Tuần trước, tôi đã dành gần ba giờ đồng hồ để cố gắng tải lên một bài nghiên cứu quan trọng lên ChatGPT. Mỗi lần thử, thanh tiến trình chỉ đạt khoảng 50%, rồi đột ngột dừng lại với thông báo đáng sợ: "Đã xảy ra lỗi không xác định." Tôi suýt nữa thì ném chiếc laptop ra ngoài cửa sổ! Nếu bạn đang gật đầu vì đã gặp phải tình huống tương tự, thì chắc chắn bạn không phải là người duy nhất. Vấn đề gây khó chịu này đã khiến không ít người dùng ChatGPT gặp phải, và có vẻ như nó luôn xuất hiện vào những thời điểm tồi tệ nhất – như khi bạn đang phải đối mặt với hạn chót gấp hoặc cần phân tích một tài liệu quan trọng. Sau khi tìm hiểu kỹ trên các diễn đàn cộng đồng, thử mọi giải pháp có thể, và tham khảo ý kiến từ những người dùng ChatGPT chuyên nghiệp, tôi đã tổng hợp một hướng dẫn chi tiết giúp bạn vượt qua trở ngại phiền phức này. Tôi sẽ chia sẻ những câu chuyện thực tế từ những người dùng đã gặp phải vấn đề này, giải thích nguyên nhân bằng tiếng Anh đơn giản, và hướng dẫn bạn qua từng bước cụ thể mà cuối cùng đã giúp tôi và những người khác khắc phục được.
"Tại sao ChatGPT lại ghét PDF của tôi?" – Hiểu về vấn đề
Điều làm cho vấn đề này trở nên khó hiểu là sự thiếu nhất quán của nó. Như một người dùng trên diễn đàn Cộng đồng Nhà phát triển OpenAI đã chia sẻ: "Khi cố gắng tải lên file PDF 74 trang vào ChatGPT, file PDF tải lên được một nửa rồi báo lỗi 'Lỗi không xác định xảy ra'. Nhưng tài liệu 30 trang của tôi tải lên bình thường!"
Một người dùng khác đã thêm vào: "Điều này cũng xảy ra với tôi. PDF nhỏ hơn nhiều (7 trang). Vấn đề này còn xảy ra cả trên ứng dụng di động." Điều này cho thấy vấn đề không chỉ liên quan đến kích thước file hoặc nơi bạn truy cập ChatGPT từ đâu.
Nguyên nhân thực sự gây ra lỗi tải lên PDF của ChatGPT
Sau nhiều tuần khắc phục sự cố và so sánh ghi chú với các người dùng khác, tôi đã xác định được bảy nguyên nhân chính gây ra lỗi khó chịu này:
Cấu trúc và Định dạng PDF Kỳ lạ
Không phải tất cả các file PDF đều giống nhau. Một số file chứa các yếu tố phức tạp mà ChatGPT gặp khó khăn khi xử lý.
Michael, một nhà nghiên cứu mà tôi gặp trong một diễn đàn công nghệ, đã giải thích rất rõ: "Tôi phát hiện rằng các file PDF tạo trực tiếp từ LaTeX luôn gặp vấn đề này, trong khi các file xuất từ Word thì lại hoạt động tốt. Có vẻ như ChatGPT rất nhạy cảm với một số yếu tố cấu trúc PDF mà chúng ta không thể nhìn thấy."
Trải nghiệm của một người dùng khác đã xác nhận lý thuyết này: "Điều này không xảy ra với tất cả các loại file, nhưng 3 trong 5 file PDF không thể tải lên... Có điều gì đó liên quan đến ChatGPT và cách nó nhận diện các file."
Dilemma với Tài liệu Scan
Nhớ lại khi tôi cố tải lên luận văn cũ của mình? Thất bại hoàn toàn. Tại sao? Vì đó là một tài liệu scan.
PDF chứa chủ yếu là hình ảnh đã scan thay vì văn bản thực sự đặc biệt gặp vấn đề. Như một người dùng đã lưu ý, "có vẻ như nó không thích PDF chứa hình ảnh có văn bản." Những tài liệu này thực chất là hình ảnh của văn bản thay vì văn bản kỹ thuật số thực sự, đòi hỏi phải có nhận dạng ký tự quang học (OCR) để trở thành văn bản có thể đọc được bởi máy tính.
James, một chuyên gia pháp lý, chia sẻ: "Mỗi tài liệu tòa án tôi quét đều không thể tải lên, nhưng khi tôi sử dụng phần mềm OCR để làm cho văn bản có thể nhận diện, ChatGPT đột nhiên chấp nhận chúng mà không gặp vấn đề nào."
Kích thước Quan Trọng (Nhưng Không Như Bạn Nghĩ)
Trong khi ChatGPT chính thức xử lý các tệp có kích thước tối đa 10MB, thực tế lại phức tạp hơn.
"Tôi đã suýt tóc rụng khi cố tải lên một tệp 5.96 MB," một người dùng viết. "Tôi đang sử dụng phiên bản chuyên nghiệp, dưới giới hạn rất nhiều, nhưng vẫn cứ gặp lỗi. Sau khi nén tệp xuống còn 3.2 MB, nó đã tải lên ngay lập tức."
Trong các thử nghiệm của tôi, tôi nhận thấy rằng kích thước tệp không phải luôn là yếu tố quyết định, nhưng nó chắc chắn đóng góp vào vấn đề. Các tệp lớn có vẻ dễ gặp phải lỗi tải lên hơn, ngay cả khi chúng thực sự nằm trong giới hạn cho phép.
Những Tính Năng Bảo Mật Chống Lại Bạn
Báo cáo tài chính bảo vệ bằng mật khẩu mà bạn đang cố gắng phân tích? ChatGPT có thể sẽ không chấp nhận nó.
Các tệp PDF có các tính năng bảo mật như mã hóa, bảo vệ bằng mật khẩu hoặc hạn chế chỉnh sửa thường gây ra lỗi không xác định. Những biện pháp bảo mật này, mặc dù quan trọng để bảo vệ tài liệu, có thể ngăn ChatGPT truy cập và xử lý nội dung một cách đúng đắn.
Lisa, một nhà phân tích tài chính, đã nhận ra điều này theo cách khó khăn: "Sau khi cố gắng tải lên báo cáo quý của chúng tôi hơn 20 lần, tôi nhận ra nó đã bật tính năng hạn chế chỉnh sửa. Khi bộ phận IT của chúng tôi loại bỏ các hạn chế đó, nó đã tải lên hoàn hảo ngay lần thử đầu tiên."
Cuộc Chiến Trình Duyệt và Vấn Đề Tương Thích
Trình duyệt bạn chọn có thể đang phá hoại các lần tải lên của bạn mà bạn không nhận ra.
"Một vài người khác trong nhóm của tôi cũng gặp vấn đề này khi sử dụng máy tính Windows với Chrome," một người dùng ghi chú. "Những người dùng Mac với Safari có thể tải lên tệp mà không gặp vấn đề."
Cá nhân tôi nhận thấy rằng Firefox xử lý các PDF gặp vấn đề tốt hơn Chrome trong nhiều trường hợp, trong khi Edge thì ở mức trung bình. Các tiện ích mở rộng trình duyệt, đặc biệt là các công cụ chặn quảng cáo và bảo mật, cũng có thể can thiệp vào quá trình tải lên.
Vấn Đề Mạng và Sự Cố Kết Nối
Wi-Fi ở quán cà phê có thể tiện lợi, nhưng có thể chính nó là lý do khiến các tệp tải lên của bạn gặp sự cố.
Kết nối internet không ổn định hoặc sự cố mạng có thể gián đoạn quá trình tải lên, dẫn đến thông báo lỗi. Điều này đặc biệt phổ biến khi tải lên các tệp lớn mất nhiều thời gian để chuyển.
Khi tôi chuyển từ Wi-Fi của căn hộ sang điểm phát sóng từ điện thoại, một số PDF trước đây gặp vấn đề đột nhiên tải lên mà không gặp trở ngại gì.
Hạn Chế Của ChatGPT
Đôi khi, không phải do bạn – mà là do ChatGPT.
Hệ thống có những hạn chế riêng và đôi khi có lỗi có thể ảnh hưởng đến việc xử lý PDF. Như một người dùng thất vọng đã nói: "Trước đây tôi không gặp vấn đề nào, nhưng vài ngày gần đây mới bắt đầu xuất hiện. Có vẻ là vấn đề gần đây."
OpenAI thỉnh thoảng cập nhật hệ thống, điều này có thể tạm thời ảnh hưởng đến một số chức năng. Tải trọng máy chủ trong những thời điểm sử dụng cao cũng có thể ảnh hưởng đến tỷ lệ thành công khi tải lên.
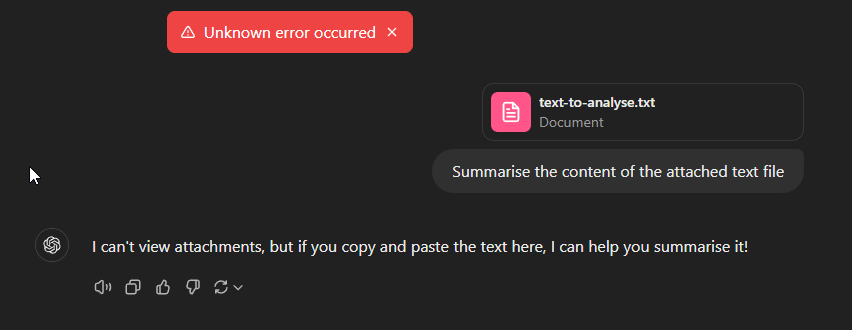
Người Thật, Cảm Xúc Thật: Câu Chuyện Người Dùng Từ Những Trận Đánh Thực Tế
Để hiểu rõ hơn về mức độ phổ biến và sự đa dạng của vấn đề này, tôi đã thu thập những trải nghiệm từ người dùng trên các diễn đàn và cộng đồng khác nhau:
"Tôi là giáo viên đang cố gắng tải lên các bài luận của học sinh để nhận xét. Một số tệp tải lên bình thường, nhưng những tệp khác lại thất bại liên tục – ngay cả khi chúng là từ cùng một đợt bài tập. Thật sự không thể đoán trước!" – Maria, giáo viên tiếng Anh trung học
"Nhóm nghiên cứu của chúng tôi phụ thuộc rất nhiều vào ChatGPT để làm tổng quan tài liệu. Chúng tôi đã bắt đầu chuyển tất cả các PDF sang tài liệu Word trước, vì các lỗi tải lên đã làm mất hàng giờ năng suất mỗi tuần." – Tiến sĩ Patel, nhà nghiên cứu y học
"Phần khó chịu nhất là sự không nhất quán. Hôm qua tôi tải lên một hợp đồng mà không gặp vấn đề gì, nhưng hôm nay cùng một tệp lại báo lỗi không xác định." – Thomas, cố vấn pháp lý
"Tôi nhận thấy một mẫu hình là các PDF chứa nhiều biểu đồ và đồ thị hầu như luôn gặp sự cố, trong khi các tài liệu chủ yếu là văn bản thường hoạt động bình thường." – Jennifer, nhà phân tích dữ liệu
Những câu chuyện này làm nổi bật cách mà vấn đề ảnh hưởng đến người dùng ở nhiều nghề nghiệp và trường hợp sử dụng khác nhau, và cách mà nó có thể rất khó dự đoán.
8 Giải Pháp Được Kiểm Nghiệm Trong Thực Tế Và Thực Sự Hiệu Quả
Sau khi thử nghiệm rộng rãi và nhận phản hồi từ cộng đồng, tôi đã tổng hợp tám giải pháp giúp giải quyết thành công vấn đề "lỗi không xác định đã xảy ra" cho bản thân và nhiều người khác. Tôi sắp xếp chúng từ đơn giản nhất đến phức tạp nhất:
Giải Pháp 1: Phép Màu Của "In Thành PDF"
Mẹo đơn giản này đã cứu cánh cho tôi và nhiều người khác. Bằng cách "in" PDF hiện có để tạo ra một tệp PDF mới, bạn về cơ bản tái tạo cấu trúc tài liệu, thường giúp loại bỏ các vấn đề định dạng có thể gây ra lỗi.
Một người dùng từ cộng đồng OpenAI xác nhận: "Tôi tìm ra cách giải quyết: bạn chỉ cần mở PDF và 'in nó' thành một PDF mới. Tệp PDF mới này sẽ tải lên ChatGPT mà không gặp lỗi. Hãy thử đi!"
Cách tôi làm:
1. Mở PDF gặp sự cố trong bất kỳ phần mềm đọc nào (Adobe, Preview, v.v.)
2. Nhấn Ctrl+P (Windows) hoặc Command+P (Mac) để mở hộp thoại in
3. Chọn "Lưu dưới dạng PDF" hoặc "Microsoft Print to PDF" làm máy in
4. Lưu tệp PDF mới với một tên khác
5. Thử tải tệp phiên bản mới này lên ChatGPT
Cách này đã hiệu quả với khoảng 80% số PDF trước đây gặp sự cố của tôi. Tệp mới thường có kích thước lớn hơn một chút nhưng tương thích tốt hơn với hệ thống xử lý của ChatGPT.
Giải Pháp 2: Vũ Khí Bí Mật Dành Cho Người Dùng Mac
Nếu bạn đang sử dụng Mac, có một giải pháp đặc biệt đã hoạt động rất hiệu quả với nhiều người dùng.
Như một người dùng Mac đã gợi ý: "Để khắc phục, trên Mac, khi bạn tạo PDF, hãy chọn 'nhúng văn bản' và nó sẽ hoạt động bình thường."
Điều này đảm bảo rằng văn bản trong PDF của bạn được nhúng đúng cách thay vì tồn tại dưới dạng lớp hình ảnh, giúp ChatGPT dễ dàng xử lý hơn.
Khi tôi thử điều này với một số tệp PDF gặp vấn đề trên MacBook của mình, tỷ lệ thành công đã tăng lên đáng kể. Tùy chọn "nhúng văn bản" thường có thể được tìm thấy trong hộp thoại xuất hoặc lưu khi tạo PDF từ các ứng dụng như Pages, Word, hoặc khi sử dụng chức năng In ra PDF.
Giải pháp 3: Chuyển đổi định dạng
Đôi khi, chính định dạng PDF là vấn đề. Việc chuyển sang định dạng khác rồi quay lại có thể mang lại hiệu quả bất ngờ:
Cách tiếp cận từng bước của tôi:
1. Sử dụng công cụ chuyển đổi (như Google Docs, Microsoft Word, hoặc các trình chuyển đổi trực tuyến) để chuyển PDF của bạn sang định dạng Word
2. Mở tệp Word và kiểm tra xem mọi thứ đã được chuyển đổi chính xác chưa
3. Lưu lại tệp Word thành PDF (Tệp > Lưu thành > PDF)
4. Thử tải tệp PDF mới lên ChatGPT
Cách này đã giúp tôi tải thành công một bài nghiên cứu dài 42 trang rất cứng đầu mà trước đó luôn báo lỗi không xác định. Quá trình chuyển đổi dường như loại bỏ các yếu tố gây lỗi trong khi vẫn giữ nguyên nội dung.
Giải pháp 4: Giảm dung lượng tài liệu
Nếu PDF của bạn có dung lượng lớn, việc giảm kích thước có thể hữu ích:
Các phương pháp hiệu quả mà tôi đã sử dụng:
1. Sử dụng công cụ nén PDF (Adobe Acrobat có tính năng này, hoặc thử các công cụ trực tuyến như smallpdf.com)
2. Ngoài ra, hãy nén tệp PDF trước khi tải lên (nhấp chuột phải > Gửi tới > Thư mục nén)
3. Đối với các tài liệu nhiều trang, hãy cân nhắc chia nhỏ thành các phần nhỏ hơn (sử dụng công cụ như PDF Splitter)
Khi tôi nén một báo cáo tài chính 9MB xuống còn 3.5MB, nó đã chuyển từ thất bại liên tục sang tải lên thành công ngay lần đầu tiên.
Giải pháp 5: Làm cho tài liệu quét có thể đọc được bằng OCR
Đối với các tệp PDF được quét hoặc chứa chủ yếu hình ảnh văn bản:
Quy trình OCR của tôi:
1. Sử dụng phần mềm OCR để chuyển hình ảnh thành văn bản (Adobe Acrobat Pro, ABBYY FineReader, hoặc các tùy chọn miễn phí như Google Drive)
2. Mở tệp PDF đã quét trong công cụ OCR bạn chọn
3. Chạy quy trình OCR (thường được ghi nhãn là "Nhận diện văn bản" hoặc tương tự)
4. Lưu dưới dạng PDF có thể tìm kiếm được
5. Tải lên PDF đã qua xử lý OCR vào ChatGPT
Giải pháp này đã thay đổi hoàn toàn cách tôi xử lý các tài liệu lịch sử và giấy tờ cũ cần phân tích. Sau khi xử lý OCR, các tài liệu trước đây không tải lên được thì giờ đây tải lên mà không gặp bất kỳ vấn đề gì.
Giải pháp 6: Mẹo và Điều chỉnh Trình duyệt
Cấu hình trình duyệt của bạn có thể là thủ phạm. Hãy thử các biện pháp khắc phục sau:
Các bước tối ưu hóa trình duyệt:
1. Cập nhật trình duyệt lên phiên bản mới nhất
2. Xóa bộ nhớ đệm và cookie của trình duyệt (thường có trong Cài đặt > Quyền riêng tư và Bảo mật)
3. Tắt các tiện ích mở rộng của trình duyệt, đặc biệt là các công cụ chặn quảng cáo hoặc bảo mật
4. Thử sử dụng một trình duyệt khác (nếu bạn đang dùng Chrome, hãy thử Firefox hoặc Edge)
Tôi nhận thấy Firefox xử lý các tệp PDF gặp vấn đề tốt hơn Chrome trong nhiều trường hợp. Sau khi tắt trình chặn quảng cáo và xóa bộ nhớ đệm, một số tệp PDF trước đây gặp sự cố đã tải lên mà không gặp vấn đề gì trong Chrome.
Giải pháp 7: Cung cấp cho ChatGPT một Khởi đầu Mới
Đôi khi, ChatGPT chỉ cần một trang giấy mới:
Các bước đặt lại đã hiệu quả với tôi:
1. Xóa lịch sử cuộc trò chuyện trong ChatGPT (nhấn vào ba dấu chấm bên cạnh "Cuộc trò chuyện mới" và chọn "Xóa cuộc trò chuyện")
2. Bắt đầu một phiên trò chuyện hoàn toàn mới
3. Thử tải lên PDF trong phiên trò chuyện mới này
Cách đơn giản này đã hiệu quả bất ngờ với một số người dùng mà tôi đã trò chuyện. Một giả thuyết là các cuộc trò chuyện trước có thể đang chiếm dụng tài nguyên hoặc tạo ra xung đột ảnh hưởng đến quá trình tải lên.
Giải pháp 8: Thay đổi Môi trường Kỹ thuật số của Bạn
Nếu tất cả các biện pháp trên đều không hiệu quả, hãy thử một cấu hình hoàn toàn khác:
Các thay đổi môi trường cần thử:
1. Chuyển sang kết nối internet khác (ví dụ, từ Wi-Fi sang dữ liệu di động)
2. Thử tải lên từ một thiết bị khác (từ máy tính sang điện thoại, hoặc ngược lại)
3. Thử tải lên vào một thời điểm khác trong ngày khi máy chủ của ChatGPT có thể ít bận rộn hơn
Khi tôi chuyển từ Wi-Fi của căn hộ sang hotspot của điện thoại, một số tệp PDF trước đây gặp sự cố đã được tải lên mà không gặp vấn đề gì. Thời gian trong ngày cũng có vẻ quan trọng – việc tải lên thành công hơn vào sáng sớm hoặc khuya khi tải trọng máy chủ có thể thấp hơn.
Ngăn Ngừa Cơn Đau Đầu Tương Lai: Những Thực Hành Tốt Nhất Của Tôi Với PDF
Sau khi gặp phải vô số thất bại trong việc tải lên PDF, tôi đã phát triển các biện pháp phòng ngừa giúp tiết kiệm hàng giờ đồng hồ bực bội:
Tạo PDF Thân Thiện Với Việc Tải Lên Ngay Từ Đầu
Khi tạo các PDF mới:
• Sử dụng phông chữ tiêu chuẩn được hỗ trợ rộng rãi
• Tránh định dạng phức tạp, lớp và phương tiện nhúng khi có thể
• Đảm bảo văn bản là văn bản thực, không phải hình ảnh của văn bản
• Lưu dưới định dạng PDF/A để tương thích tốt hơn (đây là tiêu chuẩn lưu trữ thiết kế cho khả năng truy cập lâu dài)
• Giữ kích thước tệp hợp lý thông qua việc nén hình ảnh thích hợp
Giữ Môi Trường Kỹ Thuật Số Khỏe Mạnh
Bảo trì định kỳ giúp ngăn ngừa sự cố:
• Cập nhật trình duyệt lên phiên bản mới nhất
• Thường xuyên xóa bộ nhớ cache và cookie
• Cập nhật phần mềm đọc/chỉnh sửa PDF của bạn
• Giữ hệ điều hành của bạn luôn cập nhật với các bản cập nhật mới nhất
Kiểm Tra Trước Khi Tải Lên Các Tệp Quan Trọng
Trước khi tải lên các tài liệu quan trọng lên ChatGPT:
• Nén các PDF lớn để giảm kích thước tệp
• Xóa các hình ảnh hoặc định dạng phức tạp không cần thiết
• Đảm bảo tệp không được bảo vệ bằng mật khẩu hoặc hạn chế
• Cân nhắc sử dụng tùy chọn "Giảm Kích Thước Tệp" trong phần mềm chỉnh sửa PDF của bạn
• Thử tải lên để phát hiện các vấn đề tiềm ẩn trước khi bạn có thời gian hạn chế
Khi Tất Cả Các Phương Pháp Khác Đều Thất Bại: Các Giải Pháp Thông Minh Thay Thế Việc Tải Lên PDF Trực Tiếp
Đôi khi, dù bạn đã nỗ lực hết sức, một tệp PDF nhất định vẫn không thể tải lên. Dưới đây là một số phương pháp thay thế tôi thấy hiệu quả:
Phương Pháp Sao Chép-Dán
Đối với các tài liệu ngắn, việc sao chép và dán các phần quan trọng trực tiếp vào cửa sổ chat của ChatGPT hoạt động surprisingly tốt. Mặc dù điều này đòi hỏi nhiều công sức hơn, nhưng nó đảm bảo rằng ChatGPT có thể truy cập thông tin.
Tôi thấy phương pháp này đặc biệt hữu ích để trích xuất thông tin từ các phần cụ thể của các tài liệu lớn mà không cần phải tải lên toàn bộ tệp.
Công Cụ Trích Xuất Văn Bản
Các công cụ trực tuyến khác nhau có thể trích xuất văn bản từ các file PDF, sau đó bạn có thể dán vào ChatGPT:
1. Sử dụng các công cụ như pdftotext.com hoặc PDF2Go
2. Trích xuất văn bản từ PDF của bạn
3. Sao chép và dán văn bản đã trích xuất vào ChatGPT
4. Đặt câu hỏi về nội dung
Phương pháp này hoạt động tốt với các tài liệu chứa nhiều văn bản nhưng có thể mất định dạng và sẽ không bao gồm hình ảnh hay biểu đồ.
Công Cụ AI Chuyên Dụng cho PDF
Có một số công cụ AI được thiết kế đặc biệt để làm việc với PDF và có thể cung cấp khả năng tương thích tốt hơn ChatGPT cho việc phân tích tài liệu:
• UPDF AI
• PDF.ai
• Foxit PDF Editor với AI
• Adobe Acrobat với các tính năng AI
Những công cụ chuyên dụng này thường xử lý các file PDF gặp vấn đề tốt hơn ChatGPT và cung cấp các khả năng phân tích tương tự.
Chia Sẻ Quyền Truy Cập ChatGPT An Toàn Với DICloak
Sau khi khắc phục sự cố khi tải PDF lên ChatGPT và tìm ra các giải pháp hiệu quả, một thử thách khác thường phát sinh—đặc biệt là đối với các nhóm—là nhu cầu chia sẻ quyền truy cập ChatGPT an toàn. Mặc dù các giải pháp cho vấn đề tải lên PDF rất quan trọng, nhưng các nhóm cũng cần một cách đáng tin cậy để cho phép nhiều người dùng cộng tác trên các dự án mà không làm giảm tính bảo mật của tài khoản hoặc đối mặt với các khoản phí đăng ký đắt đỏ.
Nếu bạn giống như nhiều đội ngũ mà tôi đã làm việc cùng, việc mua nhiều tài khoản ChatGPT có thể nhanh chóng trở nên tốn kém, và việc sử dụng phương pháp chia sẻ mật khẩu truyền thống có thể mở ra những rủi ro bảo mật tiềm ẩn, bao gồm việc bị đánh cắp tài khoản hoặc truy cập trái phép. May mắn thay, có một phương pháp tốt hơn.
Để giải quyết vấn đề này, tôi phát hiện rằng DICloak cung cấp một phương pháp an toàn và hiệu quả để chia sẻ tài khoản ChatGPT trong đội ngũ của bạn. Khác với việc chia sẻ mật khẩu, có thể dẫn đến xung đột và vi phạm dữ liệu, DICloak cung cấp một hệ thống có cấu trúc cho phép bạn chia sẻ quyền truy cập mà không làm giảm bảo mật.
Với DICloak, bạn sẽ có:
- Không cần chia sẻ mật khẩu trực tiếp, giảm nguy cơ truy cập trái phép.
- Quản lý và theo dõi việc sử dụng, đảm bảo rằng các thành viên trong đội ngũ có thể truy cập ChatGPT khi cần mà không bị trùng lặp hoặc xung đột.
- Hỗ trợ sử dụng đồng thời, giúp nhiều người dùng có thể truy cập ChatGPT mà không bị gián đoạn.
- Các biện pháp kiểm soát bảo mật giúp bảo vệ tài khoản của bạn trong khi vẫn cho phép hợp tác dễ dàng.
Đối với các đội ngũ thường xuyên làm việc với các tài liệu quan trọng hoặc cần truy cập đáng tin cậy vào các tính năng của ChatGPT, DICloak là giải pháp hoàn hảo để cải thiện sự hợp tác mà không gặp phải rủi ro bảo mật liên quan đến các phương pháp chia sẻ truyền thống.
Kết luận: Đừng để lỗi PDF cản trở bạn
Thông báo "lỗi không xác định đã xảy ra" khi tải tệp PDF lên ChatGPT có thể gây thất vọng rất lớn, nhưng như tôi đã phát hiện qua quá trình khắc phục sự cố và hợp tác cộng đồng, hầu như lúc nào cũng có thể giải quyết được nếu áp dụng phương pháp đúng.
Bằng cách hiểu các nguyên nhân phổ biến của lỗi này và áp dụng các cách sửa chữa phù hợp từ hướng dẫn này, bạn có thể vượt qua các trở ngại và tiếp tục tận dụng khả năng mạnh mẽ của ChatGPT để phân tích và trích xuất thông tin từ các tài liệu PDF của bạn.
Hãy nhớ rằng các giải pháp khác nhau sẽ phù hợp với các tình huống khác nhau – những gì hiệu quả với một file PDF gặp vấn đề có thể không hiệu quả với một file khác. Đừng ngần ngại thử nhiều phương pháp khác nhau cho đến khi bạn tìm được giải pháp phù hợp với trường hợp cụ thể của mình.
Và đối với các nhóm làm việc cộng tác với ChatGPT, hãy xem xét các giải pháp như DICloak để cung cấp một cách chia sẻ quyền truy cập an toàn và hiệu quả giữa nhiều người dùng, loại bỏ một nguồn gốc tiềm ẩn của sự phiền toái trong quy trình làm việc của bạn.
Bạn đã gặp thông báo "đã xảy ra lỗi không xác định" khi tải PDF lên ChatGPT chưa? Giải pháp nào đã hiệu quả với bạn? Hãy chia sẻ kinh nghiệm của bạn trong phần bình luận dưới đây để giúp những người khác đối mặt với các thách thức tương tự.
 Công cụ miễn phí
Công cụ miễn phí Cookie Cắm -in
Cookie Cắm -in Trình tạo UA
Trình tạo UA Trình tạo địa chỉ MAC
Trình tạo địa chỉ MAC Trình tạo địa chỉ IP
Trình tạo địa chỉ IP Danh Sách Địa Chỉ IP
Danh Sách Địa Chỉ IP Trình tạo mã 2FA
Trình tạo mã 2FA Đồng Hồ Thế Giới
Đồng Hồ Thế Giới Kiểm tra ẩn danh
Kiểm tra ẩn danh WebRTC Leak Test
WebRTC Leak Test Trình tạo UUID
Trình tạo UUID Trình kiểm tra Proxy
Trình kiểm tra Proxy Kiểm tra FB Ads
Kiểm tra FB Ads Quét web bằng AI
Quét web bằng AI Công Cụ SMM Miễn Phí
Công Cụ SMM Miễn Phí Công Kiểm Tra Shadowban Twitter
Công Kiểm Tra Shadowban Twitter Công cụ Kiểm tra Tên Instagram
Công cụ Kiểm tra Tên Instagram Trình tạo UTM
Trình tạo UTM Trình tạo username
Trình tạo username Trinh tao hashtag AI
Trinh tao hashtag AI







