liệu hiệu quả là biết cách vượt qua bảo vệ Cloudflare. Trong bài viết này, chúng tôi sẽ chỉ cho bạn các phương pháp bạn có thể sử dụng để vượt qua Cloudflare và quét dữ liệu thành công.
Quản lý bot Cloudflare là gì?
Đám mâyĐóng một vai trò quan trọng trong việc bảo vệ các trang web khỏi các mối đe dọa trực tuyến khác nhau, chẳng hạn như tấn công và bot. Ví dụ: khi bạn truy cập một trang web như cửa hàng trực tuyến, Cloudflare có thể làm việc đằng sau hậu trường để đảm bảo rằng chỉ những người dùng thực chứ không phải bot, mới truy cập trang web.
Nhưng khi nói đến quét web, Cloudflare có thể trở thành một vấn đề. Các trang web thường sử dụng Cloudflare Bot Management để phát hiện và chặn các công cụ tự động thu thập dữ liệu. Điều này được thực hiện bằng cách phân tích hành vi của khách truy cập, kiểm tra địa chỉ IP và xác định các mẫu đáng ngờ. Ví dụ: nếu bot cố gắng thu thập dữ liệu từ một trang web quá nhanh hoặc quá thường xuyên, Cloudflare có thể chặn địa chỉ IP hoặc thách thức bot bằng CAPTCHA.
Vì vậy, làm thế nào để bạn bỏ qua Cloudflare trong những trường hợp như vậy? Khi bạn đang thực hiện quét web, điều này có thể ngăn bạn truy cập dữ liệu bạn cần. Việc bỏ qua Cloudflare trở nên quan trọng vì nếu không có nó, bạn có thể gặp phải các khối và chậm trễ, ảnh hưởng đến hiệu quả của việc cạo của bạn. Mục tiêu của Cloudflare Bot Management là ngăn chặn các nỗ lực cạo tự động này, nhưng nếu bạn biết các kỹ thuật phù hợp, bạn vẫn có thể bỏ qua Cloudflare và tiếp tục cạo dữ liệu bạn cần.
Cloudflare phát hiện bot như thế nào?
Để bảo vệ các trang web khỏi việc quét web, Cloudflare sử dụng cả kỹ thuật thụ động và chủ động để phát hiện bot. Những kỹ thuật này giúp Cloudflare phân tích khách truy cập và tách con người khỏi bot tự động. Chúng ta hãy xem xét kỹ hơn cách Cloudflare phát hiện các bot đáng ngờ và điều này ảnh hưởng như thế nào đến khả năng vượt qua Cloudflare để quét web.
Kỹ thuật phát hiện thụ động
Cloudflare sử dụng các phương pháp nhưDấu vân tay TLSvàLấy dấu vân tay IPđể xác định bot. Ví dụ: khi bot cố gắng truy cập một trang web, nó thường sử dụng dấu vân tay TLS (Transport Layer Security) khác với trình duyệt thông thường. Cloudflare có thể theo dõi điều này và gắn cờ nó là đáng ngờ. Tương tựLấy dấu vân tay IPxem xét nguồn gốc của yêu cầu. Nếu một bot đang quét nhiều trang web từ cùng một địa chỉ IP trong một thời gian ngắn, nó sẽ đưa ra dấu hiệu đỏ. Một phương pháp phổ biến khác liên quan đến việc kiểm traTiêu đề HTTP. Nếu các tiêu đề có vẻ không nhất quán hoặc thiếu thông tin quan trọng, Cloudflare có thể phát hiện ra rằng yêu cầu đến từ bot.
Kỹ thuật phát hiện chủ động
Cloudflare cũng sử dụngThách thức JavaScriptđể xác minh rằng khách truy cập là con người. Ví dụ: Cloudflare có thể yêu cầu người dùng giải quyết một thử thách JavaScript nhỏ trước khi truy cập một trang web. Thử thách này rất khó để bot vượt qua, nhưng dễ dàng đối với con người. Ngoài raPhân tích hành vitheo dõi cách người dùng tương tác với trang web. Nếu chuyển động hoặc kiểu nhấp chuột có vẻ như robot — chẳng hạn như đưa ra yêu cầu quá nhanh — Cloudflare sẽ gắn cờ nó. Kỹ thuật hoạt động phổ biến nhất làCAPTCHAthách thức. Cloudflare có thể hiển thị CAPTCHA để xác nhận rằng khách truy cập là con người chứ không phải bot thu thập dữ liệu.
Đối với bất kỳ ai đang cố gắng vượt qua Cloudflare, hiểu các phương pháp phát hiện này là chìa khóa. Để tiếp tục quét web mà không bị gián đoạn, bạn cần biết cách tránh kích hoạt các biện pháp bảo mật thụ động và chủ động này. Bằng cách điều chỉnh các kỹ thuật quét của bạn, chẳng hạn như xoay IP, sử dụng tiêu đề HTTP thích hợp hoặc giải quyết các thách thức JavaScript, bạn có thể bỏ qua Cloudflare và có quyền truy cập vào dữ liệu bạn cần.
Các phương pháp để vượt qua bảo vệ Cloudflare
Bây giờ chúng ta đã hiểu cách Cloudflare phát hiện bot, hãy cùng khám phá các phương pháp hiệu quả đểbỏ qua Cloudflarebảo vệ và thu thập dữ liệu hiệu quả.
1. Sử dụng Cloudflare Solvers
Một cách phổ biến để vượt qua bảo mật của Cloudflare là sử dụng chuyên dụngTrình giải CloudflarenhưFlareSolverr. Các công cụ này được thiết kế để xử lý các thách thức như kiểm tra JavaScript vàCAPTCHAkiểm tra tự động. Ví dụ: FlareSolverr có thể tương tác với các thách thức JavaScript của Cloudflare và giải quyết chúng mà không yêu cầu đầu vào của con người. Điều này cho phép trình quét web của bạn tiếp tục hoạt động mà không bị gián đoạn, ngay cả khi Cloudflare yêu cầu CAPTCHA hoặc thử thách JavaScript. Sử dụng các trình giải này đảm bảo rằng các nỗ lực quét của bạn sẽ vượt qua các lớp bảo vệ của Cloudflare.
 2. Địa chỉ IP xoay vòng
2. Địa chỉ IP xoay vòng
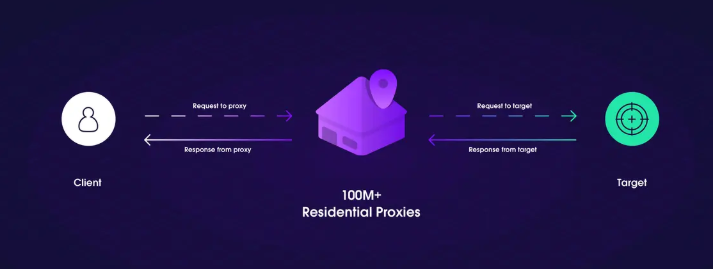
Một phương pháp quan trọng khác để vượt qua Cloudflare là xoayĐịa chỉ IP. Cloudflare thường phát hiện các nỗ lực quét lặp đi lặp lại từ cùng một IP và có thể chặn hoặc giới hạn tốc độ các yêu cầu đó. Bằng cách xoay vòng IP, bạn có thể tránh bị phát hiện và vượt qua các khối dựa trên IP của Cloudflare. Sử dụng nhóm proxy hoặcproxy dân cưlà một cách tuyệt vời để đảm bảo trình quét của bạn đang sử dụng một số lượng lớn các địa chỉ IP đa dạng. Ví dụ: proxy dân cư giúp mô phỏng lưu lượng truy cập người dùng thực, khiến Cloudflare khó xác định yêu cầu là quét tự động.
 (nguồn:Phòng thí nghiệm oxy)
(nguồn:Phòng thí nghiệm oxy)
3. Mô phỏng hành vi giống con người
Để giảm hơn nữa việc phát hiện, mô phỏngHành vi giống con ngườilà điều cần thiết. Điều này có thể được thực hiện bằng cách sử dụngTrình duyệt không đầuvới các tính năng chống phát hiện, chẳng hạn nhưMúa rốihoặcNhà soạn kịch. Những công cụ này cho phép bạn điều khiển trình duyệt theo chương trình và bắt chước các hành động của con người như cuộn, nhấp và nhập. Ngoài ra, kết hợp các công cụ này vớiPlugin chống phát hiệnnhưpuppeteer-extra-plugin-tàng hìnhcó thể giúp vượt qua phân tích hành vi của Cloudflare, tìm kiếm các mẫu robot trong tương tác của người dùng. Phương pháp này có hiệu quả cao để bỏ qua cả kỹ thuật phát hiện thụ động và chủ động.
 (nguồn:Shanika Wickramasinghe)
(nguồn:Shanika Wickramasinghe)
4. Sử dụng trình duyệt chống phát hiện
Để có kết quả tốt hơn nữa, hãy sử dụng các trình duyệt chống phát hiện nhưDICloakcó thể là một yếu tố thay đổi cuộc chơi. Các trình duyệt này được thiết kế để mô phỏng hoạt động thực của người dùng bằng cách che dấu vân tay kỹ thuật số của bạn. Bằng cách bắt chước hành vi của người dùng hợp pháp, trình duyệt chống phát hiện có thể tránh phổ biếnThách thứcvàPhân tích hành vicác kỹ thuật được sử dụng bởi Cloudflare. Điều này cho phép các nỗ lực quét web của bạn không bị phát hiện và hiệu quả hơn. Ngoài việc che dấu vân tay, DICloak còn cung cấpRPA (Tự động hóa quy trình bằng robot)các tính năng, cho phép công cụ quét của bạn tự động hóa các tác vụ và tương tác với các trang web như người dùng thực. Điều này làm cho việc cạo năng động và dễ thích ứng hơn, giảm hơn nữa nguy cơ bị Cloudflare phát hiện.
5. API quét web
Một cách hiệu quả đểbỏ qua Cloudflarebảo vệ bằng cách sử dụngAPI quét web. Các API này được thiết kế để xử lý sự phức tạp của bảo mật Cloudflare cho bạn. Chẳng hạnAPI cạphoặcZytecó thể quản lý xoay vòng IP, bỏ qua CAPTCHA và xử lý các thử thách JavaScript một cách tự động. Thay vì xử lý các chi tiết kỹ thuật, bạn có thể chỉ cần gửi yêu cầu đến API và nhận dữ liệu bạn cần, trong khi API sẽ bỏ qua Cloudflare cho bạn. Phương pháp này tiết kiệm thời gian và đảm bảo cạo mượt mà hơn.
Mã ví dụ (ScraperAPI):
import requests
# Using ScraperAPI to request a webpage
url = "https://example.com"
api_key = "your_scraperapi_key"
response = requests.get(f"http://api.scraperapi.com?api_key={api_key}&url={url}")
# Get the response content
print(response.text)
6.Bỏ qua Cloudflare CDN bằng cách gọi máy chủ gốc
Một phương pháp khác đểbỏ qua Cloudflarelà gọiMáy chủ gốctrực tiếp. Cloudflare hoạt động như một proxy, vì vậy việc truy cập trang web thông qua CDN của Cloudflare có thể gây ra các thách thức bảo mật. Tuy nhiên, bằng cách xác định và truy cập trực tiếp vào máy chủ gốc (tức là máy chủ lưu trữ nội dung thực tế của trang web), bạn có thể bỏ qua các biện pháp bảo vệ của Cloudflare.
Để làm điều này, bạn có thể cần khám pháĐịa chỉ IP của máy chủ gốc, đôi khi có thể được tìm thấy thông qua rò rỉ DNS hoặc các bản ghi trước đó. Khi bạn có IP của máy chủ gốc, bạn có thể thực hiện yêu cầu trực tiếp đến nó, tránh lớp CDN của Cloudflare.
Mã ví dụ (Nhận IP máy chủ gốc):
import socket
# Get the IP address of the target domain (sometimes the origin server's IP)
hostname = "example.com"
ip_address = socket.gethostbyname(hostname)
print("Origin Server IP:", ip_address)
7. Bỏ qua phòng chờ Cloudflare và thiết kế ngược thách thức của nó
Cloudflare có một tính năng gọi làphòng chờ, thường thấy trong các sự kiện lưu lượng truy cập cao. Tính năng này có thể trì hoãn người dùng và thách thức họ với các tác vụ như CAPTCHA. Đếnbỏ qua phòng chờ của Cloudflare, bạn cần thiết kế ngược cách thức hoạt động của nó.
Một phương pháp là phân tích các yêu cầu được đưa ra khi vào phòng chờ, nghiên cứu cách thử thách được kích hoạt và tự động hóa tương tác với nó. Các công cụ nhưFiddlerhoặcSuite ợ hơicó thể giúp kiểm tra lưu lượng mạng và tiết lộ cách thức hoạt động của thách thức của Cloudflare. Khi bạn thiết kế ngược thử thách, bạn có thể tự động hóa nó để tránh chờ đợi trang tải.
Mã ví dụ (Tự động tương tác với Selenium):
from selenium import webdriver
from selenium.webdriver.common.by import By
# Using Selenium to load the page and wait for the challenge
driver = webdriver.Chrome(executable_path="path_to_chromedriver")
# Visit the target site
driver.get("https://example.com")
# Wait for and handle Cloudflare's JavaScript challenge
driver.implicitly_wait(10) # Wait for the page to load
driver.find_element(By.CSS_SELECTOR, "button#submit").click() # Automatically click the submit button (if any)
# Get the page content
page_content = driver.page_source
print(page_content)
# Close the browser
driver.quit()
8. Bỏ qua Cloudflare CAPTCHA
Một vấn đề thường gặp khi cạoĐược bảo vệ bởi Cloudflarecác trang web đang gặp phảiCAPTCHAThách thức. Để vượt qua Cloudflare CAPTCHA, bạn có thể sử dụng các dịch vụ giải CAPTCHA như2CaptchahoặcAntiCaptcha, sử dụng con người thực hoặc AI để giải CAPTCHA cho bạn. Các dịch vụ này có thể tích hợp với trình quét của bạn và tự động bỏ qua lời nhắc CAPTCHA, cho phép các nỗ lực quét của bạn tiếp tục suôn sẻ.
Tuy nhiên, để phương pháp này hoạt động liền mạch, bạn nên kết hợp nó vớiKỹ thuật chống phát hiệnnhư xoay IP và sử dụng các công cụ tự động hóa trình duyệt nhưMúa rốiđể giữ cho hoạt động của bạn giống như con người.
Mã ví dụ (sử dụng 2Captcha để giải CAPTCHA):
import requests
# 2Captcha API key
api_key = "your_2captcha_api_key"
site_key = "site_key_of_the_target_page"
url = "https://example.com/captcha_page"
# Request CAPTCHA challenge
captcha_response = requests.post("http://2captcha.com/in.php", data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': url,
}).json()
captcha_id = captcha_response['request']
# Get the solved CAPTCHA result
captcha_result = requests.get(f"http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}").json()
# CAPTCHA solution
captcha_solution = captcha_result['request']
# Submit the solution to the target page
response = requests.get(f"{url}?g-recaptcha-response={captcha_solution}")
print(response.text)
9. Cạo bộ nhớ cache của Google
Nếu một trang web được Cloudflare bảo vệ nghiêm ngặt, đôi khi bạn có thể vượt qua bảo mật của nó bằng cách cạo bộ nhớ cache của Google. Google thường lưu trữ các phiên bản của các trang web có thể được truy cập mà không gây ra các thách thức của Cloudflare.
Bằng cách tìm kiếm URL trongGooglevà nhấp vào liên kết được lưu trong bộ nhớ đệm, bạn có thể cạo nội dung từ phiên bản được lưu trong bộ nhớ cache thay vì trang web trực tiếp. Phương pháp này không phải lúc nào cũng hiệu quả nếu bộ nhớ cache đã lỗi thời, nhưng đây là một giải pháp hữu ích khi xử lý các trang web có **bảo vệ Cloudflare mạnh mẽ**.
Mã ví dụ (Truy cập bộ nhớ cache của Google):
import requests
# Get Google cache URL
url = "https://www.example.com"
cache_url = f"http://webcache.googleusercontent.com/search?q=cache:{url}"
# Request the cached page
response = requests.get(cache_url)
# Get the cached page content
print(response.text)
Kết thúc
Bỏ qua thành côngBảo vệ Cloudflarelà điều cần thiết để hiệu quảquét web. Bằng cách sử dụng các phương pháp nhưAPI cạo, xoay địa chỉ IP, giải quyếtCAPTCHA, mô phỏng hành vi giống con người và các thách thức kỹ thuật đảo ngược nhưPhòng chờ, bạn có thể vượt qua các rào cản mà Cloudflare đặt ra. Mỗi kỹ thuật cung cấp một giải pháp cho các khía cạnh khác nhau của các biện pháp bảo mật của Cloudflare, cho phép bạn thu thập dữ liệu một cách trơn tru mà không bị chặn. Tuy nhiên, hãy luôn đảm bảo rằng các hoạt động cạo của bạn có đạo đức và tuân thủ các quy định của pháp luật có liên quan.
 Công cụ miễn phí
Công cụ miễn phí Cookie Cắm -in
Cookie Cắm -in Trình tạo UA
Trình tạo UA Trình tạo địa chỉ MAC
Trình tạo địa chỉ MAC Trình tạo địa chỉ IP
Trình tạo địa chỉ IP Danh Sách Địa Chỉ IP
Danh Sách Địa Chỉ IP Trình tạo mã 2FA
Trình tạo mã 2FA Đồng Hồ Thế Giới
Đồng Hồ Thế Giới Kiểm tra ẩn danh
Kiểm tra ẩn danh WebRTC Leak Test
WebRTC Leak Test Trình tạo UUID
Trình tạo UUID Trình kiểm tra Proxy
Trình kiểm tra Proxy Kiểm tra FB Ads
Kiểm tra FB Ads Quét web bằng AI
Quét web bằng AI Công Cụ SMM Miễn Phí
Công Cụ SMM Miễn Phí Công Kiểm Tra Shadowban Twitter
Công Kiểm Tra Shadowban Twitter Công cụ Kiểm tra Tên Instagram
Công cụ Kiểm tra Tên Instagram Trình tạo UTM
Trình tạo UTM Trình tạo username
Trình tạo username Trinh tao hashtag AI
Trinh tao hashtag AI Trình tạo tiêu đề LinkedIn
Trình tạo tiêu đề LinkedIn Đổi kích thước ảnh mạng xã hội
Đổi kích thước ảnh mạng xã hội







