A raspagem da Web é uma ferramenta poderosa para coletar dados de sites. No entanto, muitos sites usam serviços de segurança como o Cloudflare para proteger seu conteúdo. Então, como você ignora o Cloudflare ao tentar coletar dados? A Cloudflare pode bloquear tentativas de raspagem detectando atividades suspeitas. Isso cria um grande desafio para quem deseja coletar dados desses sites. Para contornar o Cloudflare, você precisa de métodos eficazes que permitam acessar os dados desejados sem ser bloqueado. Por que ignorar o Cloudflare é tão importante para uma raspagem da web bem-sucedida? Sem ignorá-lo, suas tentativas de raspagem podem ser interrompidas, desperdiçando tempo e recursos. A chave para extrair dados com eficiência é saber como contornar a proteção do Cloudflare. Neste artigo, mostraremos os métodos que você pode usar para contornar o Cloudflare e coletar dados com sucesso.
O que é o Cloudflare Bot Management?
Cloudflaredesempenha um papel crucial na proteção de sites contra várias ameaças online, como ataques e bots. Por exemplo, quando você visita um site como uma loja online, a Cloudflare pode estar trabalhando nos bastidores para garantir que apenas usuários reais, não bots, acessem o site.
Mas quando se trata de web scraping, o Cloudflare pode se tornar um problema. Os sites costumam usar o Cloudflare Bot Management para detectar e bloquear ferramentas automatizadas que coletam dados. Isso é feito analisando o comportamento do visitante, verificando endereços IP e identificando padrões suspeitos. Por exemplo, se um bot tentar extrair dados de um site com muita rapidez ou frequência, a Cloudflare pode bloquear o endereço IP ou desafiar o bot com um CAPTCHA.
Então, como você ignora o Cloudflare nesses casos? Quando você está fazendo web scraping, isso pode impedir que você acesse os dados de que precisa. Ignorar o Cloudflare torna-se importante porque, sem ele, você pode enfrentar bloqueios e atrasos, afetando a eficiência de sua raspagem. O objetivo do Cloudflare Bot Management é interromper essas tentativas automatizadas de raspagem, mas se você souber as técnicas certas, ainda poderá ignorar o Cloudflare e continuar coletando os dados necessários.
Como a Cloudflare detecta bots?
Para proteger sites contra web scraping, a Cloudflare usa técnicas passivas e ativas para detectar bots. Essas técnicas ajudam a Cloudflare a analisar os visitantes e separar os humanos dos bots automatizados. Vamos dar uma olhada em como a Cloudflare detecta bots suspeitos e como isso afeta sua capacidade de contornar a Cloudflare para web scraping.
Técnicas de detecção passiva
Cloudflare usa métodos comoImpressão digital TLSeImpressão digital IPpara identificar bots. Por exemplo, quando um bot tenta acessar um site, ele geralmente usa uma impressão digital TLS (Transport Layer Security) diferente de um navegador comum. A Cloudflare pode rastrear isso e sinalizá-lo como suspeito. SimilarmenteImpressão digital IPAnalisa a origem da solicitação. Se um bot estiver extraindo vários sites do mesmo endereço IP em um curto espaço de tempo, ele levantará bandeiras vermelhas. Outro método comum envolve a verificaçãoCabeçalhos HTTP. Se os cabeçalhos parecerem inconsistentes ou faltarem informações cruciais, a Cloudflare pode detectar que a solicitação está vindo de um bot.
Técnicas de detecção ativa
A Cloudflare também usaDesafios do JavaScriptpara verificar se um visitante é humano. Por exemplo, o Cloudflare pode exigir que um usuário resolva um pequeno desafio de JavaScript antes de acessar um site. Esse desafio é difícil para os bots passarem, mas fácil para os humanos. AdicionalmenteAnálise do comportamentomonitora a maneira como os usuários interagem com o site. Se o padrão de movimento ou clique parecer robótico, como fazer solicitações muito rapidamente, a Cloudflare o sinalizará. A técnica ativa mais comum é aCAPTCHAdesafio. A Cloudflare pode exibir um CAPTCHA para confirmar que o visitante é um humano e não um bot que está coletando dados.
Para quem está tentando contornar o Cloudflare, entender esses métodos de detecção é fundamental. Para continuar a raspagem da web sem interrupção, você precisa saber como evitar o acionamento dessas medidas de segurança passivas e ativas. Ao adaptar suas técnicas de raspagem, como rotação de IPs, uso de cabeçalhos HTTP adequados ou resolução de desafios de JavaScript, você pode ignorar o Cloudflare e obter acesso aos dados de que precisa.
Métodos para ignorar a proteção do Cloudflare
Agora que entendemos como a Cloudflare detecta bots, vamos explorar métodos eficazes paraignorar Cloudflareproteção e raspagem de dados com eficiência.
1. Usando solucionadores Cloudflare
Uma maneira popular de contornar a segurança da Cloudflare é usandoSolucionadores CloudflaregostarSolverr de Flare. Essas ferramentas são projetadas para lidar com desafios como verificações de JavaScript eCAPTCHAtestes automaticamente. Por exemplo, o FlareSolverr pode interagir com os desafios JavaScript da Cloudflare e resolvê-los sem exigir intervenção humana. Isso permite que seu web scraper continue funcionando sem interrupções, mesmo quando a Cloudflare pede um desafio CAPTCHA ou JavaScript. O uso desses solucionadores garante que suas tentativas de raspagem ignorem as camadas protetoras da Cloudflare.
 2. Endereços IP rotativos
2. Endereços IP rotativos
Outro método crucial para contornar o Cloudflare é girandoEndereços IP. A Cloudflare geralmente detecta tentativas repetidas de raspagem do mesmo IP e pode bloquear ou limitar a taxa dessas solicitações. Ao alternar IPs, você pode evitar a detecção e contornar os bloqueios baseados em IP da Cloudflare. Usando pools de proxy ouProxies residenciaisé uma ótima maneira de garantir que seu raspador esteja usando um grande número de endereços IP diversos. Os proxies residenciais, por exemplo, ajudam a simular o tráfego real do usuário, tornando mais difícil para a Cloudflare identificar a solicitação como raspagem automatizada.
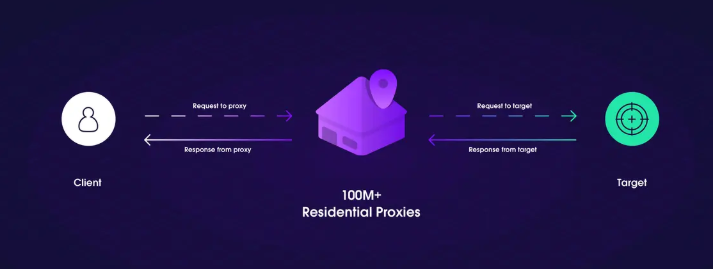 (fonte:oxylabs)
(fonte:oxylabs)
3. Simulando comportamento semelhante ao humano
Para reduzir ainda mais a detecção, simulandocomportamento semelhante ao humanoé essencial. Isso pode ser feito usandoNavegadores headlesscom recursos anti-detecção, comoTitereiroouDramaturgo. Essas ferramentas permitem que você controle um navegador programaticamente e imite ações humanas, como rolar, clicar e digitar. Além disso, combinar essas ferramentas comPlugins anti-detecçãogostarmarionetista-extra-plugin-discriçãopode ajudar a contornar a análise de comportamento da Cloudflare, que procura padrões robóticos na interação do usuário. Este método é altamente eficaz para contornar as técnicas de detecção passiva e ativa.
 (fonte:Shanika Wickramasinghe)
(fonte:Shanika Wickramasinghe)
4. Usando navegadores antidetecção
Para obter resultados ainda melhores, usando navegadores antidetecção comoDICloakpode ser um divisor de águas. Esses navegadores são projetados para simular a atividade real do usuário, mascarando sua impressão digital. Ao imitar o comportamento de um usuário legítimo, os navegadores antidetecção podem evitarDesafioseAnálise comportamentaltécnicas empregadas pela Cloudflare. Isso permite que seus esforços de raspagem da web permaneçam indetectáveis e mais eficientes. Além de mascarar impressões digitais, o DICloak também ofereceRPA (Automação Robótica de Processos)recursos, que permitem que seu raspador automatize tarefas e interaja com sites como um usuário real. Isso torna a raspagem mais dinâmica e adaptável, reduzindo ainda mais o risco de detecção pela Cloudflare.
5. API de raspagem da Web
Uma maneira eficiente deignorar Cloudflareproteção é usando umAPI de raspagem da web. Essas APIs são projetadas para lidar com a complexidade da segurança da Cloudflare para você. Por exemploAPI raspadoraouZytepode gerenciar a rotação de IP, ignorar CAPTCHA e lidar com desafios de JavaScript automaticamente. Em vez de lidar com os detalhes técnicos, você pode simplesmente enviar solicitações para a API e receber os dados de que precisa, enquanto ela se encarrega de contornar o Cloudflare para você. Este método economiza tempo e garante uma raspagem mais suave.
Código de exemplo (ScraperAPI):
import requests
# Using ScraperAPI to request a webpage
url = "https://example.com"
api_key = "your_scraperapi_key"
response = requests.get(f"http://api.scraperapi.com?api_key={api_key}&url={url}")
# Get the response content
print(response.text)
6. Ignore o Cloudflare CDN chamando o servidor de origem
Outro método paraignorar Cloudflareé chamar oServidor de origemdiretamente. A Cloudflare atua como um proxy, portanto, acessar o site por meio da CDN da Cloudflare pode desencadear desafios de segurança. No entanto, ao identificar e acessar o servidor de origem diretamente (ou seja, o servidor que hospeda o conteúdo real do site), você pode ignorar as proteções da Cloudflare.
Para fazer isso, talvez seja necessário descobrir oEndereço IP do servidor de origem, que às vezes pode ser encontrado por meio de vazamentos de DNS ou registros anteriores. Depois de ter o IP do servidor de origem, você pode fazer solicitações diretamente a ele, evitando a camada CDN da Cloudflare.
Código de exemplo (Obter IP do Servidor de Origem):
import socket
# Get the IP address of the target domain (sometimes the origin server's IP)
hostname = "example.com"
ip_address = socket.gethostbyname(hostname)
print("Origin Server IP:", ip_address)
7. Ignore a sala de espera da Cloudflare e faça engenharia reversa de seu desafio
A Cloudflare tem um recurso chamadosala de espera, frequentemente visto durante eventos de tráfego intenso. Esse recurso pode atrasar os usuários e desafiá-los com tarefas como CAPTCHA. Paraignorar a sala de espera da Cloudflare, você precisa fazer engenharia reversa de como funciona.
Um método é analisar as solicitações feitas ao entrar na sala de espera, estudando como o desafio é acionado e automatizando a interação com ele. Ferramentas comoRabequistaouSuíte Burppode ajudar a inspecionar o tráfego de rede e revelar como funciona o desafio da Cloudflare. Depois de fazer engenharia reversa do desafio, você pode automatizá-lo para evitar esperar o carregamento da página.
Código de exemplo (automatizando a interação com o Selenium):
from selenium import webdriver
from selenium.webdriver.common.by import By
# Using Selenium to load the page and wait for the challenge
driver = webdriver.Chrome(executable_path="path_to_chromedriver")
# Visit the target site
driver.get("https://example.com")
# Wait for and handle Cloudflare's JavaScript challenge
driver.implicitly_wait(10) # Wait for the page to load
driver.find_element(By.CSS_SELECTOR, "button#submit").click() # Automatically click the submit button (if any)
# Get the page content
page_content = driver.page_source
print(page_content)
# Close the browser
driver.quit()
8. Desvio de CAPTCHA da Cloudflare
Um problema comum ao rasparProtegido pela Cloudflaresites está encontrandoCAPTCHADesafios. Para ignorar o Cloudflare CAPTCHA, você pode usar serviços de resolução de CAPTCHA, como2CaptchaouAntiCaptcha, que usam humanos reais ou IA para resolver o CAPTCHA para você. Esses serviços podem se integrar ao seu raspador e ignorar automaticamente os prompts CAPTCHA, permitindo que seus esforços de raspagem continuem sem problemas.
No entanto, para que esse método funcione perfeitamente, você deve combiná-lo comtécnicas anti-detecçãocomo rotação de IPs e uso de ferramentas de automação de navegador, comoTitereiropara manter sua atividade humana.
Código de exemplo (usando 2Captcha para resolução de CAPTCHA):
import requests
# 2Captcha API key
api_key = "your_2captcha_api_key"
site_key = "site_key_of_the_target_page"
url = "https://example.com/captcha_page"
# Request CAPTCHA challenge
captcha_response = requests.post("http://2captcha.com/in.php", data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': url,
}).json()
captcha_id = captcha_response['request']
# Get the solved CAPTCHA result
captcha_result = requests.get(f"http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}").json()
# CAPTCHA solution
captcha_solution = captcha_result['request']
# Submit the solution to the target page
response = requests.get(f"{url}?g-recaptcha-response={captcha_solution}")
print(response.text)
9. Raspe o cache do Google
Se um site estiver fortemente protegido pela Cloudflare, às vezes você pode ignorar sua segurança raspando o cache do Google. O Google geralmente armazena em cache versões de páginas da web que podem ser acessadas sem acionar os desafios da Cloudflare.
Ao pesquisar o URL emPesquise no GoogleE clicando no link em cache, você pode extrair o conteúdo da versão em cache em vez do site ativo. Esse método nem sempre funciona se o cache estiver desatualizado, mas é uma solução alternativa útil ao lidar com sites que possuem forte proteção da Cloudflare.
Código de exemplo (acessando o Google Cache):
import requests
# Get Google cache URL
url = "https://www.example.com"
cache_url = f"http://webcache.googleusercontent.com/search?q=cache:{url}"
# Request the cached page
response = requests.get(cache_url)
# Get the cached page content
print(response.text)
Conclusão
Ignorando com sucessoProteção Cloudflareé essencial para umaraspagem da web. Usando métodos comoAPIs de raspagem, endereços IP rotativos, resolvendoCAPTCHAs, simulando comportamento semelhante ao humano e desafios de engenharia reversa comosalas de espera, você pode superar as barreiras que a Cloudflare implementa. Cada técnica fornece uma solução para diferentes aspectos das medidas de segurança da Cloudflare, permitindo que você raspe os dados sem problemas sem ser bloqueado. No entanto, sempre certifique-se de que suas atividades de raspagem sejam éticas e cumpram as leis relevantes.
 Ferramentas Gratuitas
Ferramentas Gratuitas Cookie Plugin
Cookie Plugin Gerador de UA
Gerador de UA Gerador de Endereço MAC
Gerador de Endereço MAC Gerador de Endereço IP
Gerador de Endereço IP Lista de Endereços IP
Lista de Endereços IP Gerador de Código 2FA
Gerador de Código 2FA Relógio Mundial
Relógio Mundial Verificação de Anonimato
Verificação de Anonimato WebRTC Leak Test
WebRTC Leak Test Gerador de UUID
Gerador de UUID Verificador de Proxy
Verificador de Proxy Verificador de Anúncios FB
Verificador de Anúncios FB Coleta Web com IA
Coleta Web com IA Ferramentas SMM Grátis
Ferramentas SMM Grátis Verificador de Shadowban do Twitter
Verificador de Shadowban do Twitter Verificador de Nomes do Instagram
Verificador de Nomes do Instagram Gerador UTM
Gerador UTM Gerador de nomes de usuário
Gerador de nomes de usuário Gerador de hashtags com IA
Gerador de hashtags com IA







