El raspado web es una herramienta poderosa para recopilar datos de sitios web. Sin embargo, muchos sitios web utilizan servicios de seguridad como Cloudflare para proteger su contenido. Entonces, ¿cómo se evita Cloudflare cuando se intenta raspar datos? Cloudflare puede bloquear los intentos de scraping detectando actividades sospechosas. Esto crea un gran desafío para cualquiera que busque recopilar datos de estos sitios. Para eludir Cloudflare, necesitas métodos eficaces que te permitan acceder a los datos que quieres sin ser bloqueado. ¿Por qué es tan importante eludir Cloudflare para tener éxito en el web scraping? Sin pasarlo por alto, sus intentos de raspado se pueden detener, perdiendo tiempo y recursos. La clave para extraer datos de manera eficiente es saber cómo eludir la protección de Cloudflare. En este artículo, te mostraremos los métodos que puedes utilizar para eludir Cloudflare y raspar los datos con éxito.
¿Qué es Cloudflare Bot Management?
Cloudflare desempeña un papel crucial en la protección de los sitios web de diversas amenazas en línea, como ataques y bots. Por ejemplo, cuando visitas un sitio web como una tienda en línea, Cloudflare podría estar trabajando en segundo plano para garantizar que solo los usuarios reales, no los bots, accedan al sitio.
Pero cuando se trata de web scraping, Cloudflare puede convertirse en un problema. Los sitios web suelen utilizar Cloudflare Bot Management para detectar y bloquear herramientas automatizadas que extraen datos. Esto se hace analizando el comportamiento de los visitantes, comprobando las direcciones IP e identificando patrones sospechosos. Por ejemplo, si un bot intenta extraer datos de un sitio web demasiado rápido o con demasiada frecuencia, Cloudflare puede bloquear la dirección IP o desafiar al bot con un CAPTCHA.
Entonces, ¿cómo se evita Cloudflare en estos casos? Cuando realizas web scraping, esto puede impedirte acceder a los datos que necesitas. Omitir Cloudflare se vuelve importante porque, sin él, podría enfrentar bloqueos y retrasos, lo que afectaría la eficiencia de su raspado. El objetivo de Cloudflare Bot Management es detener estos intentos de scraping automatizado, pero si conoces las técnicas adecuadas, aún puedes eludir Cloudflare y seguir extrayendo los datos que necesitas.
¿Cómo detecta Cloudflare los bots?
Para proteger los sitios web del web scraping, Cloudflare utiliza técnicas pasivas y activas para detectar bots. Estas técnicas ayudan a Cloudflare a analizar a los visitantes y a separar a los humanos de los bots automatizados. Echemos un vistazo más de cerca a cómo Cloudflare detecta bots sospechosos y cómo esto afecta su capacidad para eludir Cloudflare para el web scraping.
Técnicas de detección pasiva
Cloudflare utiliza métodos como la huella digital TLS y la huella digital IP para identificar bots. Por ejemplo, cuando un bot intenta acceder a un sitio web, a menudo utiliza una huella digital TLS (Transport Layer Security) diferente a la de un navegador normal. Cloudflare puede rastrear esto y marcarlo como sospechoso. Del mismo modo, la huella digital de IP examina el origen de la solicitud. Si un bot está extrayendo varios sitios web de la misma dirección IP en poco tiempo, genera señales de alerta. Otro método común consiste en comprobar los encabezados HTTP. Si los encabezados parecen incoherentes o les falta información crucial, Cloudflare puede detectar que la solicitud proviene de un bot.
Técnicas de detección activa
Cloudflare también utiliza desafíos de JavaScript para verificar que un visitante es humano. Por ejemplo, Cloudflare puede requerir que un usuario resuelva un pequeño desafío de JavaScript antes de acceder a un sitio. Este desafío es difícil de superar para los bots, pero fácil para los humanos. Además, el análisis de comportamiento monitorea la forma en que los usuarios interactúan con el sitio. Si el movimiento o el patrón de clic parecen robóticos, como hacer solicitudes demasiado rápido, Cloudflare lo marcará. La técnica activa más común es el desafío CAPTCHA . Cloudflare puede mostrar un CAPTCHA para confirmar que el visitante es un humano y no un bot que extrae datos.
Para cualquiera que intente eludir Cloudflare, comprender estos métodos de detección es clave. Para continuar con el web scraping sin interrupciones, debe saber cómo evitar activar estas medidas de seguridad pasivas y activas. Al adaptar tus técnicas de raspado, como rotar direcciones IP, usar encabezados HTTP adecuados o resolver desafíos de JavaScript, puedes eludir Cloudflare y obtener acceso a los datos que necesitas.
Métodos para eludir la protección de Cloudflare
Ahora que entendemos cómo Cloudflare detecta los bots, exploremos métodos efectivos para eludir la protección de Cloudflare y extraer datos de manera eficiente.
1.Uso de Cloudflare Solvers
Una forma popular de eludir la seguridad de Cloudflare es mediante el uso de solucionadores especializados de Cloudflare como FlareSolverr. Estas herramientas están diseñadas para manejar desafíos como verificaciones de JavaScript y pruebas de CAPTCHA automáticamente. Por ejemplo, FlareSolverr puede interactuar con los desafíos de JavaScript de Cloudflare y resolverlos sin necesidad de intervención humana. Esto permite que tu raspador web siga funcionando sin interrupciones, incluso cuando Cloudflare pide un CAPTCHA o un desafío de JavaScript. El uso de estos solucionadores garantiza que tus intentos de raspado eludan las capas protectoras de Cloudflare.
 2. Rotación de direcciones IP
2. Rotación de direcciones IP
Otro método crucial para eludir Cloudflare es rotar las direcciones IP. Cloudflare a menudo detecta intentos repetidos de raspado desde la misma IP y puede bloquear o limitar la velocidad de esas solicitudes. Al rotar las IP, puedes evitar la detección y eludir los bloqueos basados en IP de Cloudflare. El uso de grupos de proxy o proxies residenciales es una excelente manera de asegurarse de que su raspador esté utilizando una gran cantidad de direcciones IP diversas. Los proxies residenciales, por ejemplo, ayudan a simular el tráfico de usuarios reales, lo que dificulta que Cloudflare identifique la solicitud como raspado automatizado.
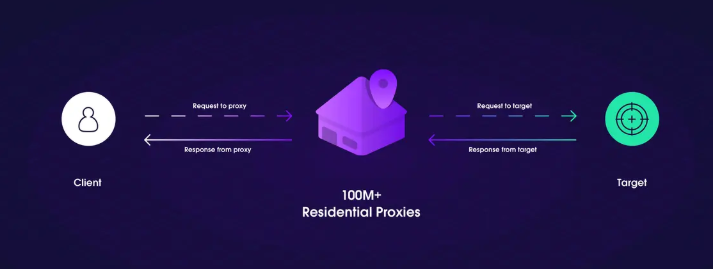 (fuente:oxylabs)
(fuente:oxylabs)
3. Simulación de un comportamiento similar al humano
Para reducir aún más la detección, es esencial simular un comportamiento similar al humano . Esto se puede hacer mediante el uso de navegadores sin cabeza con funciones antidetección, como Puppeteer o Playwright. Estas herramientas le permiten controlar un navegador mediante programación e imitar acciones humanas como desplazarse, hacer clic y escribir. Además, la combinación de estas herramientas con plugins antidetección como puppeteer-extra-plugin-stealth puede ayudar a eludir el análisis de comportamiento de Cloudflare, que busca patrones robóticos en la interacción del usuario. Este método es muy eficaz para eludir las técnicas de detección pasiva y activa.
 (fuente:Shanika Wickramasinghe)
(fuente:Shanika Wickramasinghe)
4.Uso de navegadores antidetección
Para obtener resultados aún mejores, el uso de navegadores antidetección como DICloak puede cambiar las reglas del juego. Estos navegadores están diseñados para simular la actividad real del usuario enmascarando su huella digital. Al imitar el comportamiento de un usuario legítimo, los navegadores antidetección pueden evitar los desafíos comunes y las técnicas de análisis de comportamiento empleadas por Cloudflare. Esto permite que sus esfuerzos de raspado web permanezcan sin ser detectados y sean más eficientes. Además de enmascarar las huellas dactilares, DICloak también ofrece funciones de RPA (Automatización Robótica de Procesos), que permiten a su raspador automatizar tareas e interactuar con los sitios web como un usuario real. Esto hace que el scraping sea más dinámico y adaptable, lo que reduce aún más el riesgo de detección por parte de Cloudflare.
5. API de raspado web
Una forma eficaz de eludir la protección de Cloudflare es mediante el uso de una API de raspado web. Estas API están diseñadas para manejar la complejidad de la seguridad de Cloudflare por ti. Por ejemplo, ScraperAPI o Zyte pueden administrar la rotación de IP, omitir CAPTCHA y manejar desafíos de JavaScript automáticamente. En lugar de ocuparte de los detalles técnicos, simplemente puedes enviar solicitudes a la API y recibir los datos que necesitas, mientras ella se encarga de eludir Cloudflare por ti. Este método ahorra tiempo y garantiza un raspado más suave.
Código de ejemplo (ScraperAPI):
import requests
# Using ScraperAPI to request a webpage
url = "https://example.com"
api_key = "your_scraperapi_key"
response = requests.get(f"http://api.scraperapi.com?api_key={api_key}&url={url}")
# Get the response content
print(response.text)
This method simplifies the entire scraping process. You only need to provide the API key and the URL, and the API handles the Cloudflare challenges, IP rotation, and other complexities.
6.Omita la CDN de Cloudflare llamando al servidor de origen
Otro método para eludir Cloudflare es llamar directamente al servidor de origen . Cloudflare actúa como proxy, por lo que acceder al sitio a través de la CDN de Cloudflare puede desencadenar desafíos de seguridad. Sin embargo, al identificar y acceder directamente al servidor de origen (es decir, el servidor que aloja el contenido real del sitio), puedes eludir las protecciones de Cloudflare.
Para hacer esto, es posible que deba descubrir la dirección IP del servidor de origen, que a veces se puede encontrar a través de fugas de DNS o registros anteriores. Una vez que tengas la IP del servidor de origen, puedes realizar solicitudes directamente a él, evitando la capa CDN de Cloudflare.
Código de ejemplo (Obtener IP del servidor de origen):
import socket
# Get the IP address of the target domain (sometimes the origin server's IP)
hostname = "example.com"
ip_address = socket.gethostbyname(hostname)
print("Origin Server IP:", ip_address)
Using Python’s socket library, you can retrieve the IP address of the target domain. Once you have the origin server's IP, you can bypass the Cloudflare CDN layer by making direct requests to the origin server.
7.Evite la sala de espera de Cloudflare y aplique ingeniería inversa a su desafío
Cloudflare tiene una función llamada sala de espera, que a menudo se ve durante eventos de alto tráfico. Esta función puede retrasar a los usuarios y desafiarlos con tareas como CAPTCHA. Para evitar la sala de espera de Cloudflare, debes aplicar ingeniería inversa a su funcionamiento.
Un método consiste en analizar las peticiones realizadas al entrar en la sala de espera, estudiando cómo se desencadena el reto y automatizando la interacción con él. Herramientas como Fiddler o Burp Suite pueden ayudar a inspeccionar el tráfico de la red y revelar cómo funciona el desafío de Cloudflare. Una vez que realices ingeniería inversa del desafío, puedes automatizarlo para evitar esperar a que se cargue la página.
Código de ejemplo (Automatización de la interacción con Selenium):
from selenium import webdriver
from selenium.webdriver.common.by import By
# Using Selenium to load the page and wait for the challenge
driver = webdriver.Chrome(executable_path="path_to_chromedriver")
# Visit the target site
driver.get("https://example.com")
# Wait for and handle Cloudflare's JavaScript challenge
driver.implicitly_wait(10) # Wait for the page to load
driver.find_element(By.CSS_SELECTOR, "button#submit").click() # Automatically click the submit button (if any)
# Get the page content
page_content = driver.page_source
print(page_content)
# Close the browser
driver.quit()
With Selenium, you can automate interactions with Cloudflare’s waiting room by simulating user behavior like clicking buttons or waiting for JavaScript to execute. This allows your scraper to bypass Cloudflare’s challenges and access the content.
8. Omisión de CAPTCHA de Cloudflare
Un problema común al raspar sitios protegidos por Cloudflare es encontrar desafíos de CAPTCHA . Para eludir el CAPTCHA de Cloudflare, puedes utilizar servicios de resolución de CAPTCHA como 2Captcha o AntiCaptcha, que utilizan humanos reales o IA para resolver el CAPTCHA por ti. Estos servicios pueden integrarse con su raspador y omitir automáticamente las indicaciones de CAPTCHA, lo que permite que sus esfuerzos de raspado continúen sin problemas.
Sin embargo, para que este método funcione a la perfección, debe combinarlo con técnicas anti-detección como rotar IP y usar herramientas de automatización del navegador como Puppeteer para mantener su actividad similar a la humana.
Código de ejemplo (uso de 2Captcha para la resolución de CAPTCHA):
import requests
# 2Captcha API key
api_key = "your_2captcha_api_key"
site_key = "site_key_of_the_target_page"
url = "https://example.com/captcha_page"
# Request CAPTCHA challenge
captcha_response = requests.post("http://2captcha.com/in.php", data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': url,
}).json()
captcha_id = captcha_response['request']
# Get the solved CAPTCHA result
captcha_result = requests.get(f"http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}").json()
# CAPTCHA solution
captcha_solution = captcha_result['request']
# Submit the solution to the target page
response = requests.get(f"{url}?g-recaptcha-response={captcha_solution}")
print(response.text)
This code demonstrates how to send a CAPTCHA challenge to 2Captcha, receive the solution, and then submit it back to the target site. By automating CAPTCHA solving, you can continue scraping without interruptions from Cloudflare’s security.
9. Raspar la caché de Google
Si un sitio está fuertemente protegido por Cloudflare, a veces puedes eludir su seguridad raspando la caché de Google. Google a menudo almacena en caché las versiones de las páginas web a las que se puede acceder sin desencadenar los desafíos de Cloudflare.
Al buscar la URL en Google y hacer clic en el enlace almacenado en caché, puede extraer el contenido de la versión en caché en lugar del sitio en vivo. Este método no siempre funciona si la caché está desactualizada, pero es una solución útil cuando se trata de sitios que tienen una fuerte **protección de Cloudflare**.
Código de ejemplo (acceso a la caché de Google):
import requests
# Get Google cache URL
url = "https://www.example.com"
cache_url = f"http://webcache.googleusercontent.com/search?q=cache:{url}"
# Request the cached page
response = requests.get(cache_url)
# Get the cached page content
print(response.text)
This code allows you to access the Google cached version of a page. If the content is cached, you can bypass Cloudflare’s protection and scrape the page’s content without being blocked.
These methods and code examples show various techniques to bypass Cloudflare protection, including using scraping APIs, accessing the origin server, reverse-engineering waiting rooms, solving CAPTCHAs, and scraping Google cache. Each approach has its own advantages depending on the specific challenges you encounter during scraping.
Conclusión
Eludir con éxito la protección de Cloudflare es esencial para un web scraping eficiente. Mediante el uso de métodos como el raspado de API, la rotación de direcciones IP, la resolución de CAPTCHA, la simulación de comportamientos similares a los humanos y los desafíos de ingeniería inversa como las salas de espera, puedes superar las barreras que Cloudflare establece. Cada técnica proporciona una solución a diferentes aspectos de las medidas de seguridad de Cloudflare, lo que te permite raspar datos sin problemas sin ser bloqueado. Sin embargo, asegúrese siempre de que sus actividades de scraping sean éticas y cumplan con las leyes pertinentes.
 Herramientas gratuitas
Herramientas gratuitas Complemento de cookies
Complemento de cookies Generador UA
Generador UA Generador de direcciones MAC
Generador de direcciones MAC Generador de IP
Generador de IP Lista de direcciones IP
Lista de direcciones IP Generador de código 2FA
Generador de código 2FA Reloj Mundial
Reloj Mundial Cheque Anónimo
Cheque Anónimo WebRTC Leak Test
WebRTC Leak Test Generador UUID
Generador UUID Verificador de Proxy
Verificador de Proxy Verificador de anuncios de Facebook
Verificador de anuncios de Facebook Raspado web con IA
Raspado web con IA Herramientas SMM Gratis
Herramientas SMM Gratis Verificador de Sombreado de Twitter
Verificador de Sombreado de Twitter Generador UTM
Generador UTM Generador de usernames
Generador de usernames Generador de hashtags con IA
Generador de hashtags con IA